Tuesday, December 27, 2022
Friday, December 23, 2022

Thursday, December 22, 2022

Monday, December 19, 2022
AWS Week in Review – December 19, 2022
We are half way between the re:Invent conference and the end-of-year holidays, and I did expect the cadence of releases and news to slow down a bit, but nothing is further away from reality. Our teams continue to listen to your feedback and release new capabilities and incremental improvements.
This week, many items caught my attention. Here is my summary.
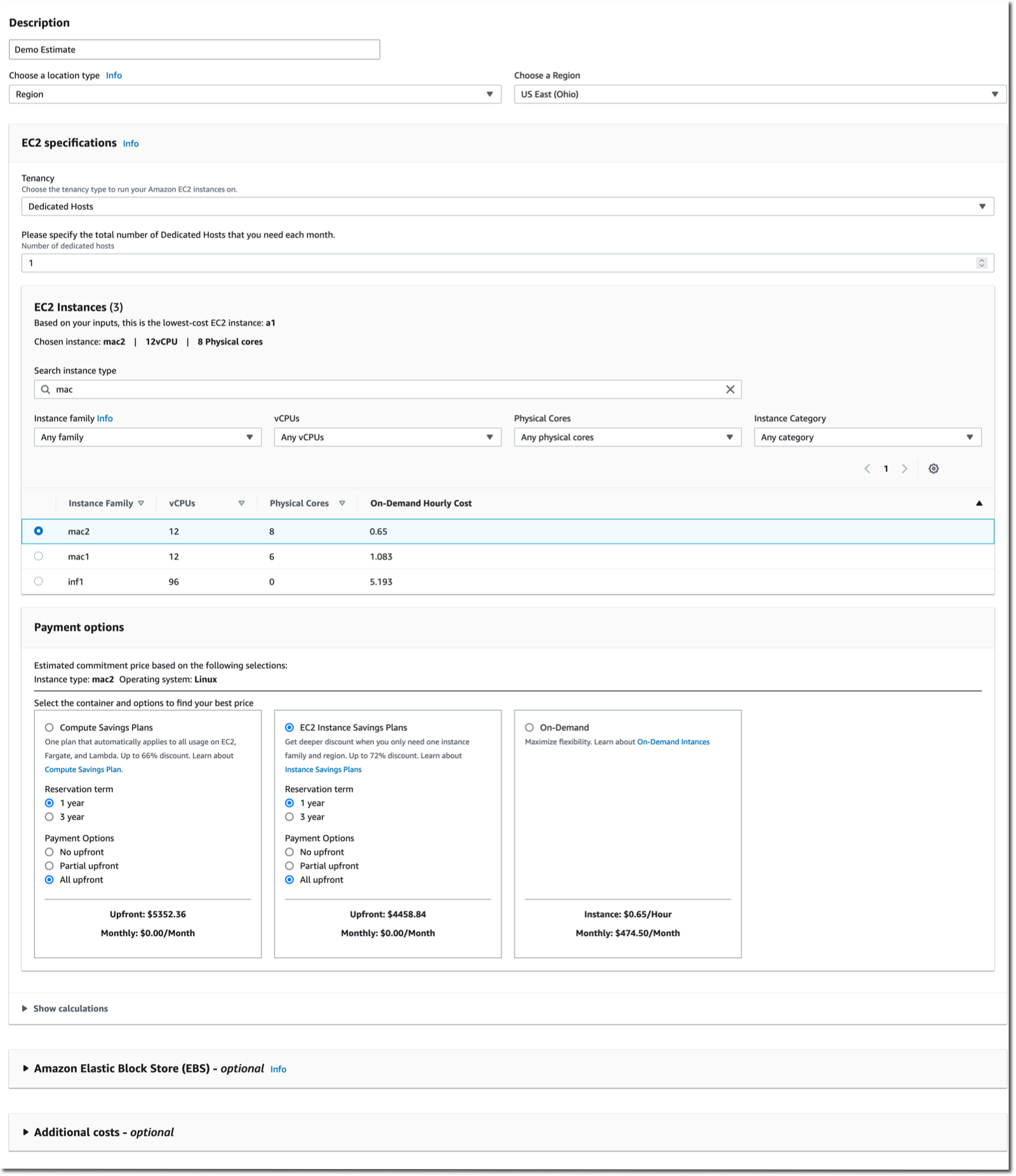
The AWS Pricing Calculator for Amazon EC2 is getting a redesign to provide you with a simplified, consistent, and efficient calculator to estimate costs. It also added a way to bulk estimate costs for EC2 instances, EC2 Dedicated Hosts, and Amazon EBS services. Try it for yourself today.
Amazon CloudWatch Metrics Insights alarms now enables you to trigger alarms on entire fleets of dynamically changing resources (such as automatically scaling EC2 instances) with a single alarm using standard SQL queries. For example, you can now write a query like this to collect data about CPU utilization over your entire dynamic fleet of EC2 instances.
SELECT AVG(CPUUtilization) FROM SCHEMA("AWS/EC2", InstanceId)AWS Amplify is a command line tool and a set of libraries to help you to build web and mobile applications connected to a cloud backend. We released Amplify Library for Android 2.0, with improvements and simplifications for user authentication. The team also released Amplify JavaScript library version 5, with improvements for React and React Native developers, such as a new notifications channel, also known as in-app messaging, that developers can use to display contextual messages to their users based on their behavior. The Amplify JavaScript library has also received improvements to reduce the overall bundle size and installation size.
Amazon Connect added granular access control based on resource tags for routing profiles, security profiles, users, and queues. It also adds bulk import for user hierarchy tags. This allows you to use attribute-based access control policies for Amazon Connect resources.
Amazon RDS Proxy now supports PostgreSQL major version 14. RDS Proxy is a fully managed, highly available database proxy for Amazon Relational Database Service (Amazon RDS) that makes applications more scalable, more resilient to database failures, and more secure. It is typically used by serverless applications that can have a large number of open connections to the database server and may open and close database connections at a high rate, exhausting database memory and compute resources.
AWS Gateway Load Balancer endpoints now support Ipv6 addresses. You can now send IPv6 traffic through Gateway Load Balancers and its endpoints to distribute traffic flows to dual stack appliance targets.
Amazon Location Service now provides Open Data Maps maps, in addition to ESRI and Here maps. I also noticed that Amazon is a core member of the new Overture Maps Foundation, officially hosted by the Linux Foundation. The mission of the Overture Maps Foundation is to power new map products through openly available datasets that can be used and reused across applications and businesses. The program is driven by Amazon Web Services (AWS), Facebook’s parent company Meta, Microsoft, and Dutch mapping company TomTom.
AWS Mainframe Modernization is a set of managed tools providing infrastructure and software for migrating, modernizing, and running mainframe applications. It is now available in three additional AWS Regions and supports AWS CloudFormation, AWS PrivateLink, AWS Key Management Service.
X in Y. Jeff started this section a while ago to list the expansion of new services and capabilities to additional Regions. I noticed 11 Regional expansions this week:
- Amazon AppStream 2.0 is now available in the South America (São Paulo) Region
- Amazon Neptune Serverless is now available in 5 additional AWS Regions
- Amazon Location Service now available in Asia Pacific (Mumbai), Canada (Central), Europe (London), and South America (São Paulo)
- Amazon Elastic File System (Amazon EFS) is now available in the AWS Europe (Zurich) Region
- Amazon QuickSight is now available in Stockholm and Paris Regions
- Amazon EC2 C6id, M6id, and R6id on one side, and M6a and C6a on the other side are now available in more Regions
- Amazon Kendra now available in Asia-Pacific (Mumbai) AWS Region
- Amazon MQ is now available in the Middle East (UAE) Region
- Contact Lens for Amazon Connect now provides conversational analytics in Africa (Cape Town) Region
- Amazon ECS Service Connect now available in the AWS China (Beijing) and AWS China (Ningxia) Regions
- Amazon GuardDuty now available in AWS Europe (Zurich) Region
Other AWS News
This week, I also noticed these AWS news items:
Amazon SageMaker turned 5 years old 
 . You can read the initial blog post we published at the time. To celebrate the event, the Amazon Science published this article where AWS’s Vice President Bratin Saha reflects on the past and future of AWS’s machine learning tools and AI services.
. You can read the initial blog post we published at the time. To celebrate the event, the Amazon Science published this article where AWS’s Vice President Bratin Saha reflects on the past and future of AWS’s machine learning tools and AI services.
The security blog published a great post about the Cedar policy language. It explains how Amazon Verified Permissions provides a pre-built, flexible permissions system that you can use to build permissions based on both ABAC and RBAC in your applications. Cedar policy language is also at the heart of Amazon Verified Access I blogged about during re:Invent.
And just like every week, my most excellent colleague Ricardo published the open source newsletter.
Upcoming AWS Events
Check your calendars and sign up for these AWS events:
AWS re:Invent recaps in your area. During the re:Invent week, we had lots of new announcements, and in the next weeks, you can find in your area a recap of all these launches. All the events will be posted on this site, so check it regularly to find an event nearby.
AWS re:Invent keynotes, leadership sessions, and breakout sessions are available on demand. I recommend that you check the playlists and find the talks about your favorite topics in one collection.
AWS Summits season will restart in Q2 2023. The dates and locations will be announced here.
Stay Informed
That is my selection for this week! Heads up – the Week in Review will be taking a short break for the end of the year, but we’ll be back with regular updates starting on January 9, 2023. To better keep up with all of this news, do not forget to check out the following resources:
- What’s New with AWS – All AWS announcements. Add the RSS feed to your news reader.
- The Official AWS Podcast – Listen each week for updates on the latest AWS news and deep dives into exciting use cases. There are also official AWS podcasts in your local languages. Check the ones in French, German, Italian, and Spanish.
- AWS News Blog – This blog.
from AWS News Blog https://ift.tt/WRo9xMT
via IFTTT
Wednesday, December 14, 2022
Tuesday, December 13, 2022

Monday, December 12, 2022
AWS Week in Review – December 12, 2022
The world is asynchronous, is what Werner Vogels, Amazon CTO, reminded us during his keynote last week at AWS re:Invent. At the beginning of the keynote, he showed us how weird a synchronous world would be and how everything in nature is asynchronous. One example of an event-driven application he showcased during his keynote is Serverlesspresso, a project my team has been working on for the last year. And last week, we announced Serverlesspresso extensions, a new program that lets you contribute to Serverlesspresso and learn how event-driven applications can be extended.

Last Week’s Launches
Here are some launches that got my attention during the previous week.
Amazon SageMaker Studio now supports fine-grained data access control with AWS LakeFormation when accessing data through Amazon EMR. Now, when you connect to EMR clusters to SageMaker Studio notebooks, you can choose what runtime IAM role you want to connect with, and the notebooks will only access data and resources permitted by the attached runtime role.
Amazon Lex has now added support for Arabic, Cantonese, Norwegian, Swedish, Polish, and Finnish. This opens new possibilities to create chat bots and conversational experiences in more languages.
Amazon RDS Proxy now supports creating proxies in Amazon Aurora Global Database primary and secondary Regions. Now, building multi-Region applications with Amazon Aurora is simpler. RDS proxy sits between your application and the database pool and shares established database connections.
Amazon FSx for NetApp ONTAP launched many new features. First, it added the support for Nitro-based encryption of data in transit. It also extended NVMe read cache support to Single-AZ file systems. And it added four new features to ease the use of the service: easily assign a snapshot policy to your volumes, easily create data protection volumes, configure volumes so their tags are automatically copied to the backups, and finally, add or remove VPC route tables for your existing Multi-AZ file systems.
I would also like to mention two launches that happened before re:Invent but were not covered on the News Blog:
Amazon EventBridge Scheduler is a new capability from Amazon EventBridge that allows you to create, run, and manage scheduled tasks at scale. Using this new capability, you can schedule one-time or recurrent tasks across 270 AWS services.
AWS IoT RoboRunner is now generally available. Last year at re:Invent Channy wrote a blog post introducing the preview for this service. IoT RoboRunner is a robotic service that makes it easier to build and deploy applications for fleets of robots working seamlessly together.
For a full list of AWS announcements, be sure to keep an eye on the What's New at AWS page.Other AWS News
Some other updates and news that you may have missed:
I would like to recommend this really interesting Amazon Science article about federated learning. This is a framework that allows edge devices to work together to train a global model while keeping customers’ data on-device.
Podcast Charlas Técnicas de AWS – If you understand Spanish, this podcast is for you. Podcast Charlas Técnicas is one of the official AWS podcasts in Spanish, and every other week there is a new episode. Today the final episode for season three launched, and in it, we discussed many of the re:Invent launches. You can listen to all the episodes directly from your favorite podcast app or at AWS Podcasts en español.
AWS open-source news and updates–This is a newsletter curated by my colleague Ricardo to bring you the latest open-source projects, posts, events, and more.
Upcoming AWS Events
Check your calendars and sign up for these AWS events:
AWS Resiliency Hub Activation Day is a half-day technical virtual session to deep dive into the features and functionality of Resiliency Hub. You can register for free here.
AWS re:Invent recaps in your area. During the re:Invent week, we had lots of new announcements, and in the next weeks you can find in your area a recap of all these launches. All the events will be posted on this site, so check it regularly to find an event nearby.
AWS re:Invent keynotes, leadership sessions, and breakout sessions are available on demand. I recommend that you check the playlists and find the talks about your favorite topics in one collection.
That’s all for this week. Check back next Monday for another Week in Review!
— Marcia
from AWS News Blog https://ift.tt/OBPhkMq
via IFTTT
Tuesday, December 6, 2022

Thursday, December 1, 2022

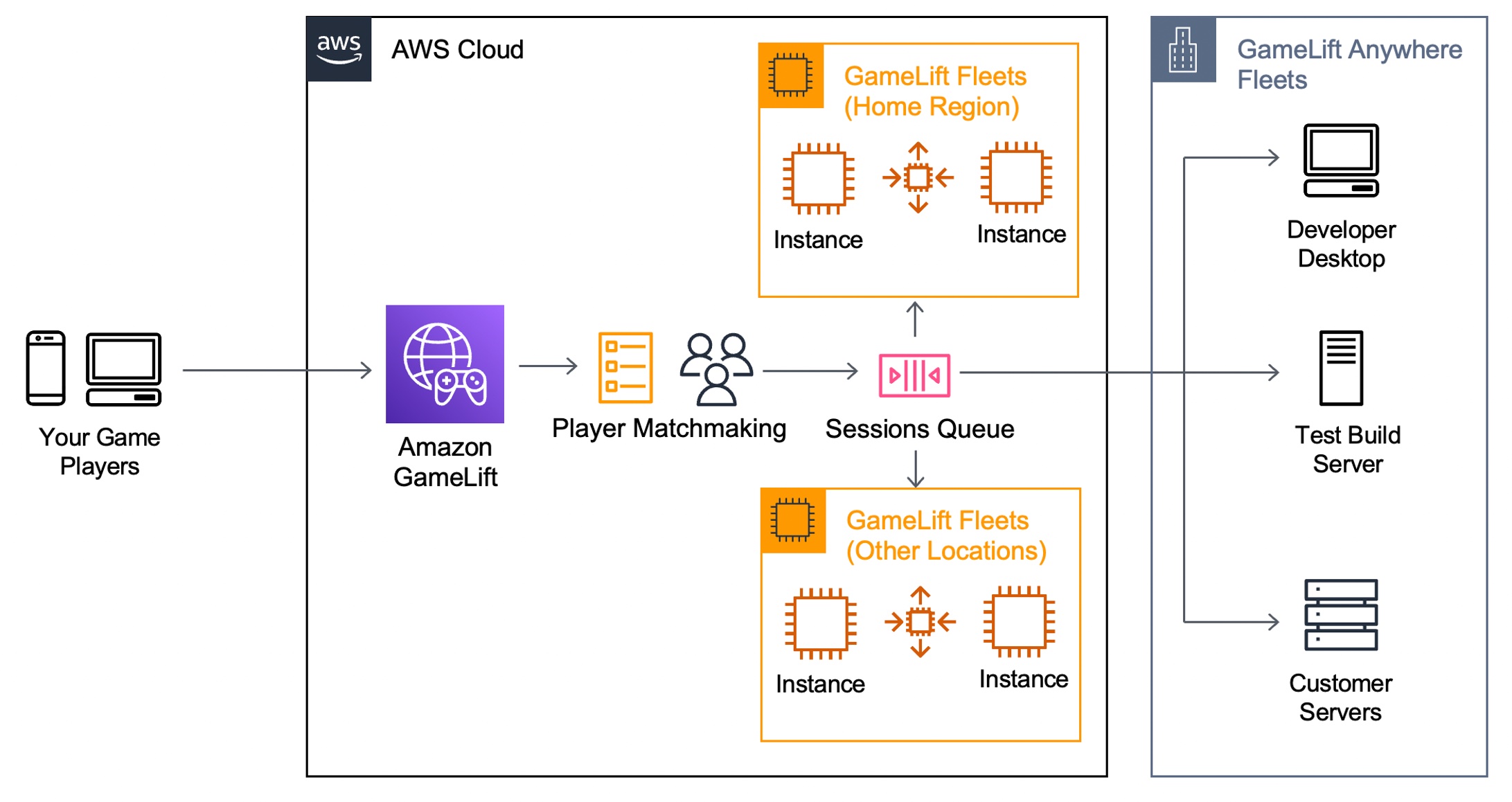
New — Create Point-to-Point Integrations Between Event Producers and Consumers with Amazon EventBridge Pipes
It is increasingly common to use multiple cloud services as building blocks to assemble a modern event-driven application. Using purpose-built services to accomplish a particular task ensures developers get the best capabilities for their use case. However, communication between services can be difficult if they use different technologies to communicate, meaning that you need to learn the nuances of each service and how to integrate them with each other. We usually need to create integration code (or “glue” code) to connect and bridge communication between services. Writing glue code slows our velocity, increases the risk of bugs, and means we spend our time writing undifferentiated code rather than building better experiences for our customers.
Introducing Amazon EventBridge Pipes
Today, I’m excited to announce Amazon EventBridge Pipes, a new feature of Amazon EventBridge that makes it easier for you to build event-driven applications by providing a simple, consistent, and cost-effective way to create point-to-point integrations between event producers and consumers, removing the need to write undifferentiated glue code.

The simplest pipe consists of a source and a target. An optional filtering step allows only specific source events to flow into the Pipe and an optional enrichment step using AWS Lambda, AWS Step Functions, Amazon EventBridge API Destinations, or Amazon API Gateway enriches or transforms events before they reach the target. With Amazon EventBridge Pipes, you can integrate supported AWS and self-managed services as event producers and event consumers into your application in a simple, reliable, consistent and cost-effective way.
Amazon EventBridge Pipes bring the most popular features of Amazon EventBridge Event Bus, such as event filtering, integration with more than 14 AWS services, and automatic delivery retries.
How Amazon EventBridge Pipes Works
Amazon EventBridge Pipes provides you a seamless means of integrating supported AWS and self-managed services, favouring configuration over code. To start integrating services with EventBridge Pipes, you need to take the following steps:
- Choose a source that is producing your events. Supported sources include: Amazon DynamoDB, Amazon Kinesis Data Streams, Amazon SQS, Amazon Managed Streaming for Apache Kafka, and Amazon MQ (both ActiveMQ and RabbitMQ).
- (Optional) Specify an event filter to only process events that match your filter (you’re not charged for events that are filtered out).
- (Optional) Transform and enrich your events using built-in free transformations, or AWS Lambda, AWS Step Functions, Amazon API Gateway, or EventBridge API Destinations to perform more advanced transformations and enrichments.
- Choose a target destination from more than 14 AWS services, including Amazon Step Functions, Kinesis Data Streams, AWS Lambda, and third-party APIs using EventBridge API destinations.
Amazon EventBridge Pipes provides simplicity to accelerate development velocity by reducing the time needed to learn the services and write integration code, to get reliable and consistent integration.

EventBridge Pipes also comes with additional features that can help in building event-driven applications. For example, with event filtering, Pipes helps event-driven applications become more cost-effective by only processing the events of interest.
Get Started with Amazon EventBridge Pipes
Let’s see how to get started with Amazon EventBridge Pipes. In this post, I will show how to integrate an Amazon SQS queue with AWS Step Functions using Amazon EventBridge Pipes.
The following screenshot is my existing Amazon SQS queue and AWS Step Functions state machine. In my case, I need to run the state machine for every event in the queue. To do so, I need to connect my SQS queue and Step Functions state machine with EventBridge Pipes.

First, I open the Amazon EventBridge console. In the navigation section, I select Pipes. Then I select Create pipe.
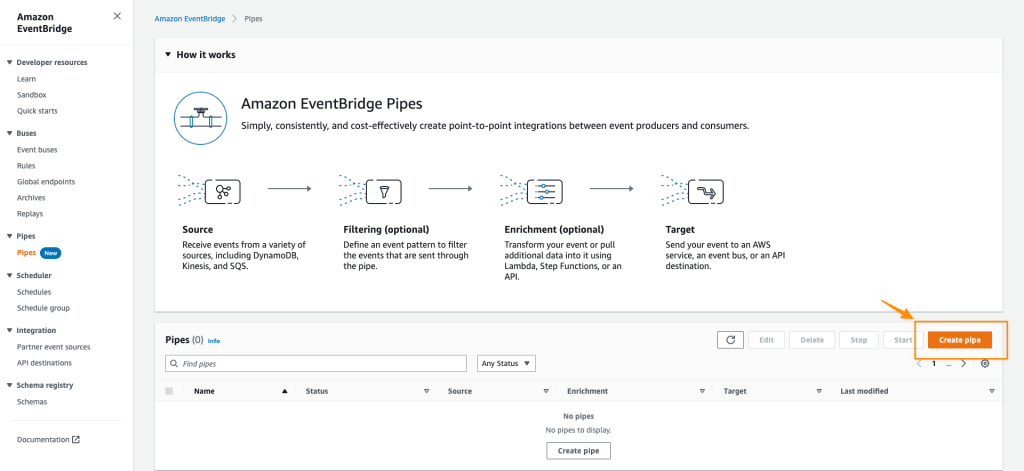
On this page, I can start configuring a pipe and set the AWS Identity and Access Management (IAM) permission, and I can navigate to the Pipe settings tab.

In the Permissions section, I can define a new IAM role for this pipe or use an existing role. To improve developer experience, the EventBridge Pipes console will figure out the IAM role for me, so I don’t need to manually configure required permissions and let EventBridge Pipes configures least-privilege permissions for IAM role. Since this is my first time creating a pipe, I select Create a new role for this specific resource.

Then, I go back to the Build pipe section. On this page, I can see the available event sources supported by EventBridge Pipes.

I select SQS and select my existing SQS queue. If I need to do batch processing, I can select Additional settings to start defining Batch size and Batch window. Then, I select Next.

On the next page, things get even more interesting because I can define Event filtering from the event source that I just selected. This step is optional, but the event filtering feature makes it easy for me to process events that only need to be processed by my event-driven application. In addition, this event filtering feature also helps me to be more cost-effective, as this pipe won’t process unnecessary events. For example, if I use Step Functions as the target, the event filtering will only execute events that match the filter.

I can use sample events from AWS events or define custom events. For example, I want to process events for returned purchased items with a value of 100 or more. The following is the sample event in JSON format:
{
"event-type":"RETURN_PURCHASE",
"value":100
}Then, in the event pattern section, I can define the pattern by referring to the Content filtering in Amazon EventBridge event patterns documentation. I define the event pattern as follows:
{
"event-type": ["RETURN_PURCHASE"],
"value": [{
"numeric": [">=", 100]
}]
}I can also test by selecting test pattern to make sure this event pattern will match the custom event I’m going to use. Once I’m confident that this is the event pattern that I want, I select Next.

In the next optional step, I can use an Enrichment that will augment, transform, or expand the event before sending the event to the target destination. This enrichment is useful when I need to enrich the event using an existing AWS Lambda function, or external SaaS API using the Destination API. Additionally, I can shape the event using the Enrichment Input Transformer.

The final step is to define a target for processing the events delivered by this pipe.

Here, I can select various AWS services supported by EventBridge Pipes.

I select my existing AWS Step Functions state machine, named pipes-statemachine.

In addition, I can also use Target Input Transformer by referring to the Transforming Amazon EventBridge target input documentation. For my case, I need to define a high priority for events going into this target. To do that, I define a sample custom event in Sample events/Event Payload and add the priority: HIGH in the Transformer section. Then in the Output section, I can see the final event to be passed to the target destination service. Then, I select Create pipe.

In less than a minute, my pipe was successfully created.

To test this pipe, I need to put an event into the Amaon SQS queue.

To check if my event is successfully processed by Step Functions, I can look into my state machine in Step Functions. On this page, I see my event is successfully processed.

I can also go to Amazon CloudWatch Logs to get more detailed logs.

Things to Know
Event Sources – At launch, Amazon EventBridge Pipes supports the following services as event sources: Amazon DynamoDB, Amazon Kinesis, Amazon Managed Streaming for Apache Kafka (Amazon MSK) alongside self-managed Apache Kafka, Amazon SQS (standard and FIFO), and Amazon MQ (both for ActiveMQ and RabbitMQ).
Event Targets – Amazon EventBridge Pipes supports 15 Amazon EventBridge targets, including AWS Lambda, Amazon API Gateway, Amazon SNS, Amazon SQS, and AWS Step Functions. To deliver events to any HTTPS endpoint, developers can use API destinations as the target.
Event Ordering – EventBridge Pipes maintains the ordering of events received from an event sources that support ordering when sending those events to a destination service.
Programmatic Access – You can also interact with Amazon EventBridge Pipes and create a pipe using AWS Command Line Interface (CLI), AWS CloudFormation, and AWS Cloud Development Kit (AWS CDK).
Independent Usage – EventBridge Pipes can be used separately from Amazon EventBridge bus and Amazon EventBridge Scheduler. This flexibility helps developers to define source events from supported AWS and self-managed services as event sources without Amazon EventBridge Event Bus.
Availability – Amazon EventBridge Pipes is now generally available in all AWS commercial Regions, with the exception of Asia Pacific (Hyderabad) and Europe (Zurich).
Visit the Amazon EventBridge Pipes page to learn more about this feature and understand the pricing. You can also visit the documentation page to learn more about how to get started.
Happy building!
— Donnie
from AWS News Blog https://ift.tt/yoDib8P
via IFTTT
Step Functions Distributed Map – A Serverless Solution for Large-Scale Parallel Data Processing
I am excited to announce the availability of a distributed map for AWS Step Functions. This flow extends support for orchestrating large-scale parallel workloads such as the on-demand processing of semi-structured data.
Step Function’s map state executes the same processing steps for multiple entries in a dataset. The existing map state is limited to 40 parallel iterations at a time. This limit makes it challenging to scale data processing workloads to process thousands of items (or even more) in parallel. In order to achieve higher parallel processing prior to today, you had to implement complex workarounds to the existing map state component.
The new distributed map state allows you to write Step Functions to coordinate large-scale parallel workloads within your serverless applications. You can now iterate over millions of objects such as logs, images, or .csv files stored in Amazon Simple Storage Service (Amazon S3). The new distributed map state can launch up to ten thousand parallel workflows to process data.
You can process data by composing any service API supported by Step Functions, but typically, you will invoke Lambda functions to process the data with code written in your favorite programming language.
Step Functions distributed map supports a maximum concurrency of up to 10,000 executions in parallel, which is well above the concurrency supported by many other AWS services. You can use the maximum concurrency feature of the distributed map to ensure that you do not exceed the concurrency of a downstream service. There are two factors to consider when working with other services. First, the maximum concurrency supported by the service for your account. Second, the burst and ramping rates, which determine how quickly you can achieve the maximum concurrency.
Let’s use Lambda as an example. Your functions’ concurrency is the number of instances that serve requests at a given time. The default maximum concurrency quota for Lambda is 1,000 per AWS Region. You can ask for an increase at any time. For an initial burst of traffic, your functions’ cumulative concurrency in a Region can reach an initial level of between 500 and 3000, which varies per Region. The burst concurrency quota applies to all your functions in the Region.
When using a distributed map, be sure to verify the quota on downstream services. Limit the distributed map maximum concurrency during your development, and plan for service quota increases accordingly.
To compare the new distributed map with the original map state flow, I created this table.
| Original map state flow | New distributed map flow | |
| Sub workflows |
|
|
| Parallel branches | Map iterations run in parallel, with an effective maximum concurrency of around 40 at a time. | Can pass millions of items to multiple child executions, with concurrency of up to 10,000 executions at a time. |
| Input source | Accepts only a JSON array as input. | Accepts input as Amazon S3 object list, JSON arrays or files, csv files, or Amazon S3 inventory. |
| Payload | 256 KB | Each iteration receives a reference to a file (Amazon S3) or a single record from a file (state input). Actual file processing capability is limited by Lambda storage and memory. |
| Execution history | 25,000 events | Each iteration of the map state is a child execution, with up to 25,000 events each (express mode has no limit on execution history). |
Sub-workflows within a distributed map work with both Standard workflows and the low-latency, short-duration Express Workflows.
This new capability is optimized to work with S3. I can configure the bucket and prefix where my data are stored directly from the distributed map configuration. The distributed map stops reading after 100 million items and supports JSON or csv files of up to 10GB.
When processing large files, think about downstream service capabilities. Let’s take Lambda again as an example. Each input—a file on S3, for example—must fit within the Lambda function execution environment in terms of temporary storage and memory. To make it easier to handle large files, Lambda Powertools for Python introduced a new streaming feature to fetch, transform, and process S3 objects with minimal memory footprint. This allows your Lambda functions to handle files larger than the size of their execution environment. To learn more about this new capability, check the Lambda Powertools documentation.
Let’s See It in Action
For this demo, I will create a workflow that processes one thousand dog images stored on S3. The images are already stored on S3.
➜ ~ aws s3 ls awsnewsblog-distributed-map/images/
2022-11-08 15:03:36 27034 n02085620_10074.jpg
2022-11-08 15:03:36 34458 n02085620_10131.jpg
2022-11-08 15:03:36 12883 n02085620_10621.jpg
2022-11-08 15:03:36 34910 n02085620_1073.jpg
...
➜ ~ aws s3 ls awsnewsblog-distributed-map/images/ | wc -l
1000The workflow and the S3 bucket must be in the same Region.
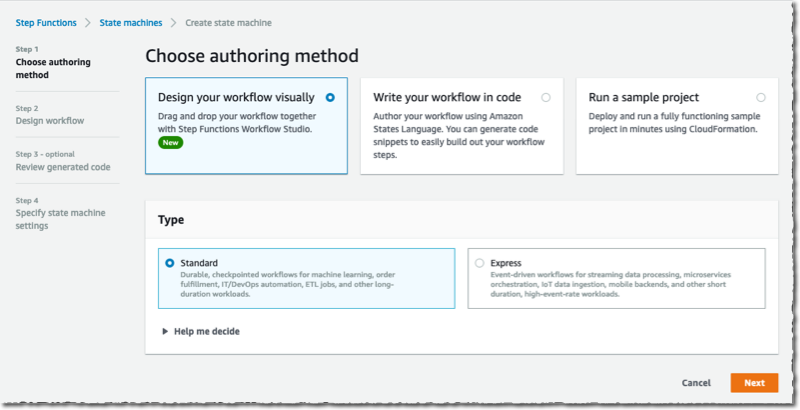
To get started, I navigate to the Step Functions page of the AWS Management Console and select Create state machine. On the next page, I choose to design my workflow using the visual editor. The distributed map works with Standard workflows, and I keep the default selection as-is. I select Next to enter the visual editor.
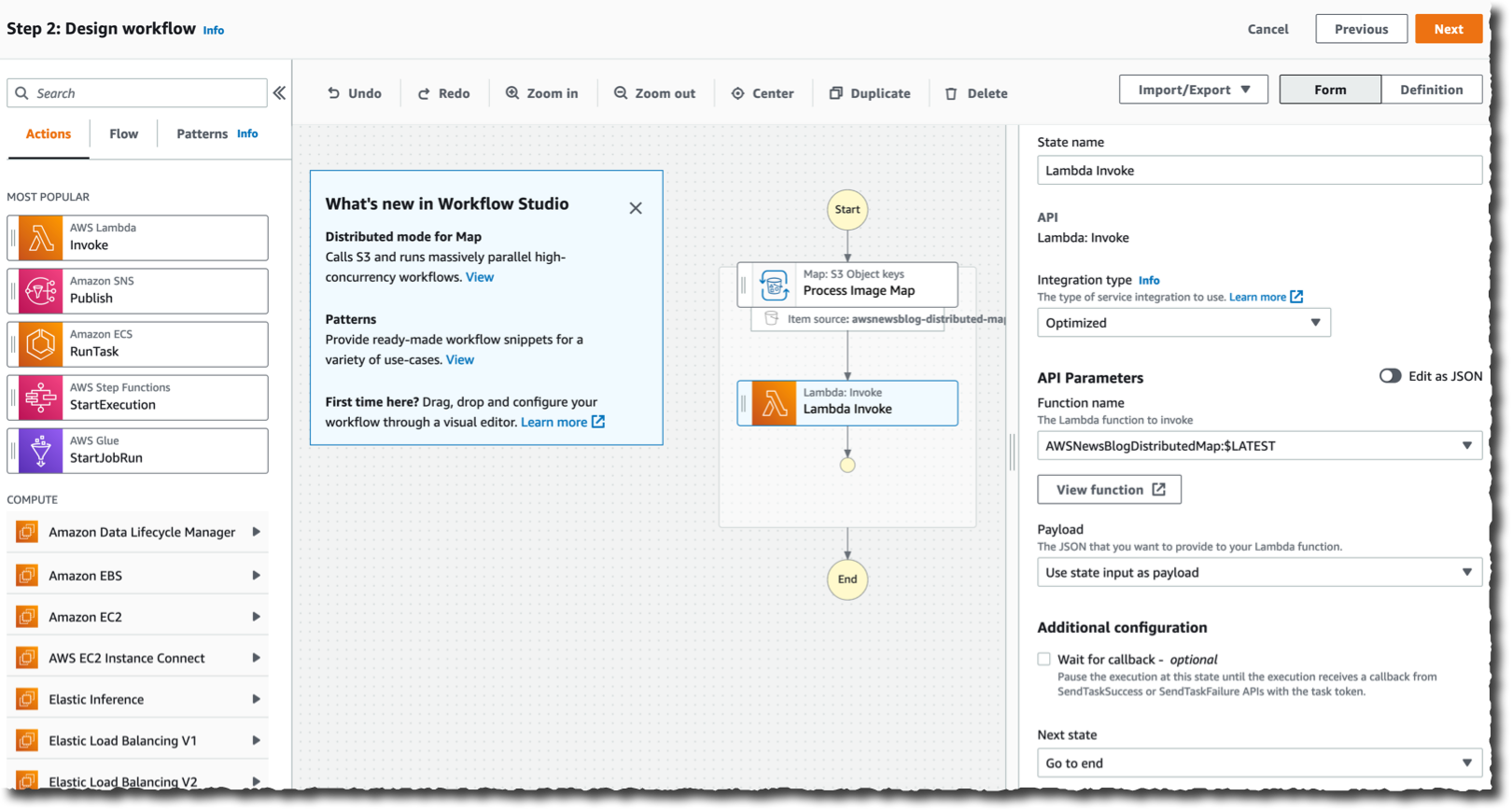
 In the visual editor, I search and select the Map component on the left-side pane, and I drag it to the workflow area. On the right side, I configure the component. I choose Distributed as Processing mode and Amazon S3 as Item Source.
In the visual editor, I search and select the Map component on the left-side pane, and I drag it to the workflow area. On the right side, I configure the component. I choose Distributed as Processing mode and Amazon S3 as Item Source.
Distributed maps are natively integrated with S3. I enter the name of the bucket (awsnewsblog-distributed-map) and the prefix (images) where my images are stored.
 On the Runtime Settings section, I choose Express for Child workflow type. I also may decide to restrict the Concurrency limit. It helps to ensure we operate within the concurrency quotas of the downstream services (Lambda in this demo) for a particular account or Region.
On the Runtime Settings section, I choose Express for Child workflow type. I also may decide to restrict the Concurrency limit. It helps to ensure we operate within the concurrency quotas of the downstream services (Lambda in this demo) for a particular account or Region.
By default, the output of my sub-workflows will be aggregated as state output, up to 256KB. To process larger outputs, I may choose to Export map state results to Amazon S3.

Finally, I define what to do for each file. In this demo, I want to invoke a Lambda function for each file in the S3 bucket. The function exists already. I search for and select the Lambda invocation action on the left-side pane. I drag it to the distributed map component. Then, I use the right-side configuration panel to select the actual Lambda function to invoke: AWSNewsBlogDistributedMap in this example.
When I am done, I select Next. I select Next again on the Review generated code page (not shown here).
On the Specify state machine settings page, I enter a Name for my state machine and the IAM Permissions to run. Then, I select Create state machine.
 Now I am ready to start the execution. On the State machine page, I select the new workflow and select Start execution. I can optionally enter a JSON document to pass to the workflow. In this demo, the workflow does not handle the input data. I leave it as-is, and I select Start execution.
Now I am ready to start the execution. On the State machine page, I select the new workflow and select Start execution. I can optionally enter a JSON document to pass to the workflow. In this demo, the workflow does not handle the input data. I leave it as-is, and I select Start execution.
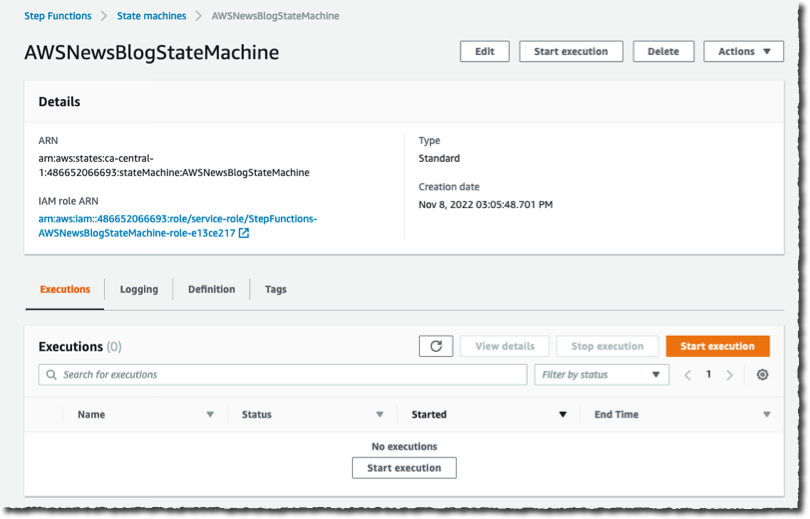 |
 |
During the execution of the workflow, I can monitor the progress. I observe the number of iterations, and the number of items successfully processed or in error.
 I can drill down on one specific execution to see the details.
I can drill down on one specific execution to see the details.
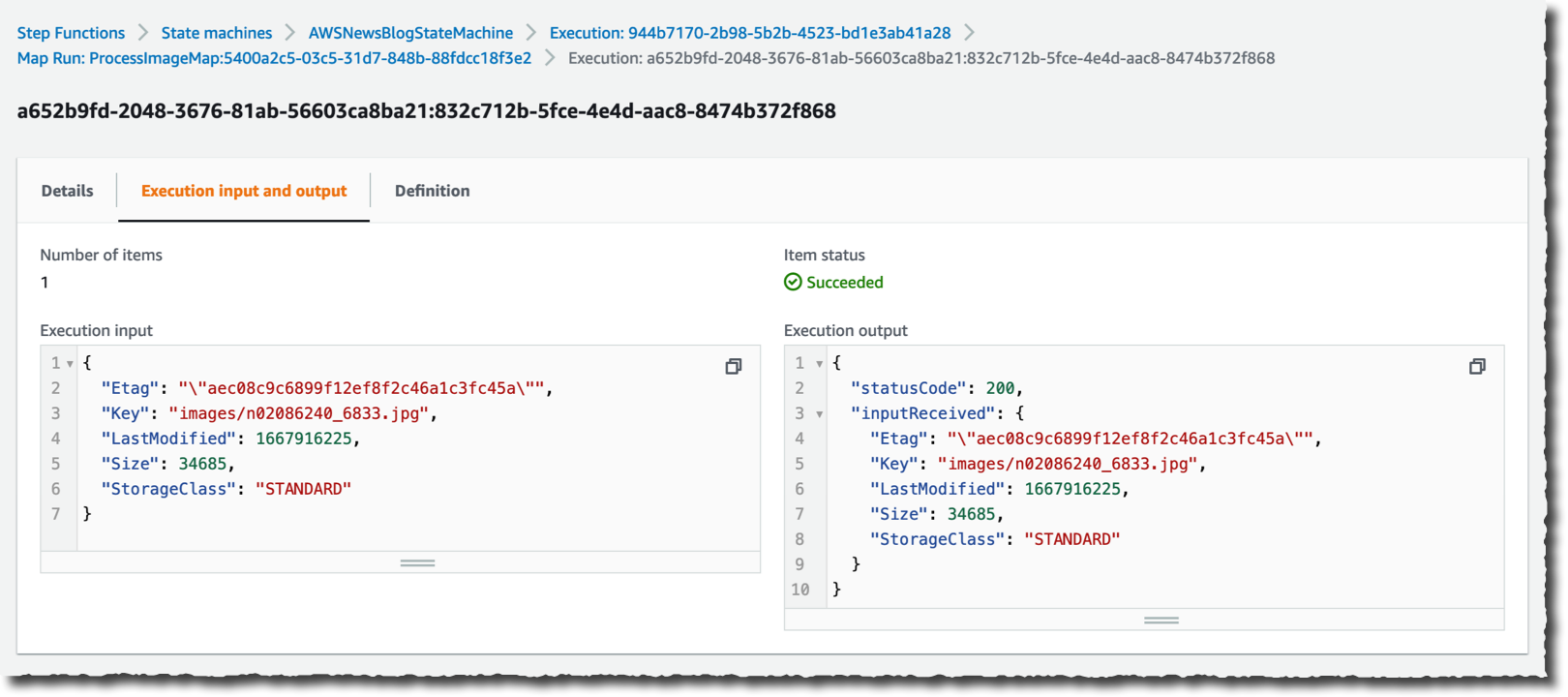
With just a few clicks, I created a large-scale and heavily parallel workflow able to handle a very large quantity of data.
Which AWS Service Should I Use
As often happens on AWS, you might observe an overlap between this new capability and existing services such as AWS Glue, Amazon EMR, or Amazon S3 Batch Operations. Let’s try to differentiate the use cases.
In my mental model, data scientists and data engineers use AWS Glue and EMR to process large amounts of data. On the other hand, application developers will use Step Functions to add serverless data processing into their applications. Step Functions is able to scale from zero quickly, which makes it a good fit for interactive workloads where customers may be waiting for the results. Finally, system administrators and IT operation teams are likely to use Amazon S3 Batch Operations for single-step IT automation operations such as copying, tagging, or changing permissions on billions of S3 objects.
Pricing and Availability
AWS Step Functions’ distributed map is generally available in the following ten AWS Regions: US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Singapore, Sydney, Tokyo), Canada (Central), and Europe (Frankfurt, Ireland, Stockholm).
The pricing model for the existing inline map state does not change. For the new distributed map state, we charge one state transition per iteration. Pricing varies between Regions, and it starts at $0.025 per 1,000 state transitions. When you process your data using express workflows, you are also charged based on the number of requests for your workflow and its duration. Again, prices vary between Regions, but they start at $1.00 per 1 million requests and $0.06 per GB-hour (prorated to 100ms).
For the same amount of iterations, you will observe a cost reduction when using the combination of the distributed map and standard workflows compared to the existing inline map. When you use express workflows, expect the costs to stay the same for more value with the distributed map.
I am really excited to discover what you will build using this new capability and how it will unlock innovation. Go start to build highly parallel serverless data processing workflows today!
-- sebfrom AWS News Blog https://ift.tt/Zcd3wvC
via IFTTT
Subscribe to:
Comments (Atom)