via <a href="https://www.sarasanalytics.net/2026/07/july-2026-sp-api-release.html">Ecommerce Data Analytics</a>
Wednesday, July 29, 2026
Five New Carriers Available in Amazon Buy Shipping
via <a href="https://www.sarasanalytics.net/2026/07/five-new-carriers-available-in-amazon.html">Ecommerce Data Analytics</a>
Monday, July 27, 2026
AWS Weekly Roundup: Local Zone in Athens, Claude Opus 5 on AWS, Lambda durable execution for .NET, and more (July 27, 2026)
Last week I had the privilege of spending three days in São Paulo with technical builders from across Latin America, brought together for a regional tech event full of deep-dive sessions, hands-on workshops, and conversations with customers and partners. What struck me most wasn’t any single session, it was the energy of a technical community that so rarely gets to be in the same room. People traded architecture ideas over coffee, sketched out solutions on whiteboards, and left with a longer list of things to try than they arrived with. It’s a good reminder that, for all the tooling we build, the community around it is what makes the technology stick.
That community spirit connects nicely to the week’s biggest infrastructure news, which is all about bringing AWS closer to where builders actually are.

Now, let’s get into this week’s AWS news…
Headlines
AWS Local Zone in Athens, Greece: AWS has opened a new Local Zone in Athens, Greece, the second Local Zone in EMEA with support for Amazon S3 and Amazon EBS Local Snapshots, so you can store and process data within Greece to help meet local data residency requirements. The Athens Local Zone supports Amazon EC2 (C7i, M7i, and R7i instances), Amazon S3 with the One Zone-Infrequent Access storage class, Amazon EBS, and Amazon ECS.

AWS Local Zones place AWS infrastructure much closer to large population and industry hubs, enabling applications that require single-digit millisecond latency, such as real-time gaming, media production, and financial services, to run where end users actually are. For builders in Greece, you can now run latency-sensitive workloads locally while connecting seamlessly to the nearest AWS Region for services that don’t require low latency, giving you the flexibility to architect hybrid, latency-optimized applications without managing your own data center infrastructure. To learn more, visit AWS Global Infrastructure and Sustainability Blog post.
Last week’s launches
Here are some launches and updates from this past week that caught my attention:
- Claude Opus 5 on AWS: You can use Anthropic’s Claude Opus 5, the most advanced Opus model yet, matching Claude Fable 5’s top-tier intelligence in many domains at Opus-tier pricing. Amazon Bedrock offers Claude Opus 5 with zero data retention (ZDR) enabled by default, giving you Opus’ top-tier intelligence while meeting your data governance requirements unlike Claude Fable 5. You have two ways to access Claude Opus 5: Amazon Bedrock and Claude Platform on AWS. To learn more, visit the deep dive blog post.
- AWS Lambda durable execution SDK for .NET is now generally available: You can now build resilient, long-running workflows in C# using Lambda durable functions, without implementing custom progress tracking or integrating an external orchestration service. The SDK is a natural fit for multi-step applications like payment processing pipelines, AI agent orchestration, and human-in-the-loop approvals, it checkpoints progress automatically and can pause execution for up to a year. If you’re a .NET developer building serverless workflows, this removes a lot of the plumbing you used to write by hand.
- Amazon Bedrock AgentCore now delivers unified observability with traces and logs in a single log group: Amazon Bedrock AgentCore now delivers agent traces and prompts to the same Amazon CloudWatch log group as your agent’s logs. Previously, telemetry was split across destinations, trace spans went to a shared log group while prompts, inputs, and outputs went to a separate one, so debugging a single agent invocation meant searching in multiple places. You can now debug an invocation in one place, and apply fine-grained access control and customer-managed key (CMK) encryption at the individual agent level.
- Amazon Connect delivers more natural agentic voice experiences: Amazon Connect now supports more natural, human-sounding agentic voice experiences across 50+ languages, including Portuguese, Spanish, French, Italian, Japanese, Korean, and Thai, with over 100 new voice options and conversational improvements that make AI interactions sound more fluid. Connect’s agentic self-service lets AI agents understand, reason, and take action across voice and digital channels, adapting to a customer’s tone and sentiment. You can now build contact center experiences that feel natural to callers in far more of the languages your customers actually speak.
- Amazon SageMaker Unified Studio now supports Amazon OpenSearch: You can now query and analyze your search and log analytics data from Amazon OpenSearch directly alongside other data assets in Amazon SageMaker Unified Studio. With this connection, you can combine operational search data in OpenSearch with data from sources like Amazon Redshift, Amazon S3, and relational databases, all within a single, governed environment. It’s especially useful when you need to correlate analytical and operational workloads, such as joining application logs with transactional data to uncover insights.
- Amazon CloudWatch announces coding agent insights: Amazon CloudWatch now gives engineering leaders visibility into how AI coding tools are driving value across their organization. Coding agent insights integrates with the Claude apps gateway for AWS to collect telemetry from Claude Code without additional instrumentation, and also supports agents like Codex and GitHub Copilot. As teams scale AI coding adoption, you can now measure the return on that investment with metrics built on OpenTelemetry, no custom instrumentation required.
For a full list of AWS announcements, be sure to keep an eye on the What’s New with AWS page.
Other AWS news
Here are some additional posts and resources that you might find interesting:
- Evaluating AI Agents: A production blueprint with Strands and AgentCore: A practical guide to evaluating AI agents before and after they reach production, using Strands Agents and Amazon Bedrock AgentCore. If you’re moving agents from prototype to production, this post is a great companion to the AgentCore observability update above, it walks through how to measure agent quality systematically rather than by gut feel.
- Building multi-region resiliency for AWS CloudFormation custom resource deployment: Learn how to architect CloudFormation custom resources for multi-region resiliency, so your infrastructure-as-code deployments stay reliable even when a single Region has issues.
- Introducing Amazon Simple Email Service (SES) pricing plans: Amazon SES now offers pricing plans that give you more predictable costs as your email volume grows. If you send at scale, this could simplify your billing significantly.
Upcoming AWS events
Check your calendar and sign up for upcoming AWS events:
- AWS Summits: AWS Summits are free events that bring the cloud and AI community together to connect, learn, and explore the latest technologies. Browse the full calendar to find a Summit near you in the second half of 2026.
- AWS Community Days: Community-led conferences where content is planned, sourced, and delivered by community leaders. If you’re in Latin America, don’t miss AWS Community Day Belo Horizonte on August 22, registration is open at awscommunityday.com.br.
Join the AWS Builder Center to connect with builders, share solutions, and access content that supports your development. Browse here for upcoming AWS-led in-person and virtual events and developer-focused events.
That’s all for this week. Check back next Monday for another Weekly Roundup!
This post is part of our Weekly Roundup series. Check back each week for a quick roundup of interesting news and announcements from AWS!
from AWS News Blog https://ift.tt/67MGjnO
via IFTTT
Monday, July 20, 2026
AWS Weekly Roundup: One-click Lambda setup prompt, OpenAI GPT-5.6 models on Bedrock, and more (July 20, 2026)
Last week, my team visited Seoul to meet AWS Korea User Group (AWSKRUG) leaders. AWSKRUG is the largest cloud developer community in Korea, with 20 meetup groups organized by topic and area that collectively host over 100 events each year, primarily in Seoul.
My team regularly visits countries across the Asia-Pacific region, listens to feedback from user group leaders, and works to support their communities. At this meeting, leaders honestly shared what they did well in the first half of the year, what needs improvement, and what they asked of AWS Developer Experience team. We also enjoyed a pleasant conversation during our Chimaek time together.

Now, let’s take a closer look at key launches of last week.
A one-click Lambda setup prompt for coding agents caught my eye most last week. This prompt configures your agent with AWS Serverless skills and the Serverless Model Context Protocol (MCP) server, embedding serverless best practices from the start. This prompt references the Lambda agent setup guide, which includes installation commands for Claude Code, Kiro, Cursor, GitHub Copilot, Codex, Devin Desktop, and OpenCode.
To get started, choose the Copy agent prompt button on the Lambda console screen or copy fetch https://docs.aws.amazon.com/lambda/latest/dg/samples/aws-lambda-agent-setup.md directly, and paste this URL in your preferred AI agent.
You can also use Agent Toolkit for AWS to give your coding agent current AWS knowledge and safe resource access. Use fetch https://raw.githubusercontent.com/aws/agent-toolkit-for-aws/refs/heads/main/setup-instructions/setup.md for installing AWS MCP Server.
Last week’s launches
Here are last week’s launches that caught my attention:
- OpenAI GPT-5.6 Sol, Terra, and Luna on Amazon Bedrock: You can use the smartest family of models from OpenAI yet on Bedrock’s next-generation inference engine built for high performance, security, and reliability. The three models span capability tiers from flagship reasoning (Sol) to balanced performance (Terra) to fast, cost-efficient inference (Luna), all accessible through the Responses API on Amazon Bedrock.
- Same-day transitions to Amazon S3 Standard-IA and S3 One Zone-IA: You can now transition objects to S3 Standard-Infrequent Access (S3 Standard-IA) and S3 One Zone-Infrequent Access (S3 One Zone-IA) as soon as the day they are created, without the previous 30-day minimum retention period in S3 Standard. These storage classes offer up to 40% lower storage costs than S3 Standard while still providing millisecond access when needed, making them ideal for backups, log analytics, and compliance workloads where data becomes cold within hours or days.
- Self-managed code storage on AWS Lambda: With self-managed Amazon S3 buckets for code storage, you can reference source code directly from your own S3 buckets without Lambda creating intermediate copies. This eliminates code storage limits and reduces function activation time after function creates and updates by removing the copy step.
- Importing users with password hashes on Amazon Cognito: You can now import users with password hashes in CSV user imports. Previously, imported users had to reset their passwords on first sign-in. Now, you can include password hashes in the CSV import, enabling users to sign in immediately with their existing credentials. When creating a CSV import, you specify the password hashing algorithm used by your source system.
For a full list of AWS announcements, be sure to keep an eye on the What’s New with AWS page.
Additional updates
Here are some additional news items that you might find interesting:
- Amazon SQS turns 20: Two decades of reliable messaging at scale: When Amazon SQS launched publicly in July 2006, it made this pattern available to every AWS customer. Twenty years later, that core function, decoupling producers from consumers, remains the reason customers use SQS. Let’s look back important milestones after Jeff’s 15th anniversary post.
- Open Protocols with the Strands Agents SDK: Learn how open AI protocols such as MCP, A2A, UTCP, AG-UI, and x402 work together using Strands Agents SDK for building AI agents as an example implementation, though the patterns apply to any agent framework.
- Open source Bulk Executor for Amazon DynamoDB: Performing bulk operations against all items in a DynamoDB table has historically required custom coding. The Bulk Executor for DynamoDB simplifies bulk tasks like these. You can use this feature to invoke commands like
count,find,delete, orupdate. No coding is required, even when running at large scale. - Transform AWS Support Case Workflows with Kiro CLI: Explore how Kiro CLI’s MCP integration accelerates support case workflows by combining investigation, documentation lookup, and case creation into a single conversational interface across three real-world scenarios: AWS Glue job failures, AWS Lambda cold start investigation, and AWS WAF false positive analysis.
For a full list of AWS blog posts, be sure to keep an eye on the AWS Blogs page.
Learn more about AWS, browse and join upcoming AWS-led in-person and virtual events, startup events, and developer-focused events including AWS Summits. Join the AWS Builder Center to connect with builders, share solutions, and access content that supports your development.
Finally, some customers experienced an issue with Cost Explorer displaying inaccurate estimated billing data in last weekend. They may have received erroneous budget and cost anomaly detection alerts, and observed inflated estimated cost and usage data. The issue has been resolved, and all AWS services are operating normally. We apologize for the concern this incident caused our customers and are conducting a thorough retrospective to prevent events like this from reoccurring, as well as improving our response when billing incidents occur. For more information, visit the AWS Health Dashboard.
That’s all for this week. Check back next Monday for another Weekly Roundup!
— Channy
from AWS News Blog https://ift.tt/n6yONH8
via IFTTT
Wednesday, July 15, 2026
SP-API Updates: Listings Items API adds multi-marketplace support and July listing attribute & enumeration updates
via <a href="https://www.sarasanalytics.net/2026/07/sp-api-updates-listings-items-api-adds.html">Ecommerce Data Analytics</a>
Monday, July 13, 2026
Amazon SQS turns 20: Two decades of reliable messaging at scale
On July 13, 2006, we launched Amazon Simple Queue Service (Amazon SQS) as one of the first three services available to customers, alongside Amazon EC2 and Amazon S3. We had learned firsthand that distributed systems need a reliable way to pass messages between components without creating tight dependencies. If one service called another directly and that service was slow or unavailable, failures cascaded through the entire system. Message queuing solved this by letting services communicate asynchronously: a producer could drop a message into a queue and move on, while a consumer picked it up when ready. This approach kept individual service failures from affecting the rest of the system.
When Amazon SQS launched publicly in July 2006, it made this pattern available to every AWS customer. Twenty years later, that core function, decoupling producers from consumers, remains the reason customers use SQS. The scale, performance, and operational controls around it look very different now though.
Jeff Barr covered the first 15 years of SQS milestones in his 15th anniversary post, from the original 8 KB message limit in 2006 through FIFO queues, server-side encryption, and Lambda integration. Over the last five years, we have continued to scale SQS, added stronger security defaults, and introduced new capabilities that address increasingly complex workload patterns.
Key milestones between 2021 and 2026
High throughput mode for FIFO queues (2021): In May 2021, we launched general availability of high throughput mode for FIFO queues, supporting up to 3,000 transactions per second (TPS) per API action, a tenfold increase over the previous limit. We continued raising this ceiling over the following two years: to 6,000 TPS in October 2022, to 9,000 TPS in August 2023, and to 18,000 TPS in October 2023, before reaching 70,000 TPS per API action in select Regions by November 2023.
Server-side encryption with SSE-SQS (2021): In November 2021, we introduced server-side encryption with Amazon SQS-managed encryption keys (SSE-SQS), giving customers an encryption option that required no key management. In October 2022, we made SSE-SQS the default for all newly created queues, so customers no longer needed to explicitly enable it.
Dead-letter queue redrive enhancements (2021): We progressively expanded how customers recover unconsumed messages from dead-letter queues. In December 2021, we added DLQ redrive to source queue directly in the SQS console. In June 2023, we extended this capability to the AWS SDK and CLI through new APIs, including StartMessageMoveTask, CancelMessageMoveTask, and ListMessageMoveTasks. In November 2023, we added redrive support for FIFO queues.
Attribute-based access control, ABAC (2022): In November 2022, we introduced ABAC, giving customers the ability to configure access permissions based on queue tags rather than maintaining static policies as resources scaled.
JSON protocol support (2023): In November 2023, we added support for the JSON protocol in the AWS SDK, reducing end-to-end message processing latency by up to 23% for a 5 KB payload and lowering client-side CPU and memory usage.
Amazon EventBridge Pipes console integration (2023): We added the ability to connect a queue directly to EventBridge Pipes from the SQS console, routing messages to a broad range of AWS service targets without writing custom integration code.
Extended Client Library for Python (2024): We brought the Extended Client Library, previously available for Java, to Python developers, allowing messages up to 2 GB to be sent through SQS by storing the payload in Amazon S3 and passing a reference through the queue.
FIFO in-flight message limit increase (2024): We increased the in-flight message limit for FIFO queues from 20,000 to 120,000 messages, so consumers can process significantly more messages concurrently without being constrained by the previous ceiling.
Fair queues for multi-tenant workloads (2025): We introduced fair queues to mitigate the noisy neighbor problem in multi-tenant standard queues. By including a message group ID when sending messages, customers can prevent a single tenant from delaying message delivery for others, without any changes required on the consumer side.
1 MiB maximum message payload size (2025): We increased the maximum message payload from 256 KiB to 1 MiB for both standard and FIFO queues, helping customers send larger messages without offloading data to external storage. AWS Lambda event source mapping for SQS was updated in parallel to support the new payload size.
The constant underneath the change
Despite two decades of feature additions, the fundamental use case for SQS has not shifted. Customers use it to decouple services, buffer bursts of traffic, and build systems that stay resilient when individual components fail. That same pattern now extends to AI workloads. Customers use SQS queues to buffer requests to large language models, manage inference throughput, and coordinate communication between autonomous AI agents operating as independent services. For an example of this architecture in practice, read Creating asynchronous AI agents with Amazon Bedrock.
To learn more about Amazon SQS, visit the Amazon SQS product page, review the developer guide, or explore recent updates on the AWS Blogs.
— Esrafrom AWS News Blog https://ift.tt/XEmtf6b
via IFTTT
AWS Weekly Roundup: AWS Builder Center at 1 year, Network Scanning in Security Hub, Loom for AWS, and more (July 13, 2026)
AWS Builder Center turned one year old last week. Launched on July 9, 2025, the platform has grown from a community hub with Wishlist voting, community profiles, and a toolbox into a full ecosystem with sandbox environments, workshops, Spaces, and a Builders’ Library. To mark the anniversary, Rick Suttles published a full feature timeline covering everything shipped over the past year: AWS Capabilities by Region (1,500+ services across 37 Regions), Spaces for community-created groups, workshops with category and complexity filters, badges and streaks, article series, view counts, saved items, student status, availability notifications, sign-in with GitHub and Amazon, and sandbox environments.

Jeff Barr published a retrospective summarizing Builder Center’s first year. Since launch, 5,548 authors have published 6,448 articles with more than 10.4 million page views combined. Builders have earned 99,226 badges since the badge system launched in March 2026. Community members have submitted 565 wishes, 10 of which have shipped with another 20 on the near-term roadmap.
The top community article Building an AWS Study Buddy with MCP + Strands Agents SDK by Dineshraj Dhanapathy reached 50,000+ views. Chris Miller’s Migrating an EOL Linux Server to AWS in 8 Hours with Kiro followed at 45,000+, and Yash Aggarwal’s AIdeas: NeuroVoice – Multimodal AI for Early Screening of Neurological Diseases article reached 38,000+.
The week’s headline addition is Sandbox Environments by Rick Suttles. Sandboxes give you a free, pre-provisioned AWS account to complete a workshop exercise. Each environment is active for 8 hours, after which the account and all its resources are automatically de-provisioned. You can have one active sandbox at a time and request one per week. No personal AWS account, credit card, or manual cleanup required.
Last week’s launches
Here’s what else happened this week.
- AWS Security Hub introduces Network Scanning – Security Hub introduced Network Scanning, a capability that identifies resources in your environment that are reachable from the public internet. Network Scanning probes your resources from the internet to detect actual reachability, complementing the existing network reachability findings in Security Hub that identify configurations that could make a resource reachable. It discovers public IP addresses, virtual machines, and load balancers across your AWS and Azure environments, identifies reachable ports, and determines what services are running behind them. Each reachable port generates a Security Hub finding with evidence of the port and service discovered. Security Hub Exposures then automatically correlates these findings with other findings and resource configurations to determine broader risk. Existing customers can enable Network Scanning in individual accounts and Regions, or across an organization through a configuration policy. For new customers, Network Scanning is on by default. It is included with Security Hub Essentials at no additional cost.
- Security Hub also extends unified security management to Microsoft Azure – Security Hub now monitors Microsoft Azure resources, providing unified posture management, vulnerability management, and security response across both clouds. It automatically discovers Azure VMs, container images, Function Apps, and identities, and evaluates them for misconfigurations, internet exposure, and software vulnerabilities. AWS and Azure findings appear in the same prioritized view with the same formats and automation workflows.
- Amazon SageMaker Studio integrates with Hugging Face for one-click model deployment and customization – You can now go from discovering a model on Hugging Face to working with it in SageMaker Studio in a single click. Select any supported model on Hugging Face and choose “Customize on SageMaker AI” or “Deploy on SageMaker AI” to land directly on the corresponding workflow page with the model pre-loaded. New customers receive a Studio environment created in seconds with pre-configured permissions for serverless model customization (including fine-tuning with custom reward functions for reinforcement learning), model evaluation, and deployment to SageMaker or Bedrock endpoints. Verified customers receive default GPU access to G5, G6, and G4dn instances without requesting quota increases, and quota utilization is visible directly inside the Studio environment.
- Amazon EKS Auto Mode and Amazon ECS Managed Instances reduce GPU management fees by up to 60% – Beginning July 1, 2026, EKS Auto Mode and ECS Managed Instances reduce management fees for accelerated instance types: G-series fees are down 35%, and P-series and AWS Trainium fees are down 60%. The reductions apply automatically to existing clusters and require no action from customers. Both services include capabilities built for accelerated workloads. EKS Auto Mode provides automatic parallel image pulling on GPU instances with local NVMe storage and accelerator-aware node repair. ECS Managed Instances provides GPU metrics through Amazon CloudWatch Container Insights and automatic health monitoring for GPU hardware failures.
- Amazon Aurora DSQL change data capture (CDC) is now generally available – Aurora DSQL CDC streams the results of insert, update, and delete operations as change events to Amazon Kinesis Data Streams. You can use it to synchronize data across microservices, trigger Lambda functions, or deliver changes to S3, Redshift, and OpenSearch Service through Amazon Data Firehose. CDC streaming is designed to have zero impact on database workload performance and requires no infrastructure to manage.
For a full list of AWS announcements, be sure to keep an eye on the What’s New with AWS page.
Other AWS news
Here are some additional posts you may find useful:
- Building secure AI agents at scale: Introducing Loom for AWS – Loom is an open-source enterprise platform for building agents with AWS Strands Agents and deploying them on Amazon Bedrock AgentCore Runtime. It provides a unified management UI and backend API with identity provider integration, scope-based authorization, multi-persona navigation, and full lifecycle management for agents, memory, MCP servers, and agent-to-agent integrations. Loom enforces automated resource tagging for cost attribution, implements RBAC and ABAC for multi-tenant security, uses paved-path blueprints for agent deployments, manages identity propagation through delegated actor chains, integrates with AWS Agent Registry for discovery and governance, and supports human-in-the-loop review before sensitive actions. The project is available in AWS Labs on GitHub.
- Introducing Claude apps gateway for AWS – The Claude apps gateway is a self-hosted control plane that gives organizations centralized control over access, cost, and policy for Claude Code and Claude Desktop. It connects to any OIDC-compliant identity provider, enforces managed settings on every request, routes inference to Amazon Bedrock or Claude Platform on AWS, and supports per-user and per-group spend caps. The gateway runs as a stateless container in your private network, backed by a PostgreSQL database for short-lived sign-in state. No long-lived secrets are stored on developer machines. Deploy it through Amazon Bedrock to keep data within the AWS security boundary, or through Claude Platform on AWS for the native Claude platform experience.
- Introducing OAuth support for AWS MCP Server – You can now connect agents to the AWS MCP Server using browser-based OAuth with the same credentials you use for the AWS Console or CLI. The new sign-in path supports IAM federation, AWS IAM Identity Center, and root or IAM users. AWS Sign-In issues short-lived access tokens and refresh tokens, with automatic token management so developers stay authenticated across restarts. For headless use cases, a non-interactive flow lets applications with existing AWS credentials obtain OAuth access tokens through the
create-oauth2-token-with-iamAPI. New governance controls include OAuth-specific IAM condition keys, token introspection and revocation, dynamic client registration, and CloudTrail audit elements.
For a full list of AWS blog posts, be sure to keep an eye on the AWS Blogs page.
Upcoming AWS events
Check your calendar and sign up for upcoming AWS events:
- AWS Summits – Free in-person events for builders and innovators to learn, think big, and make new connections. Coming up: Taipei (July 15), Bogotá (July 30), Jakarta (August 6), Ciudad de México (August 12), Johannesburg (August 19), and Zurich (September 2).
- AWS Community Days – Community-led conferences planned and delivered by community leaders. Upcoming events include Yaoundé, Cameroon (July 25), Ahmedabad, India (July 25), Belo Horizonte, Brazil (August 22), Ottawa, Canada (August 22), Tulsa, USA (August 22), and Toronto, Canada (August 29).
Visit the AWS Builder Center to meet other builders, contribute solutions, and find resources that help you keep building.
Wishing everyone a restful and enjoyable summer. Whether you’re building, learning, or recharging, I hope you find time for all three. I’ll be heading to Scandinavia for a few weeks to trade the heat for some cooler weather and longer evenings. Come back next week for more news!
— Esrafrom AWS News Blog https://ift.tt/AX7Fw3v
via IFTTT
Wednesday, July 8, 2026
SP-API Updates: Invoice by Amazon Expansion for VCS Lite Sellers and New Cancellation XML for Brazil Store
via <a href="https://www.sarasanalytics.net/2026/07/sp-api-updates-invoice-by-amazon.html">Ecommerce Data Analytics</a>
Monday, July 6, 2026
AWS Weekly Roundup: Claude Sonnet 5 on AWS, Amazon WorkSpaces for AI agents, AWS service availability updates, and more (July 6, 2026)
A couple of editions ago I wrote about what I find so energizing about working with startups. Last week I got a fresh dose of it: I spent a few days with the AWS Startups team, listening to stories of founders talking about the problems they’re actually solving. One story that stayed with me came from Marco Negreiros, founder of EyeCare Health, a Brazilian healthtech expanding access to eye care. He shared a striking fact: more than 70% of Brazilian municipalities don’t have a single ophthalmologist. His answer was to put a vision test on the one device almost everyone already carries, the smartphone, so a basic eye screening no longer depends on living near a clinic. Watching a founder turn a gap that big into something that concrete is exactly why I love this space.

This week, I’ll take a closer look at some key launches, and then cover the quarterly AWS Service Availability updates.
Last week’s launches
Here are some of the launches covered from this past week in the AWS News Blog:
- Amazon EC2 C9g and C9gd instances powered by AWS Graviton5 processors: They deliver up to 25% better compute performance than Graviton4-based instances, 5x larger cache, fastest memory of any processor instances in the cloud, and local NVMe storage options (C9gd).
- A new AWS CloudFormation Express mode: You can speed up infrastructure deployment with AWS CloudFormation Express mode, enabling AI agents and developers to receive deployment confirmation in seconds and iterate faster. Available in all commercial Regions at no additional cost.
- Upgrade Amazon EKS clusters with confidence using Kubernetes version rollbacks: Learn how Kubernetes version rollbacks for Amazon EKS let you reverse cluster upgrades within seven days. This new feature provides a safety net for upgrade failures, no cluster rebuilds required, turning Kubernetes version upgrades into a reversible, low-risk operation.
- Automate public TLS certificate issuance with ACME support in AWS Certificate Manager: AWS Certificate Manager now supports the ACME protocol, so you can automate the issuance and renewal of public TLS certificates using standard, widely adopted tooling.
Here are some launches and updates that caught my attention:
- Claude Sonnet 5 is now available on AWS – Anthropic’s most capable Sonnet model brings top-tier intelligence at Sonnet pricing for coding, agents, and everyday professional work at scale. It navigates large codebases, calls tools precisely, and holds state across long agentic tasks. To learn more, visit the AI Blog post.
- Amazon WorkSpaces for AI agents is now generally available: AI agents can now securely access and operate desktop applications through managed WorkSpaces environments, without requiring application modernization or custom integrations. To learn more. visit the Desktop and Application Streaming Blog post.
- Amazon OpenSearch Service is now optimized for log analytics: This release introduces a new engine purpose-built for log analytics workloads that delivers up to 4x better price-performance on internal benchmarks, while keeping the full-text search capabilities OpenSearch is known for. Teams can now get aggregations and precise text search in one place. To learn more, visit the Big Data Blog post.
- Amazon SageMaker AI cuts generative AI inference scale-out time by up to half: SageMaker Inference now supports container image caching, enabling up to 2x faster end-to-end scaling for generative AI models during scale-out events. To learn more, visit the AI Blog post.
- Amazon CloudWatch supports creating alarms from log queries : You can now create alarms directly on log query results and set thresholds in a single workflow, eliminating the need to first create metric filters or custom metrics as intermediate steps.
For a full list of AWS announcements, be sure to keep an eye on the What’s New with AWS page.
AWS Service Availability Updates
When the availability of an AWS service or feature changes, we provide customers guidance in AWS Product Lifecycle Changes on available alternatives and support for migration so that disruptions to your operations are minimized. The following lifecycle changes were updated on June 30, 2026.
Services moving to Maintenance (no longer accessible to new customers starting July 30, 2026):
- Amazon Bedrock Agents (launched November 2023) is now Amazon Bedrock Agents Classic
- Amazon Cognito Sync
- Amazon Kendra
- Amazon Q Business
- AWS Directory Service – Simple AD
- AWS IoT Device Defender – Detect (feature will no longer be accessible to new customers starting August 31, 2026)
- AWS Mainframe Modernization – Self-Managed Experience
- AWS Management Console – myApplications
- AWS Resource Groups – Group Lifecycle Events
- AWS Service Catalog – Application Registry
- AWS Systems Manager – Application Manager
- Amazon SageMaker AI features: A2I, Clarify, Debugger, GeoSpatial, Ground Truth, Mechanical Turk, Model Monitor, Role Manager, and Studio Lab
Services entering Sunset:
- Amazon WorkSpaces – PCoIP
- Amazon WorkSpaces – Pool
- AWS Managed Services (AMS) Advanced
- AWS re:Post Private
- Amazon Sagemaker AI- Profiler
Services reaching End of Support (as of June 30, 2026):
- Amazon Chime SDK – Carrier Voice Focus
- Amazon SageMaker AI – Ground Truth Plus
We understand that changes in availability can impact your operations. For specific guidance, consult the relevant service documentation or contact AWS Support.
Upcoming AWS events
Check your calendar and sign up for upcoming AWS events:
- AWS Summits – AWS Summits are free events that bring the cloud and AI community together to connect, learn, and explore the latest technologies. Browse the full calendar to find a Summit near you in the second half of 2026.
- AWS Community Days – Community-led conferences where content is planned, sourced, and delivered by community leaders. If you’re in Latin America, don’t miss AWS Community Day Belo Horizonte on August 22. Registration is open at awscommunityday.com.br.
Join the AWS Builder Center to connect with builders, share solutions, and access content that supports your development. Browse here for upcoming AWS-led in-person and virtual events and developer-focused events.
That’s all for this week. Check back next Monday for another Weekly Roundup!
– Daniel Abib
This post is part of our Weekly Roundup series. Check back each week for a quick roundup of interesting news and announcements from AWS!
from AWS News Blog https://ift.tt/8sT2LJZ
via IFTTT
Wednesday, July 1, 2026
SP-API Updates: EU FBM Requirements, Product Type Definitions API Title Structure, External Fulfillment API Shipment Status
via <a href="https://www.sarasanalytics.net/2026/07/sp-api-updates-eu-fbm-requirements.html">Ecommerce Data Analytics</a>
Upgrade Amazon EKS clusters with confidence using Kubernetes version rollbacks
Upgrading a Kubernetes control plane has long been a one way door. Open source Kubernetes doesn’t support control plane rollback, so once you upgrade, there’s no going back. The community is making real progress here, and KEP-4330 introduces emulated versions to ease rollback. But in practice this constraint has pushed organizations to build elaborate compensating mechanisms like bake periods, stagger groups, automated sign offs, and months long upgrade cycles. With Kubernetes releasing three minor versions per year, teams managing hundreds of clusters, especially in regulated environments, often delay upgrades entirely because they aren’t confident they can recover if something goes wrong. The result is clusters stuck on older versions, missing security patches, and eventually running up against extended support timelines.
Today, we’re announcing Kubernetes version rollbacks for Amazon Elastic Kubernetes Service (Amazon EKS), a new feature that gives cluster administrators a safety net when performing cluster upgrades. With version rollbacks, you can reverse a Kubernetes version upgrade within seven days if you encounter issues after upgrading, returning your cluster to its previous working state.
Where approaches like emulated versions keep a cluster in a transitional holding state, EKS version rollback returns your cluster to a fully validated previous version that ran in production, not an emulation of it. Now, if you upgrade a cluster from, say, Kubernetes 1.34 to 1.35 and discover a compatibility issue, you can roll back to 1.34 within seven days. There’s no need to rebuild your cluster or scramble to troubleshoot under pressure. Think of it as an undo button for Kubernetes version upgrades.
The feature supports rolling back one minor version at a time, matching the same incremental approach EKS uses for upgrades. And to help you roll back safely, EKS automatically evaluates your cluster’s rollback readiness through cluster insights, flagging items like node version compatibility or add-on dependencies before you proceed. If you’ve already assessed the situation and want to move quickly, you can use the --force flag to bypass those checks. The above applies to all EKS clusters, whether you manage your own nodes or let AWS handle them. But for customers who have embraced fully managed infrastructure, rollback goes a step further.
Rollback for EKS Auto Mode
EKS Auto Mode gives you one click deployment of production ready Kubernetes clusters, automating compute, networking, and storage management so you can focus on your applications rather than infrastructure. EKS Auto Mode introduces additional considerations for version rollbacks because both the control plane and managed nodes need to be rolled back together. Since node rollbacks respect your pod disruption budgets, the process can take time depending on your configuration.
To give you control over this process, we’ve introduced a cancel API that lets you stop a node rollback at any point. If you decide the rollback is taking too long or you want to change your approach, you can cancel and adjust your disruption budgets to accelerate things, or choose a different path forward.
By default, EKS never bypasses your disruption budgets during a rollback because we prioritize workload stability. You can always choose to modify or remove disruption budgets yourself to speed up the process if needed.
Let’s try it out
To try version rollbacks, I navigated to the Amazon EKS console and selected one of my clusters that I had recently upgraded.
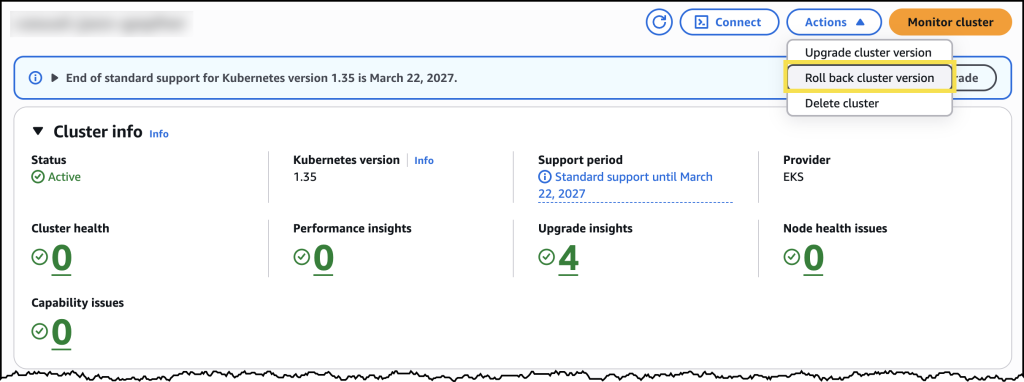
From the cluster’s configuration page, I can see the option to initiate a version rollback, along with information about my current rollback window.
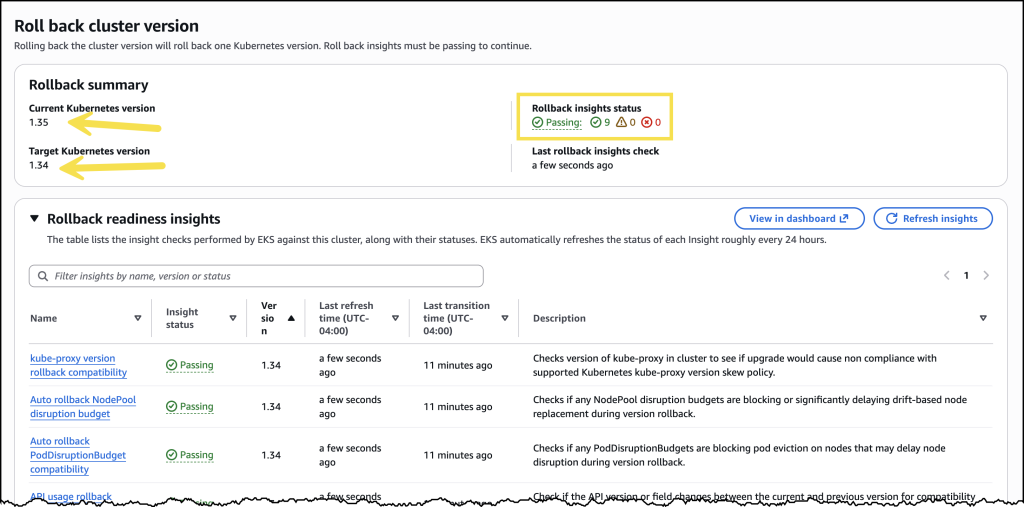
Before initiating the rollback, I reviewed the rollback insights to check for any potential issues. The insights showed me the status of my nodes and flagged anything I should address before proceeding.
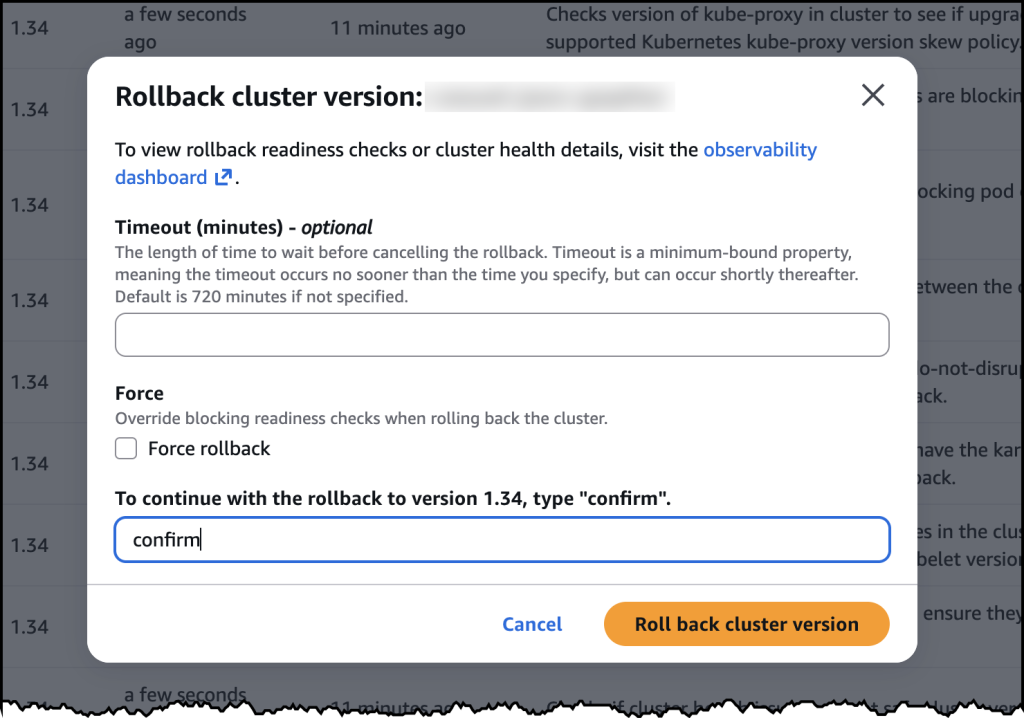
After confirming, the rollback began. My cluster remained functional throughout the process. The control plane rollback took about 20 minutes, similar to a standard upgrade. For my EKS Auto Mode cluster, the nodes rolled back gracefully according to my disruption budget settings.
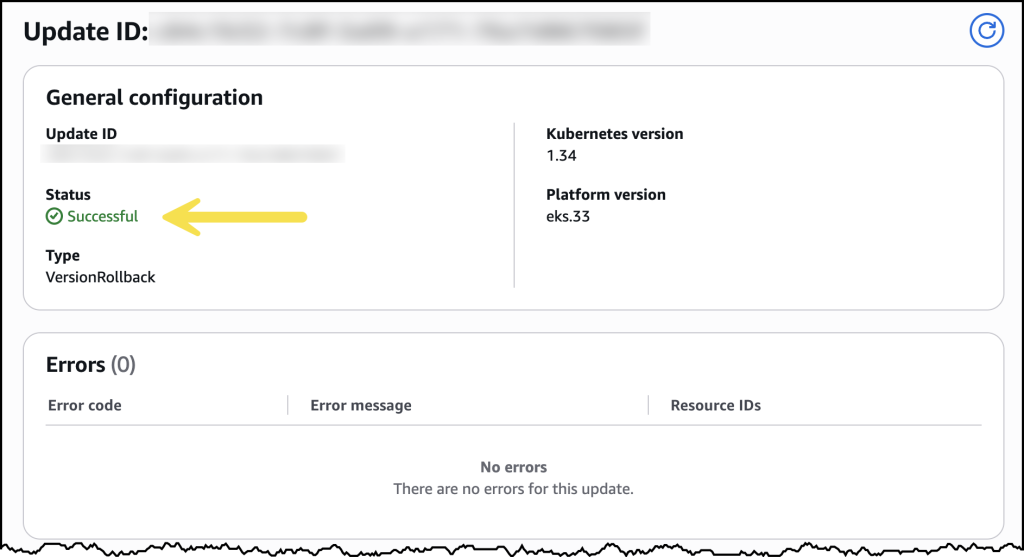
Once complete, my cluster was back on the previous Kubernetes version, running as expected.
Now available
Kubernetes version rollbacks for Amazon EKS are available today at no additional cost in all commercial AWS Regions where Amazon EKS is available. You pay only for the standard EKS and compute costs you would normally incur. There are no extra charges for using the rollback capability.
Control plane rollbacks are available for all EKS clusters, and node rollbacks are available for clusters running EKS Auto Mode. Version rollbacks support clusters running Kubernetes versions available in EKS standard support and extended support.
To get started, visit the Amazon EKS documentation or try it out directly in the Amazon EKS console.
from AWS News Blog https://ift.tt/ykcEVvX
via IFTTT
Tuesday, June 30, 2026
Amazon EC2 C9g and C9gd instances powered by AWS Graviton5 processors are now available
When you run compute-intensive workloads like real-time analytics, batch processing, video encoding, scientific modeling, or CPU-based machine learning inference, every percentage point of performance matters. You need instances that deliver higher throughput per vCPU, faster memory access, and more network bandwidth, all while keeping your costs in check.
Today I am happy to announce the general availability of Amazon Elastic Compute Cloud (Amazon EC2) C9g and C9gd instances, powered by AWS Graviton5 processors. C9g instances are compute-optimized and deliver up to 25% higher performance per vCPU compared to previous-generation C8g instances. They feature the fastest memory of any processor instance in the cloud, with DDR5 8800MT/s DIMMs, 5x more L3 cache, and up to 3x higher packet-processing performance compared to Graviton4-based instances. The faster memory and larger caches mean your workloads spend less time waiting on data, translating into higher throughput for in-memory analytics, faster agentic loops, and more responsive real-time applications.
C9g instances are ideal for batch jobs, video encoding pipelines, or distributed analytics that can utilize Amazon Elastic Block Store (Amazon EBS) for storage. It is also a natural fit for agentic AI workloads, where concurrent environments and CPU-bound reasoning steps benefit from Graviton5’s higher core count and larger caches. As AI shifts from answering questions to taking actions, running code, and orchestrating multi-step tasks, the demand for CPU compute is growing, and C9g instances are built for this shift.
Some workloads also need fast local storage alongside that compute power. Choose C9gd when your application benefits from high-speed, low-latency local NVMe SSD storage, for example scratch space during HPC simulations, temporary caches for ML inference, or local buffers for ad-serving engines.
Graviton5-based instances with NVMe instance store volumes also support detailed performance statistics, providing high-resolution I/O metrics, including latency histograms broken down by I/O size, up to 1-second granularity and accessible via Amazon CloudWatch or nvme-cli at no additional cost.
C9g and C9gd instances at a glance
C9g and C9gd instances are available in 11 sizes ranging from medium to 48xlarge, plus a bare metal option. They offer up to 15% higher network bandwidth and 20% higher EBS bandwidth on average across sizes compared to the previous generation, with the largest 48xlarge size delivering up to 100 Gbps of network bandwidth and up to 72 Gbps of EBS bandwidth, a 2x increase.
| C9g | vCPUs | Memory (GiB) |
Network Bandwidth (Gbps) |
EBS Bandwidth (Gbps) |
|---|---|---|---|---|
| medium | 1 | 2 | Up to 15 | Up to 12 |
| large | 2 | 4 | Up to 15 | Up to 12 |
| xlarge | 4 | 8 | Up to 15 | Up to 12 |
| 2xlarge | 8 | 16 | Up to 17 | Up to 12 |
| 4xlarge | 16 | 32 | Up to 17 | Up to 12 |
| 8xlarge | 32 | 64 | 17 | 12 |
| 12xlarge | 48 | 96 | 25 | 18 |
| 16xlarge | 64 | 128 | 34 | 24 |
| 24xlarge | 96 | 192 | 50 | 36 |
| 48xlarge | 192 | 384 | 100 | 72 |
| metal-48xl | 192 | 384 | 100 | 72 |
C9gd instances add local NVMe SSD storage with up to 30% higher storage performance compared to previous-generation local storage instances.
| C9gd | vCPUs | Memory (GiB) |
Instance Storage (GB) |
Network Bandwidth (Gbps) |
EBS Bandwidth (Gbps) |
|---|---|---|---|---|---|
| medium | 1 | 2 | 1 x 59 | Up to 15 | Up to 12 |
| large | 2 | 4 | 1 x 118 | Up to 15 | Up to 12 |
| xlarge | 4 | 8 | 1 x 237 | Up to 15 | Up to 12 |
| 2xlarge | 8 | 16 | 1 x 474 | Up to 17 | Up to 12 |
| 4xlarge | 16 | 32 | 1 x 950 | Up to 17 | Up to 12 |
| 8xlarge | 32 | 64 | 1 x 1900 | 17 | 12 |
| 12xlarge | 48 | 96 | 3 x 950 | 25 | 18 |
| 16xlarge | 64 | 128 | 1 x 3800 | 34 | 24 |
| 24xlarge | 96 | 192 | 3 x 1900 | 50 | 36 |
| 48xlarge | 192 | 384 | 3 x 3800 | 100 | 72 |
| metal-48xl | 192 | 384 | 3 x 3800 | 100 | 72 |
Both families are well-suited for high-performance computing (HPC), batch processing, gaming, video encoding, scientific modeling, distributed analytics, CPU-based machine learning inference, and ad serving.
Here are some additional capabilities:
- Instance Bandwidth Configuration (IBC) lets you adjust the allocation of bandwidth between Amazon EBS and Amazon VPC networking by up to 25%, helping you optimize performance for workloads with specific bandwidth requirements such as databases and caching.
- ENA Express support for enhanced networking.
- Up to 128 EBS volumes can be attached to virtual instances.
- Support for Savings Plans, On-Demand, Spot Instances, Dedicated Instances, and Dedicated Hosts.
Nitro Isolation Engine
C9g and C9gd instances are the first compute optimized Amazon EC2 instances to feature the AWS Nitro Isolation Engine, a new capability of the AWS Nitro System. The Nitro Isolation Engine is a purpose-built component of the Nitro Hypervisor, implemented in Rust, that enforces isolation between virtual machines. It mediates all access to VM memory, CPU register state, and I/O devices through a minimal set of APIs.
To learn more about the Nitro Isolation Engine, visit the blog post. For details on the formal verification results, including scope and assumptions, see our technical white paper.
Now available
Amazon EC2 C9g and C9gd instances are now available in US East (Ohio, N. Virginia), US West (Oregon), and Europe (Frankfurt). Additional regions will follow.
You can launch C9g and C9gd instances today using the AWS Management Console, AWS Command Line Interface (AWS CLI), or AWS SDKs. For pricing information, visit the Amazon EC2 Pricing page.
To learn more, visit the Amazon EC2 C9g and C9gd instances page and send feedback to AWS re:Post for EC2 or through your usual AWS Support contacts.
— sebfrom AWS News Blog https://ift.tt/ZeoBWM3
via IFTTT
Automate public TLS certificate issuance with ACME support in AWS Certificate Manager
If you manage TLS certificates for your applications, you know the challenge: certificates expire, and when they do, your customers see errors or your service goes down. As certificate validity periods get shorter (the Certification Authority (CA)/Browser Forum mandates reduced maximum validity to 100 days starting March 2027, and to 47 days by 2029), manual renewal processes become untenable. You need automation.
Automatic Certificate Management Environment (ACME) is an open protocol for requesting, renewing, and revoking TLS certificates without human intervention. It’s the same protocol behind Let’s Encrypt, and it’s supported by dozens of clients across every platform.
Today we’re announcing ACME support for public certificates in AWS Certificate Manager (ACM). ACM now provides a fully managed ACME server endpoint that works with any ACMEv2-compatible client, such as Certbot, cert-manager for Kubernetes, acme.sh, or any other client you already use. You can issue public TLS certificates from Amazon Trust Services through the standard ACME protocol.
Before today, if you wanted automated certificate management using the ACME protocol, you relied on external certificate authorities alongside ACM, leading to a fragmented visibility experience. Some certificates lived in ACM, others were managed externally with no central dashboard. PKI administrators had limited ability to control who could request certificates or which domains were allowed.
With ACME support in ACM, you can now set up one or more managed ACME endpoint that allows you to centrally manage and monitor ACME certificate usage across your organization.
As a PKI administrator, you get centralized controls that go beyond basic certificate issuance. You can bind IAM roles to ACME accounts for fine-grained access control over which domains each client can request. You can define domain scopes at the endpoint level to enforce organization-wide policies. And you get centralized monitoring and visibility in the same place: AWS CloudTrail logs every certificate request for auditability, Amazon CloudWatch tracks operational metrics, and ACM sends expiry notifications when certificates are approaching renewal. Using ACM, your PKI team can search all certificates, whether issued through the ACM console, an API call, or ACME.
How it works
To get started, you first set up a dedicated ACME endpoint, configure authorization controls using External Account Binding (EAB), validate which domains the endpoint can issue certificates for, and point your existing ACME clients to the new endpoint.
The domain validation step is important: it separates who can set up certificate issuance from who can request certificates. The PKI administrator validates domains once at the endpoint level, using DNS credentials that stay with the admin. Application owners who need certificates never touch DNS. They register with an EAB credential, and the endpoint enforces which domains and scopes they’re allowed to request. This means you can distribute certificate automation broadly across your organization without distributing DNS keys along with it.
I start this demo from the ACME certificates page in the AWS Certificate Manager console.
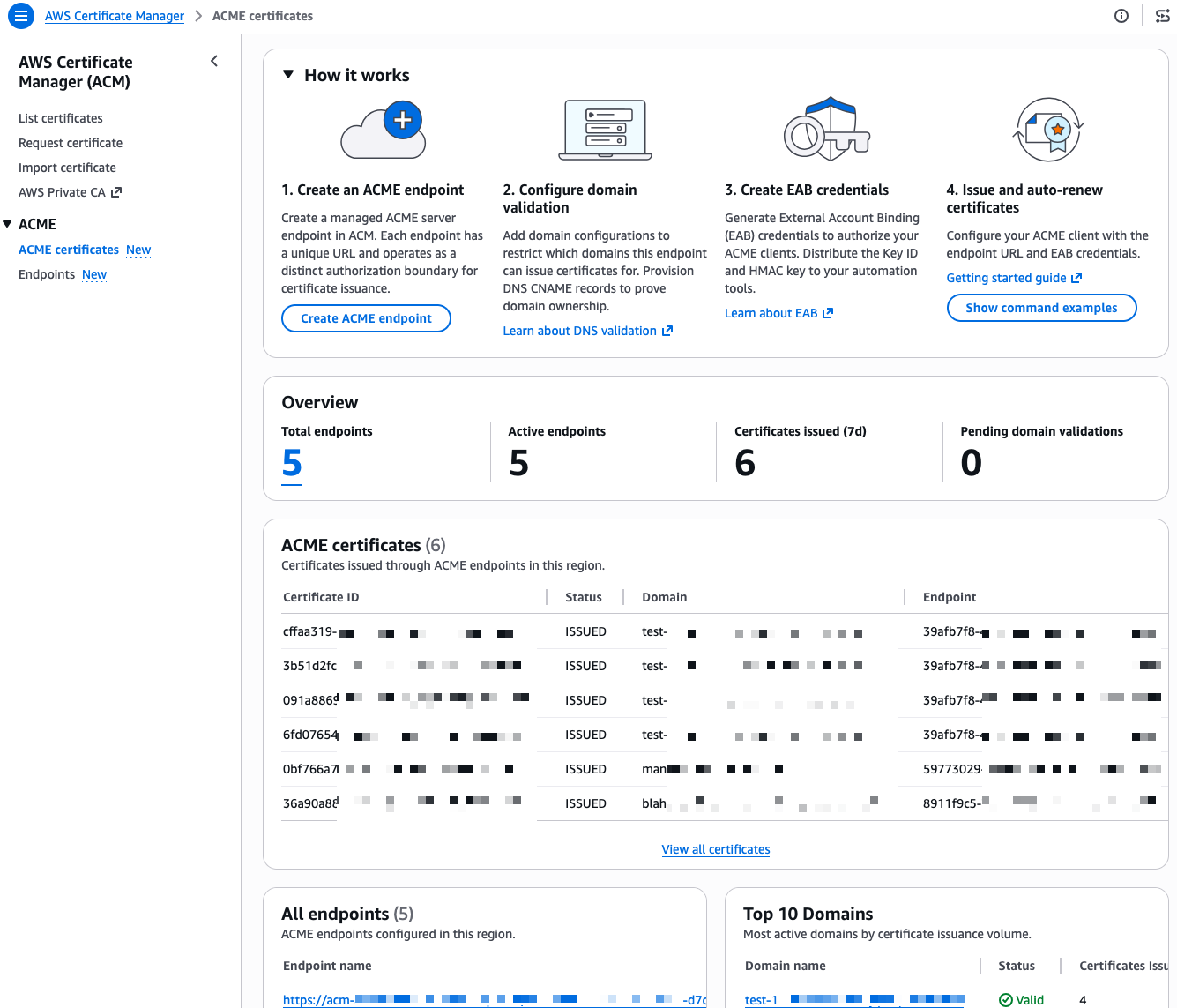
I already have a few endpoints and certificates in this account, I walk you through creating a new one from scratch. First, I select Create ACME endpoint.
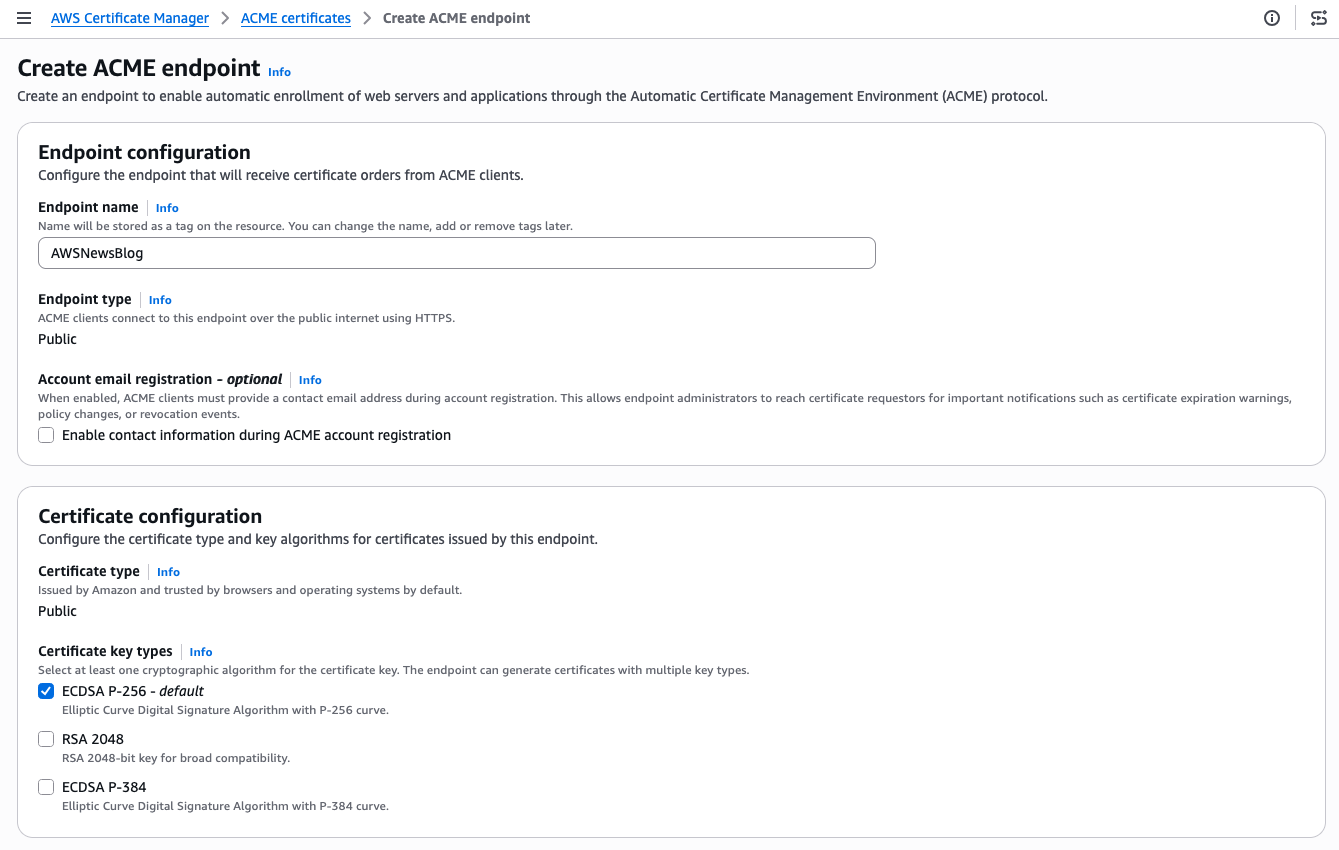
I give my endpoint a name. The Endpoint type is Public. ACME clients will connect over the public internet. The Certificate type is Public. The certificate will be issued by Amazon Trust Services and trusted by browsers and operating systems by default. For the certificate key type, I keep the default ECDSA P-256. RSA 2048 and ECDSA P-384 are also available if your clients require them.
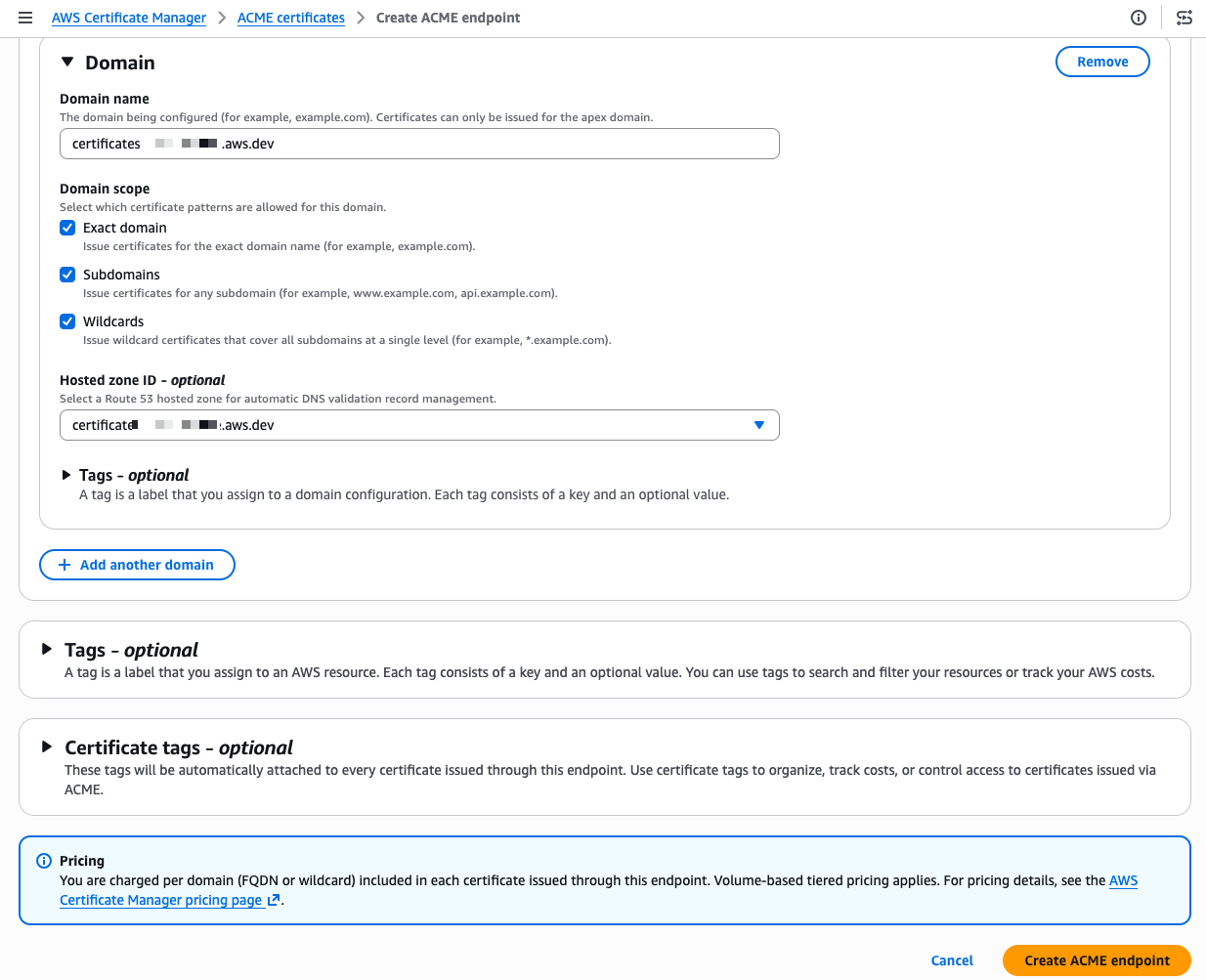
Scrolling down, I configure the domain. I enter my domain name and select the domain scope. The scope controls exactly what certificate patterns your ACME clients are allowed to request for this domain. If I check only Exact domain, clients can only request certificates for that specific domain name. Adding Subdomains allows certificates for any subdomain (for example, api.example.com or dev.example.com). Adding Wildcards allows wildcard certificates (*.example.com). By leaving a scope unchecked, you prevent any client using this endpoint from requesting that type of certificate, even if their ACME request is otherwise valid. For a production endpoint, you might enable only Exact domain and Subdomains while leaving Wildcards unchecked to enforce a stricter security posture.
I also select my Amazon Route 53 hosted zone from the drop down menu. ACM then automatically creates the DNS CNAME records needed for domain validation, so I don’t have to do it manually. When my domain is hosted outside of Route 53, I manually create the provided CNAME record at my DNS provider instead. This is a meaningful difference from typical ACME setups where each client handles its own domain verification independently.
These centralized controls give PKI administrators a single place to authenticate domains, restrict which certificate types (ECDSA or RSA) clients can request, and further limit wildcard issuance. Having these governance capabilities built in means you don’t need to purchase a separate certificate lifecycle management product or invest in building a custom policy layer yourself, both of which come at significant cost and operational overhead.
I select Create ACME endpoint
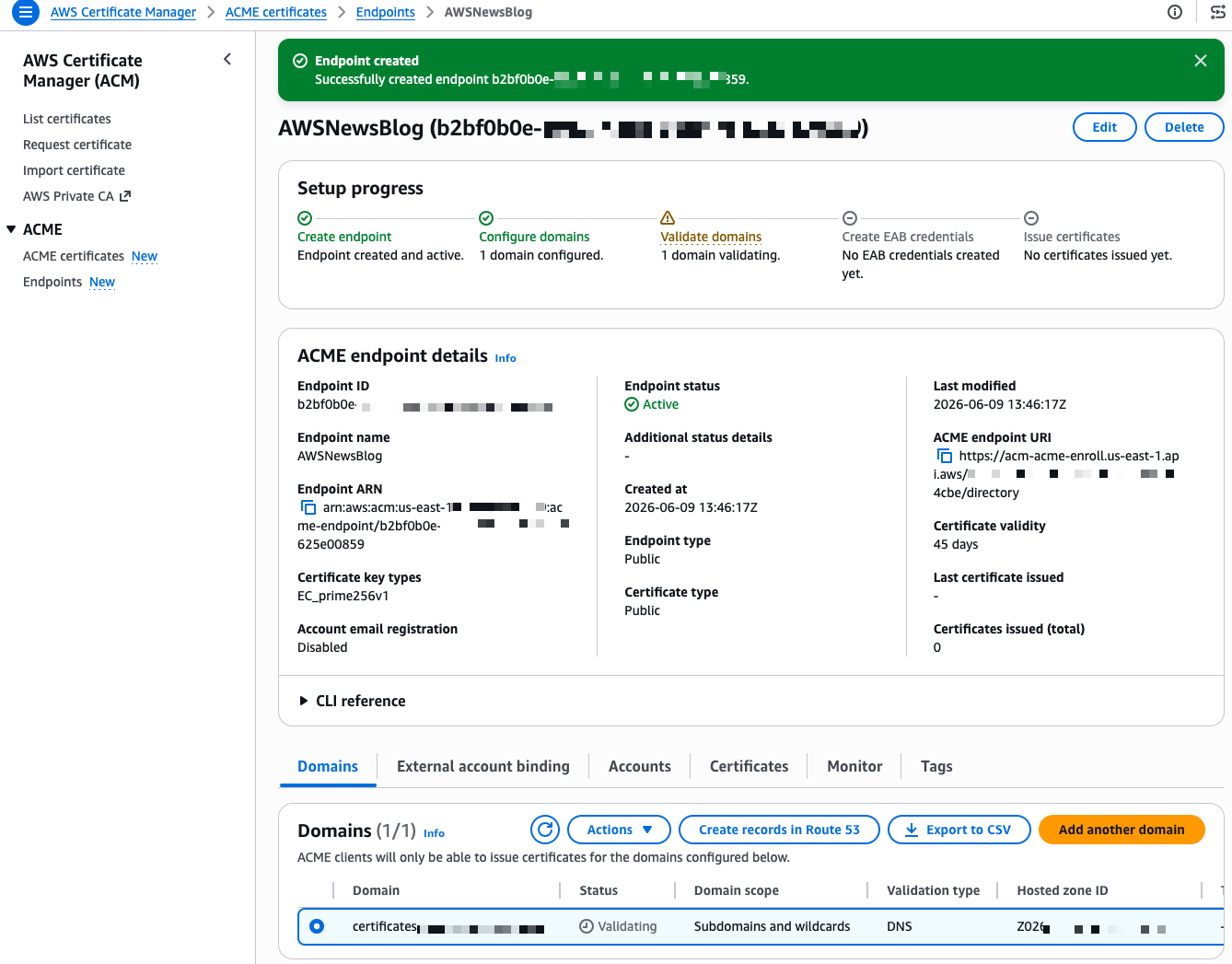
After a few seconds, the endpoint is created. The console shows a Setup progress tracker with the next steps. My domain shows a “Validating” status. The validation method is DNS validation, where ACM verifies that you control the domain by checking for a specific CNAME record. Because I selected my Route 53 hosted zone during creation, I select Create records in Route 53 to let ACM handle the DNS validation automatically.
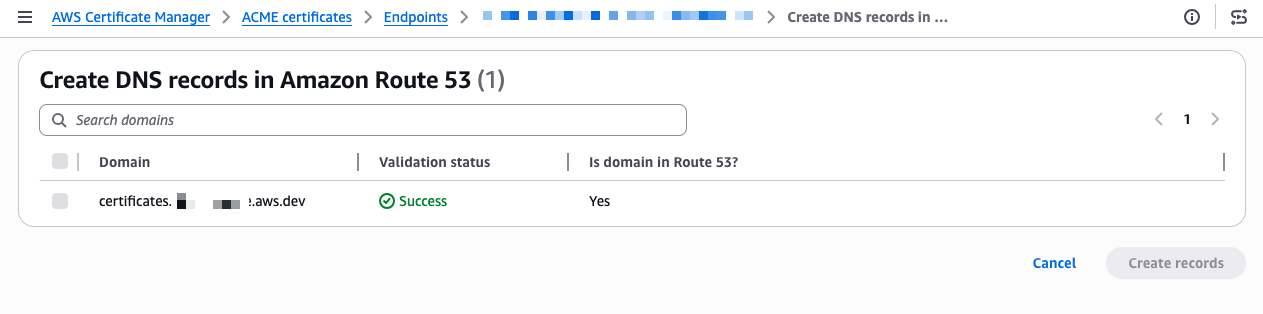 The validation completes in a few seconds and the status changes to Success.
The validation completes in a few seconds and the status changes to Success.
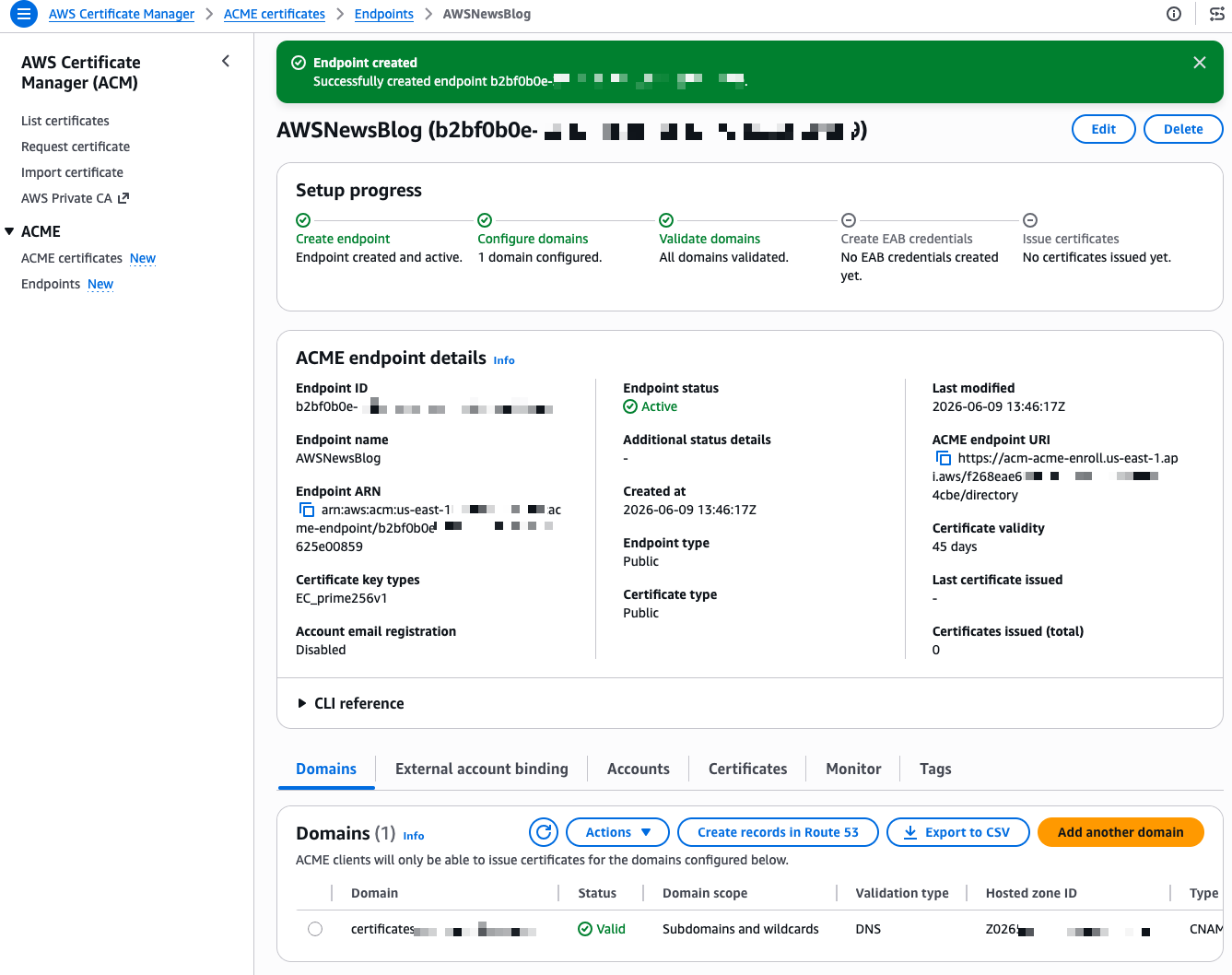
Now I need to create External Account Binding (EAB) credentials. EAB credentials are a key identifier and HMAC key pair that lets your ACME client register an account with the ACME server. Once registered, the client generates its own asymmetric key pair, which is then used to authenticate all subsequent certificate requests. On the endpoint details page, I select the External account binding tab, then select Create EAB. I give the credential a name and optionally set an expiration time, ideally no longer than needed to complete client registration.
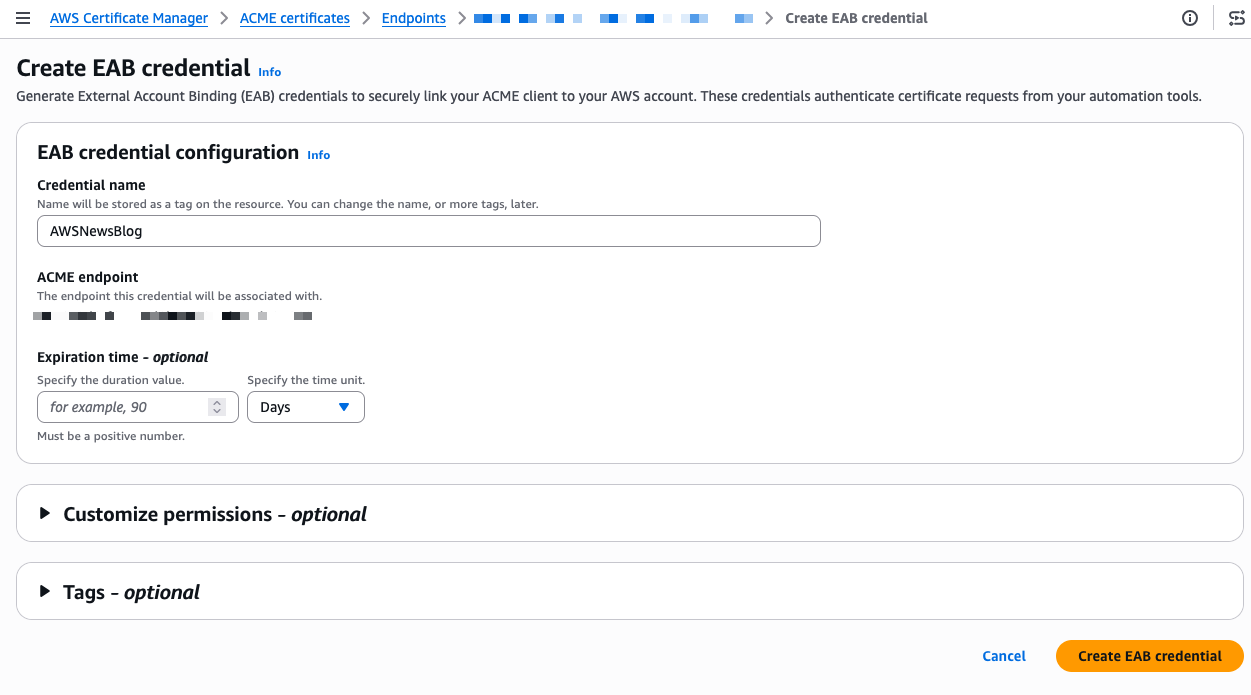
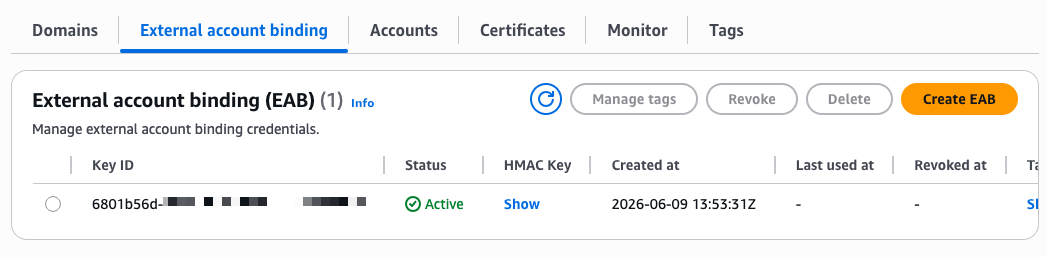
After I select Create EAB credential, the console shows the Key ID and HMAC Key. I note these values because I need them to configure my ACME client. The setup progress now shows four green checkmarks.
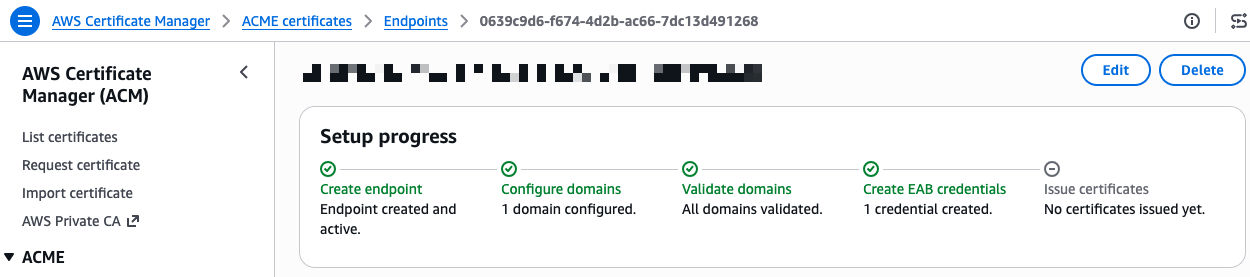
I’m ready to request a certificate. On the endpoint details page, I expand the CLI reference section. The console provides ready-to-use command examples for both Certbot and acme.sh. I copy the Certbot command and run it inside a container using the certbot/certbot image.
certbot certonly --standalone --non-interactive --agree-tos \
--email <EMAIL> \
--server https://acm-acme-enroll.us-east-1.api.aws/<ENDPOINT_ID>/directory \
--eab-kid <EAB_KID> \
--eab-hmac-key <EAB_HMAC_KEY> \
--issuance-timeout <ISSUANCE_TIMEOUT> \
-d <DOMAIN>I replace the placeholders with my endpoint URL, EAB credentials, and domain name. The --eab-kid and --eab-hmac-key arguments are how Certbot registers with your ACME endpoint using the External Account Binding credentials I generated earlier. Each ACME client has its own syntax for this step, so check your client’s documentation for the exact flags.
Certbot contacts the ACME endpoint and returns a valid certificate signed by Amazon Trust Services.
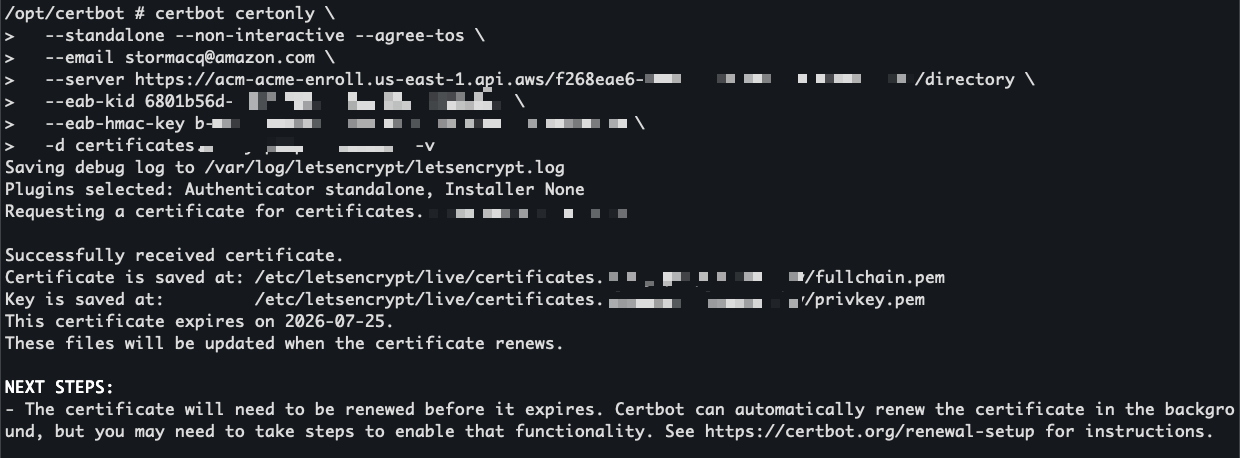
I use openssl to view the certificate before installing it.
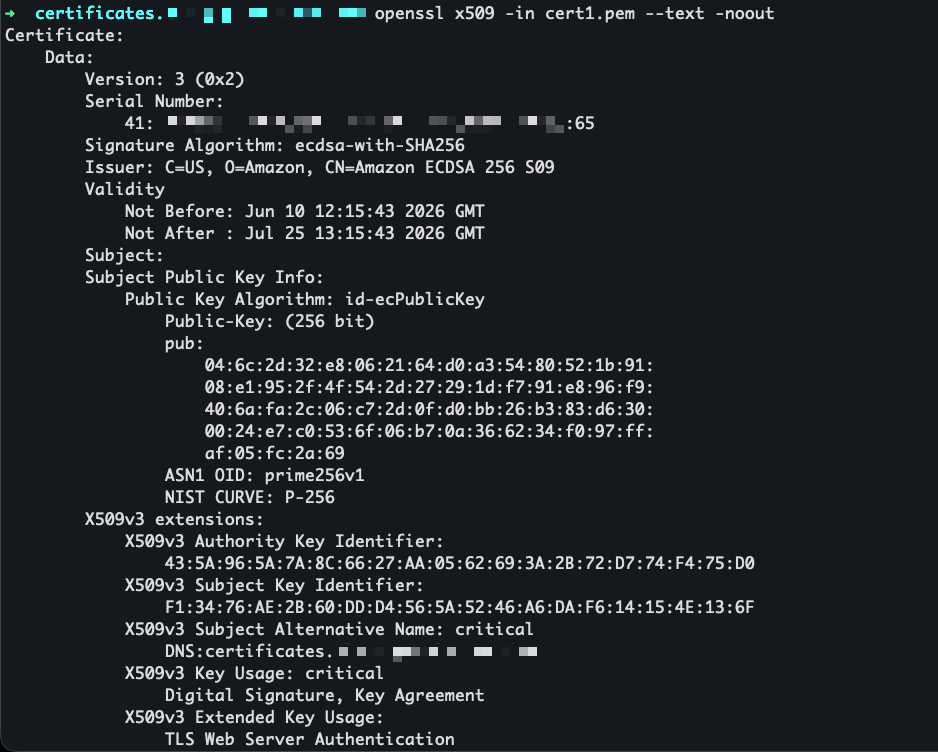
The certificate is now visible in the ACM console under the ACME certificates tab, alongside any certificates issued through the console or API.
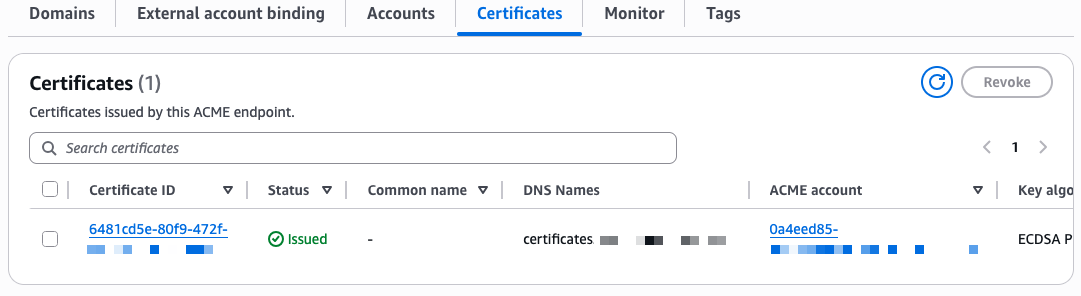
Availability and pricing
ACME support in AWS Certificate Manager is available today in all commercial AWS Regions and will be available in AWS GovCloud (US), the China Regions, and the AWS European Sovereign Cloud partitions at a later date.
Pricing is per domain included in each certificate at the time of issuance, with a different price for fully qualified domain names and wildcards. Volume tiers are calculated based on total domain occurrences across all certificates issued per month in your AWS account. For details, see the ACM pricing page.
To get started, visit the ACM section on the AWS console or read the documentation.
— sebfrom AWS News Blog https://ift.tt/cSfbQG8
via IFTTT
Subscribe to:
Posts (Atom)