Friday, April 28, 2023
Introducing Athena Provisioned Capacity
Today we launch the ability to provision capacity to run your Amazon Athena queries.
Athena is a query service that makes it simple to analyze data in Amazon Simple Storage Service (Amazon S3) data lakes and 30 different data sources, including on-premises data sources or other cloud systems, using standard SQL queries. Athena is serverless, so there is no infrastructure to manage, and–until today–you pay only for the queries that you run. Starting today, you can get dedicated capacity for your queries and use new workload management features to prioritize, control, and scale your most important queries, paying only for the capacity you provision.
At AWS, 90 percent of the new services and features are driven by your direct feedback. Many of you Athena customers told us that, when running a large volume of queries, you sometimes experience queuing, which might slow down some applications or business processes. To work around this, you typically create a query prioritization mechanism to prioritize mission-critical queries over less critical, interactive, or exploratory queries. This prioritization mechanism helps to get the highest priority queries run first, at the price of building and maintaining code or business processes outside of Athena itself. You also told us it is difficult to forecast your Athena costs. Athena charges by the volume of data scanned, which is often difficult to predict as it depends on the size of your data set, the construction of the user queries, and the storage format for the data.
We heard this feedback, and today, we introduce the capability to provision dedicated query processing capacity at scale. With provisioned capacity, you provision a dedicated set of compute resources to run your queries. This always-on capacity can serve your business-critical queries with near-zero latency and no queuing. It gives you control over workload performance characteristics such as cost, concurrency, and query prioritization. Similar to provisioned capacity for other AWS services, you pay only for the capacity provisioned, not for the actual usage. With provisioned capacity, your Athena bills are predictable, and you do not have to limit user queries to stay within your monthly budget. I’ll share more about the billing model down below.
Behind the scenes, Athena maintains a large pool of compute in each AWS Region that it operates in. You can think of this as one large pool of compute, divided logically across customers. When you reserve capacity in Athena, the capacity is held for your exclusive use. You can choose which queries run on the capacity you provisioned and which run on Athena’s multi-tenant, on-demand capacity. Multiple queries can share the capacity you provisioned. You may add additional capacity units at any time, based on your evolving business requirements. You may also adjust the provisioned capacity down after a minimum period of time of 8 hours.
The unit of capacity is a Data Processing Unit (DPU). A single DPU is equivalent to four vCPU and 16 Gb RAM. The minimum capacity you may provision is 24 DPU for 8 hours. This new provisioned capacity for Athena is ideal for those of you running any volume of queries, but the sweet spot to start using provisioned capacity is when you spend $100 or more per month on Athena.
The number of DPUs you need depends on your goals and analysis patterns. For example, if you need queries to start immediately and without queuing, you should provision enough DPUs to meet your peak concurrent query demand. Provisioning fewer DPUs than your peak demand is allowed, but may result in queuing. When this occurs, queries are held in a queue and executed when capacity is available. If your goal is to run queries within a fixed budget, you can use the AWS Pricing Calculator to determine the number of DPUs that meets your budget. Lastly, remember that data size, storage format, and query construction influence the number of DPU a query requires. You can increase query performance by compressing, partitioning, and converting your data into columnar formats. Athena’s documentation provides you with guidelines to determine how much capacity you might require to run multiple queries at the same time.
How Does It Work?
Getting started is a three-step process. I navigate to the Athena page in the AWS Management Console and select Capacity Reservations on the left-side navigation menu.
(The console you see on this demo is based on the new Cloudscape open-source design system, yours might still see the traditional design on your AWS account.)

I select the Create capacity reservation button at the top right of the page.
On the Create capacity reservation page, I enter a Capacity reservation name and the number of DPUs I want to provision.
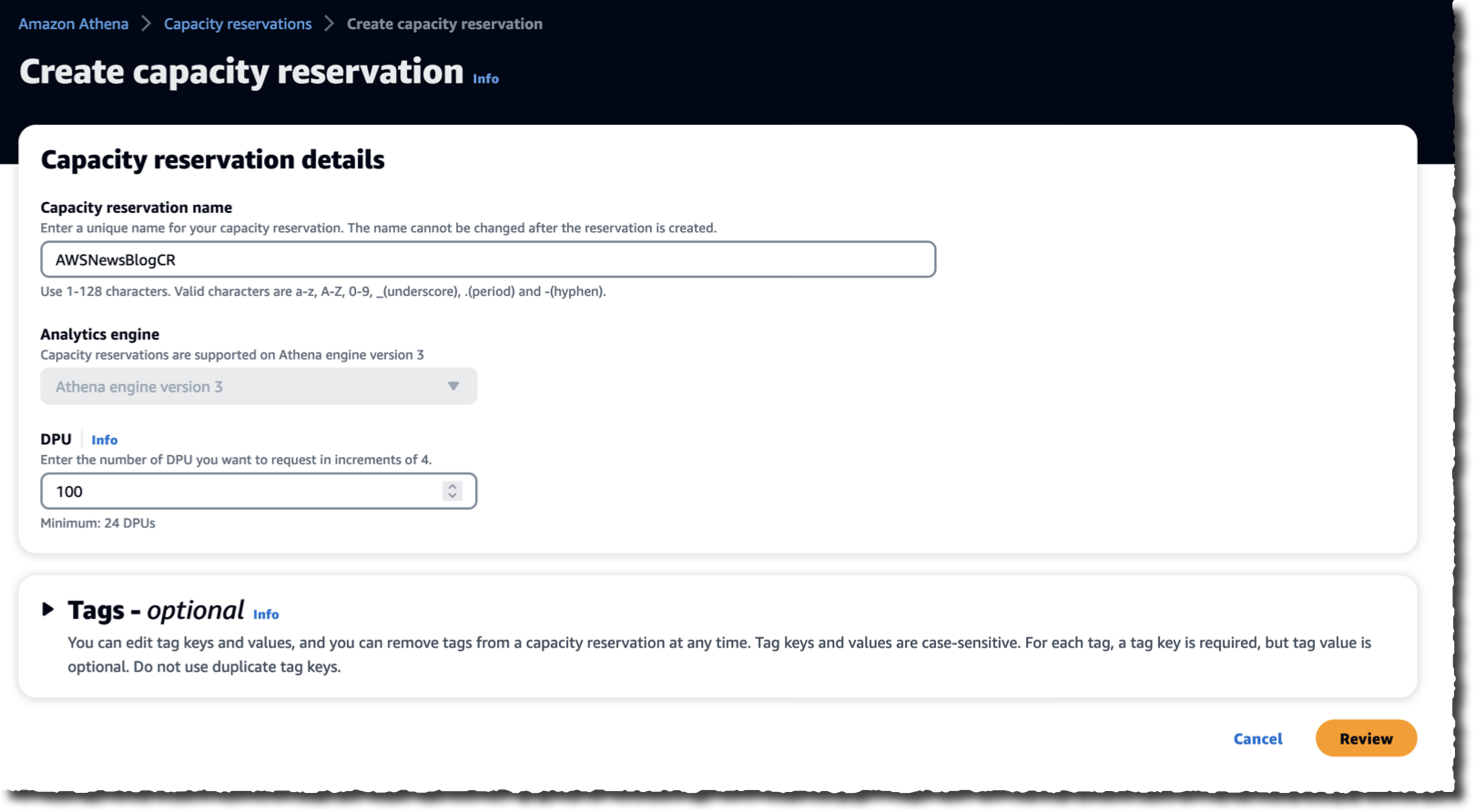
I select Review to review my choices, and I select Create capacity reservation to create my reservation. After a brief period of time, the capacity reservation status becomes  Active.
Active.

The third and last step is to create a workgroup and assign the workgroup to the provisioned capacity. A workgroup is an Athena mechanism allowing you to separate users, teams, applications, or workloads to set limits on the amount of data each query or the entire workgroup can process and to track costs.
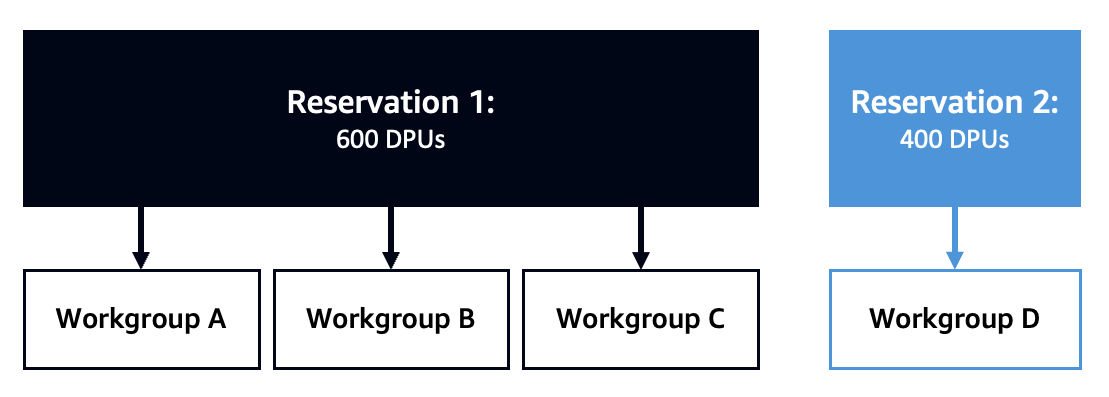
Queries belonging to the assigned workgroup will run on the capacity you provisioned. Capacity may be shared with multiple workgroups as long as they all use the same Athena engine version. This concept, depicted in the diagram below, is surfaced through a capacity allocation policy, which defines how capacity is assigned over workgroups. This gives you the flexibility to run queries with more or less capacity, depending on your business needs.
To create a workgroup, I navigate to the Workgroups section of the Athena page. Then, I select Create workgroup.

I make sure the analytics engine selected in the reservation matches the one in the workgroup.
 Then, I go back to the capacity reservation I just created, and I select Add workgroups to add the workgroup I just created.
Then, I go back to the capacity reservation I just created, and I select Add workgroups to add the workgroup I just created.

That’s it! Now that the configuration is ready, I can run my queries. Existing queries will run on the provisioned capacity unmodified. I make sure to select the workgroup I just created when I run queries. I choose a workgroup on the top right side of the query editor, or use the --work-group argument on the AWS command line, such as:
aws athena start-query-execution --work-group AWSNewsBlog
Availability and Pricing
As I explained in the introduction, we charge for the number of DPUs you provisioned and the duration. The minimum duration is 8 hours, and after that, billing is per minute. You can release the provisioned capacity at any time. Cancellations within the minimum duration period are billed for the full term, and capacity is deallocated as soon as all currently running queries are terminated.
Queries run from a workgroup assigned to a provisioned capacity are not billed for the amount of data scanned. You effectively pay a flat rate depending on the provisioned capacity, not the usage. If you have excess capacity, you can reduce the number of DPUs you provisioned or add workgroups to consume the excess capacity.
As usual, the Athena pricing page has all the details.
Athena provisioned capacity is available today in US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Singapore, Sydney, Tokyo), and Europe (Ireland, Stockholm) AWS Regions.
Go and provision your Athena capacity today!
-- sebfrom AWS News Blog https://ift.tt/1iIdpS5
via IFTTT
Thursday, April 27, 2023
How CyberCRX cut ML processing time from 8 days to 56 minutes with AWS Step Functions Distributed Map

How CyberCRX cut ML processing time from 8 days to 56 minutes with AWS Step Functions Distributed Map
Last December, Sébastien Stormacq wrote about the availability of a distributed map state for AWS Step Functions, a new feature that allows you to orchestrate large-scale parallel workloads in the cloud. That’s when Charles Burton, a data systems engineer for a company called CyberGRX, found out about it and refactored his workflow, reducing the processing time for his machine learning (ML) processing job from 8 days to 56 minutes. Before, running the job required an engineer to constantly monitor it; now, it runs in less than an hour with no support needed. In addition, the new implementation with AWS Step Functions Distributed Map costs less than what it did originally.
What CyberGRX achieved with this solution is a perfect example of what serverless technologies embrace: letting the cloud do as much of the undifferentiated heavy lifting as possible so the engineers and data scientists have more time to focus on what’s important for the business. In this case, that means continuing to improve the model and the processes for one of the key offerings from CyberGRX, a cyber risk assessment of third parties using ML insights from its large and growing database.
What’s the business challenge?
CyberGRX shares third-party cyber risk (TPCRM) data with their customers. They predict, with high confidence, how a third-party company will respond to a risk assessment questionnaire. To do this, they have to run their predictive model on every company in their platform; they currently have predictive data on more than 225,000 companies. Whenever there’s a new company or the data changes for a company, they regenerate their predictive model by processing their entire dataset. Over time, CyberGRX data scientists improve the model or add new features to it, which also requires the model to be regenerated.
The challenge is running this job for 225,000 companies in a timely manner, with as few hands-on resources as possible. The job runs a set of operations for each company, and every company calculation is independent of other companies. This means that in the ideal case, every company can be processed at the same time. However, implementing such a massive parallelization is a challenging problem to solve.
First iteration
With that in mind, the company built their first iteration of the pipeline using Kubernetes and Argo Workflows, an open-source container-native workflow engine for orchestrating parallel jobs on Kubernetes. These were tools they were familiar with, as they were already using them in their infrastructure.
But as soon as they tried to run the job for all the companies on the platform, they ran up against the limits of what their system could handle efficiently. Because the solution depended on a centralized controller, Argo Workflows, it was not robust, and the controller was scaled to its maximum capacity during this time. At that time, they only had 150,000 companies. And running the job with all of the companies took around 8 days, during which the system would crash and need to be restarted. It was very labor intensive, and it always required an engineer on call to monitor and troubleshoot the job.
The tipping point came when Charles joined the Analytics team at the beginning of 2022. One of his first tasks was to do a full model run on approximately 170,000 companies at that time. The model run lasted the whole week and ended at 2:00 AM on a Sunday. That’s when he decided their system needed to evolve.
Second iteration
With the pain of the last time he ran the model fresh in his mind, Charles thought through how he could rewrite the workflow. His first thought was to use AWS Lambda and SQS, but he realized that he needed an orchestrator in that solution. That’s why he chose Step Functions, a serverless service that helps you automate processes, orchestrate microservices, and create data and ML pipelines; plus, it scales as needed.
Charles got the new version of the workflow with Step Functions working in about 2 weeks. The first step he took was adapting his existing Docker image to run in Lambda using Lambda’s container image packaging format. Because the container already worked for his data processing tasks, this update was simple. He scheduled Lambda provisioned concurrency to make sure that all functions he needed were ready when he started the job. He also configured reserved concurrency to make sure that Lambda would be able to handle this maximum number of concurrent executions at a time. In order to support so many functions executing at the same time, he raised the concurrent execution quota for Lambda per account.
And to make sure that the steps were run in parallel, he used Step Functions and the map state. The map state allowed Charles to run a set of workflow steps for each item in a dataset. The iterations run in parallel. Because Step Functions map state offers 40 concurrent executions and CyberGRX needed more parallelization, they created a solution that launched multiple state machines in parallel; in this way, they were able to iterate fast across all the companies. Creating this complex solution, required a preprocessor that handled the heuristics of the concurrency of the system and split the input data across multiple state machines.
This second iteration was already better than the first one, as now it was able to finish the execution with no problems, and it could iterate over 200,000 companies in 90 minutes. However, the preprocessor was a very complex part of the system, and it was hitting the limits of the Lambda and Step Functions APIs due to the amount of parallelization.

Third and final iteration
Then, during AWS re:Invent 2022, AWS announced a distributed map for Step Functions, a new type of map state that allows you to write Step Functions to coordinate large-scale parallel workloads. Using this new feature, you can easily iterate over millions of objects stored in Amazon Simple Storage Service (Amazon S3), and then the distributed map can launch up to 10,000 parallel sub-workflows to process the data.
When Charles read in the News Blog article about the 10,000 parallel workflow executions, he immediately thought about trying this new state. In a couple of weeks, Charles built the new iteration of the workflow.
Because the distributed map state split the input into different processors and handled the concurrency of the different executions, Charles was able to drop the complex preprocessor code.
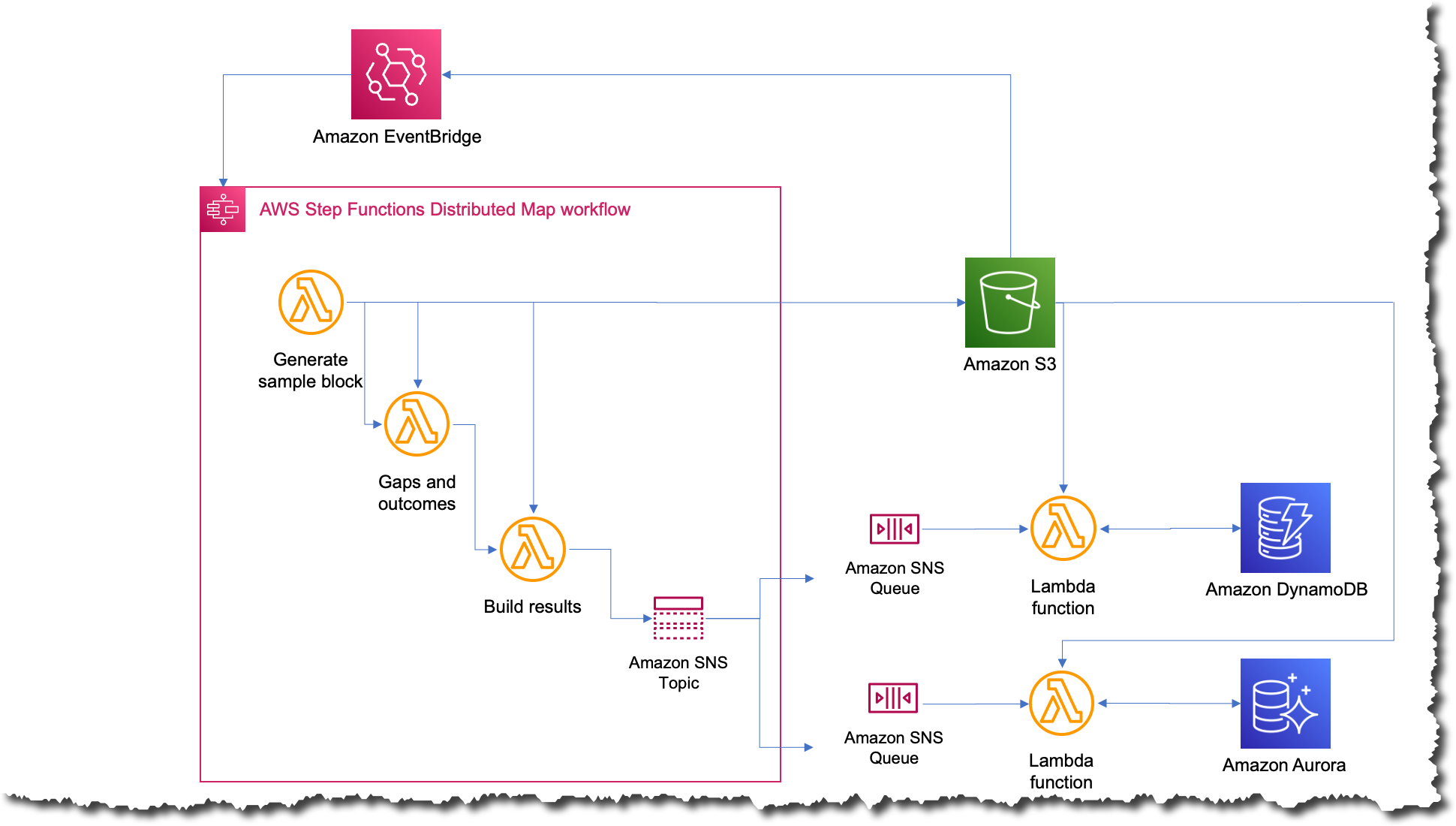
The new process was the simplest that it’s ever been; now whenever they want to run the job, they just upload a file to Amazon S3 with the input data. This action triggers an Amazon EventBridge rule that targets the state machine with the distributed map. The state machine then executes with that file as an input and publishes the results to an Amazon Simple Notification Service (Amazon SNS) topic.
What was the impact?
A few weeks after completing the third iteration, they had to run the job on all 227,000 companies in their platform. When the job finished, Charles’ team was blown away; the whole process took only 56 minutes to complete. They estimated that during those 56 minutes, the job ran more than 57 billion calculations.

The following image shows an Amazon CloudWatch graph of the concurrent executions for one Lambda function during the time that the workflow was running. There are almost 10,000 functions running in parallel during this time.

Simplifying and shortening the time to run the job opens a lot of possibilities for CyberGRX and the data science team. The benefits started right away the moment one of the data scientists wanted to run the job to test some improvements they had made for the model. They were able to run it independently without requiring an engineer to help them.
And, because the predictive model itself is one of the key offerings from CyberGRX, the company now has a more competitive product since the predictive analysis can be refined on a daily basis.
Learn more about using AWS Step Functions:
You can also check the Serverless Workflows Collection that we have available in Serverless Land for you to test and learn more about this new capability.
— Marcia
from AWS News Blog https://ift.tt/x8uJt7A
via IFTTT
Tuesday, April 25, 2023

Monday, April 24, 2023
AWS Week in Review – April 24, 2023: Amazon CodeCatalyst, Amazon S3 on Snowball Edge, and More…
As always, there’s plenty to share this week: Amazon CodeCatalyst is now generally available, Amazon S3 is now available on Snowball Edge devices, version 1.0.0 of AWS Amplify Flutter is here, and a lot more. Let’s dive in!
Last Week’s Launches
Here are some of the launches that caught my eye this past week:
Amazon CodeCatalyst – First announced at re:Invent in preview form (Announcing Amazon CodeCatalyst, a Unified Software Development Service), this unified software development and delivery service is now generally available. As Steve notes in the post that he wrote for the preview, “Amazon CodeCatalyst enables software development teams to quickly and easily plan, develop, collaborate on, build, and deliver applications on AWS, reducing friction throughout the development lifecycle.” During the preview we added the ability to use AWS Graviton2 for CI/CD workflows and deployment environments, along with other new features, as detailed in the What’s New.
Amazon S3 on Snowball Edge – You have had the power to create S3 buckets on AWS Snow Family devices for a couple of years, and to PUT and GET object. With this new launch you can, as Channy says, “…use an expanded set of Amazon S3 APIs to easily build applications on AWS and deploy them on Snowball Edge Compute Optimized devices.” This launch allows you to manage the storage using AWS OpsHub, and to address multiple Denied, Disrupted, Intermittent, and Limited Impact (DDIL) use cases. To learn more, read Amazon S3 Compatible Storage on AWS Snowball Edge Compute Optimized Devices Now Generally Available.
Amazon Redshift Updates – We announced multiple updates to Amazon Redshift including the MERGE SQL command so that you can combine a series of DML statements into a single statement, dynamic data masking to simplify the process of protecting sensitive data in your Amazon Redshift data warehouse, and centralized access control for data sharing with AWS Lake Formation.
AWS Amplify – You can now build cross-platform Flutter apps that target iOS, Android, Web, and desktop using a single codebase and with a consistent user experience. To learn more and to see how to get started, read Amplify Flutter announces general availability for web and desktop support. In addition to the GA, we also announced that AWS Amplify supports Push Notifications for Android, Swift, React Native, and Flutter apps.
X in Y – We made existing services available in additional regions and locations:
- Direct Connect location in Querétaro, Mexico.
- Migration Hub Refactor Spaces in 7 additional regions.
- AWS Backup for Amazon S3 in South America (São Paulo) and GovCloud (US) Regions.
- AWS Backup in Asia Pacific (Melbourne).
- Amazon ECS Service Connect in Europe (Zurich) and Middle East (UAE).
- Amazon GuardDuty in Asia Pacific (Melbourne).
- Amazon VPC Prefix Lists in Asia Pacific (Hyderabad, Melbourne) and Europe (Spain).
- AWS Control Tower in 7 additional regions.
- Amazon WorkSpaces Web Access with WSP in AWS GovCloud (US-West).
For a full list of AWS announcements, take a look at the What’s New at AWS page and consider subscribing to the page’s RSS feed. If you want even more detail, you can Subscribe to AWS Daily Feature Updates via Amazon SNS.
Interesting Blog Posts
Other AWS Blogs – Here are some fresh posts from a few of the other AWS Blogs:
- Increased visibility of your carbon emissions data with AWS Customer Carbon Footprint Tool.
- Identify objections in customer conversations using Amazon Comprehend to enhance customer experience without ML expertise.
- Create a CI/CD pipeline for .NET Lambda functions with AWS CDK Pipelines.
- Exploring new ETL and ELT capabilities for Amazon Redshift from the AWS Glue Studio visual editor.
- Analyze customer satisfaction scores with post-contact surveys using Amazon Connect Tasks.
- Understanding techniques to reduce AWS Lambda costs in serverless applications.
- Power microservices architectures with Amazon MemoryDB for Redis.
- Amazon SageMaker Data Wrangler for dimensionality reduction.
- Efficient truck routing with Amazon Location Service.
- Use IAM roles to connect GitHub Actions to actions in AWS
- Protect Your Web Applications with AWS WAF Ready Partners.
AWS Open Source – My colleague Ricardo writes a weekly newsletter to highlight new open source projects, tools, and demos from the AWS Community. Read edition 154 to learn more.
AWS Graviton Weekly – Marcos Ortiz writes a weekly newsletter to highlight the latest developments in AWS custom silicon. Read AWS Graviton weekly #33 to see what’s up.
Upcoming Events
Here are some upcoming live and online events that may be of interest to you:
AWS Community Day Turkey will take place in Istanbul on May 6, and I will be there to deliver the keynote. Get your tickets and I will see you there!
AWS Summits are coming to Berlin (May 4), Washington, DC (June 7 and 8), London (June 7), and Toronto (June 14). These events are free but I highly recommend that you register ahead of time.
.NET Enterprise Developer Day EMEA is a free one-day virtual conference on April 25; register now.
AWS Developer Innovation Day is also virtual, and takes place on April 26 (read Discover Building without Limits at AWS Developer Innovation Day for more info). I’ll be watching all day and sharing a live recap at the end; learn more and see you there.
And that’s all for today!
— Jeff;
from AWS News Blog https://ift.tt/O5dISax
via IFTTT
Choose Korean in AWS Support as Your Preferred Language
Today, we are announcing the general availability of AWS Support in Korean as your preferred language, in addition to English, Japanese, and Chinese.
As the number of customers speaking Korean grows, AWS Support is invested in providing the best support experience possible. You can now communicate with AWS Support engineers and agents in Korean when you create a support case at the AWS Support Center.
Now all customers can receive account and billing support in Korean by email, phone, and live chat at no additional cost during the supported hours. Per your Support plan, customers subscribed to Enterprise, Enterprise On-Ramp, or Business Support plans can receive personalized technical support 24 hours a day and 7 days a week in Korean. Customers subscribed to the Developer Support plan can receive technical support during business hours generally defined as 9:00 AM to 6:00 PM in the customer country as set in My Account console, excluding holidays and weekends. These times may vary in countries with multiple time zones.
We also added the localized user interface of the AWS Support Center in Korean, in addition to Japanese and Chinese. AWS Support Center will be displayed in the language you select from the dropdown of available languages in Unified Settings of your AWS Account.
Here is a new AWS Support Center page in Korean:

You can also access customer service, AWS documentation, technical papers, and support forums in Korean.
Getting Started with Your Supported Language in AWS Support
To get started with AWS Support in your supported language, create a Support case in AWS Support Center. In the final step in creating a Support case, you can choose a supported language, such as English, Chinese (中文), Korean (한국어), or Japanese (日本語) as your Preferred contact language.

When you choose Korean, the customized contact options will be shown by your support plan.
For example, in the case of Basic Support plan customers, you can choose Web to get support via email, Phone, or Live Chat when available. AWS customers with account and billing inquiries can receive support in Korean from our customer service representatives with proficiency in Korean at no additional cost during business hours defined as 09:00 AM to 06:00 PM Korean Standard Time (GMT+9), excluding holidays and weekends.
If you get technical support per your Support plan, you may choose Web, Phone, or Live Chat depending on your Support plan to get in touch with support staff with proficiency in Korean, in addition to English, Japanese, and Chinese.
Here is a screen in Korean to get technical support in the Enterprise Support plan:

When you create a support case in your preferred language, the case will be routed to support staff with proficiency in the language indicated in your preferred language selection. To learn more, see Getting started with AWS Support in the AWS documentation.
Now Available
AWS Support in Korean is now available today, in addition to English, Japanese, and Chinese. Give it a try, learn more about AWS Support, and send feedback to your usual AWS Support contacts.
– Channy
This article was translated into Korean (한국어) in the AWS Korea Blog.
from AWS News Blog https://ift.tt/5h7XWYV
via IFTTT
Thursday, April 20, 2023
Amazon S3 Compatible Storage on AWS Snowball Edge Compute Optimized Devices Now Generally Available
We have added a collection of purpose-built services to the AWS Snow Family for customers, such as Snowball Edge in 2016 and Snowcone in 2020. These services run compute intensive workloads and stores data in edge locations with denied, disrupted, intermittent, or limited network connectivity and for transferring large amounts of data from on-premises and rugged or mobile environments.
 Each new service is optimized for space- or weight-constrained environments, portability, and flexible networking options. For example, Snowball Edge devices have three options for device configurations. AWS Snowball Edge Compute Optimized provides a suitcase-sized, secure, and rugged device that customers can deploy in rugged and tactical edge locations to run their compute applications. Customers modernize their edge applications in the cloud use AWS compute services and storage services such as Amazon Simple Storage Service (Amazon S3), and then deploy these applications on Snow devices at the edge.
Each new service is optimized for space- or weight-constrained environments, portability, and flexible networking options. For example, Snowball Edge devices have three options for device configurations. AWS Snowball Edge Compute Optimized provides a suitcase-sized, secure, and rugged device that customers can deploy in rugged and tactical edge locations to run their compute applications. Customers modernize their edge applications in the cloud use AWS compute services and storage services such as Amazon Simple Storage Service (Amazon S3), and then deploy these applications on Snow devices at the edge.
We heard from customers that they also needed access to local object store to run applications at the edge, such as 5G mobile core and real-time data analytics, to process end-user transactions, and they had limited storage infrastructure availability in these environments. Although the Amazon S3 Adapter for Snowball enables the basic storage and retrieval of objects on a Snow device, customers wanted access to a broader set of Amazon S3 APIs, including flexibility at scale, local bucket management, object tagging, and S3 event notifications.
Today, we’re announcing the general availability of Amazon S3 compatible storage on Snow for our Snowball Edge Compute Optimized devices. This makes it easy for you to store data and run applications with local S3 buckets that require low latency processing at the edge.
With Amazon S3 compatible storage on Snow, you can use an expanded set of Amazon S3 APIs to easily build applications on AWS and deploy them on Snowball Edge Compute Optimized devices. This eliminates the need to re-architect applications for each deployment. You can manage applications requiring Amazon S3 compatible storage across the cloud, on-premises, and at the edge in connected and disconnected environments with a consistent experience.
Moreover, you can use AWS OpsHub, a graphical user interface, to manage your Snow Family services and Amazon S3 compatible storage on the devices at the edge or remotely from a central location. You can also use Amazon S3 SDK or AWS Command Line Interface (AWS CLI) to create and manage S3 buckets, get S3 event notifications using MQTT, and local service notifications using SMTP, just as you do in AWS Regions.
With Amazon S3 compatible storage on Snow, we are now able to address various use cases in limited network environments, giving customers secure, durable local object storage. For example, customers in the intelligence community and in industrial IoT deploy applications such as video analytics in rugged and mobile edge locations.
Getting Started with S3 Compatible Storage on Snowball Edge Compute Optimized
To order new Amazon S3 enabled Snowball Edge devices, create a job in the AWS Snow Family console. You can replace an existing Snow device or cluster with new replacement devices that support S3 compatible storage.
In Step 1 – Job type, input your job name and choose Local compute and storage only. In Step 2 – Compute and storage, choose your preferred Snowball Edge Compute Optimized device.
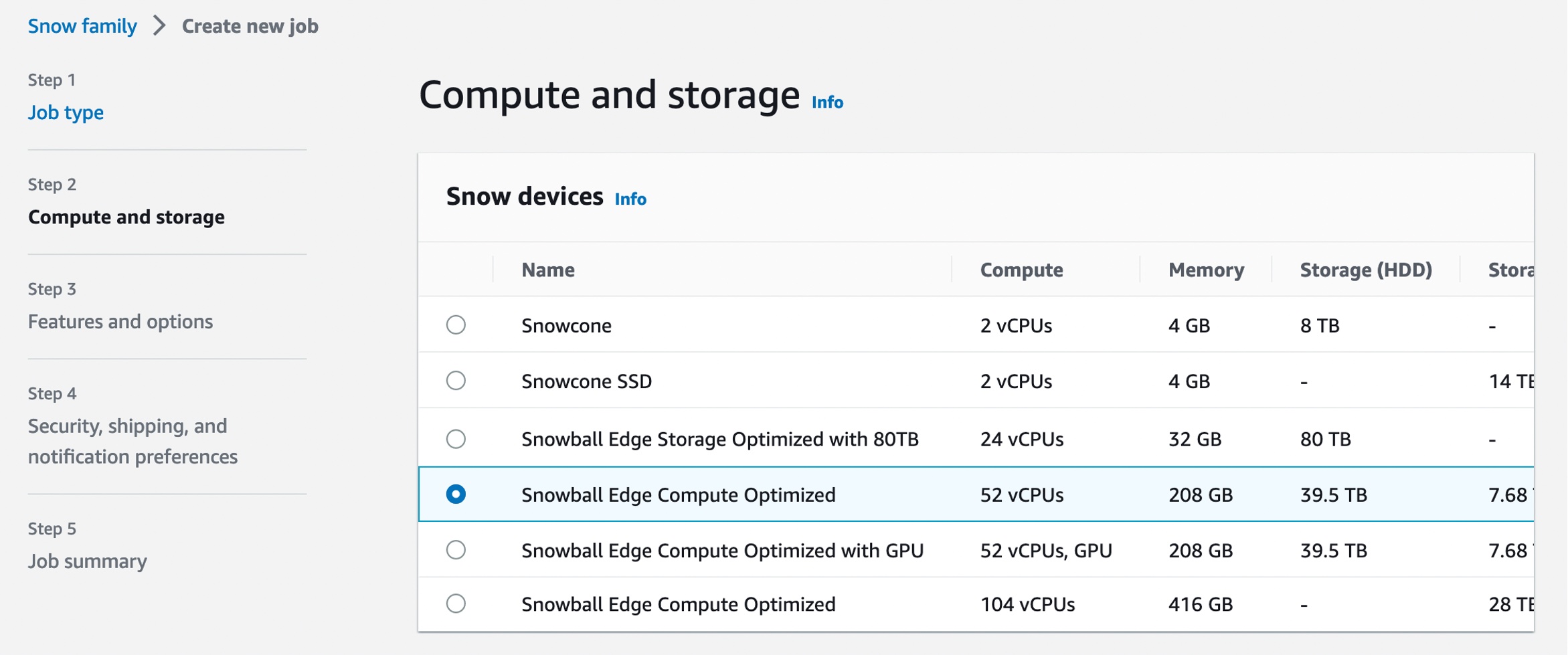
Select Amazon S3 compatible storage, a new option for S3 compatible storage. The current S3 Adapter solution is on deprecation path, and we recommend migrating workloads to use Amazon S3 compatible storage on Snow.

When you select Amazon S3 compatible storage, you can configure Amazon S3 compatible storage capacity for a single device or for a cluster. The Amazon S3 storage capacity depends on the quantity and type of Snowball Edge device.
- For single-device deployment, you can provision granular Amazon S3 capacity up to a maximum of 31 TB on a Snowball Edge Compute Optimized device.
- For a cluster setup, all storage capacity on a device is allocated to Amazon S3 compatible storage on Snow. You can provision a maximum of 500 TB on a 16 node cluster of Snowball Edge Compute Optimized devices.
When you provide all necessary job details and create your job, you can see the status of the delivery of your device in the job status section.
Manage S3 Compatible Storage on Snow with OpsHub
Once your device arrives at your site, power it on, and connect it to your network. To manage your device, download, install, and launch the OpsHub application in your laptop. After installation, you can unlock the device and start managing it and using supported AWS services locally.
OpsHub provides a dashboard that summarizes key metrics, such as storage capacity and active instances on your device. It also provides a selection of AWS services that are supported on the Snow Family devices.
Log in to OpsHub, then choose Manage Storage. This takes you to the Amazon S3 compatible storage on Snow landing page.
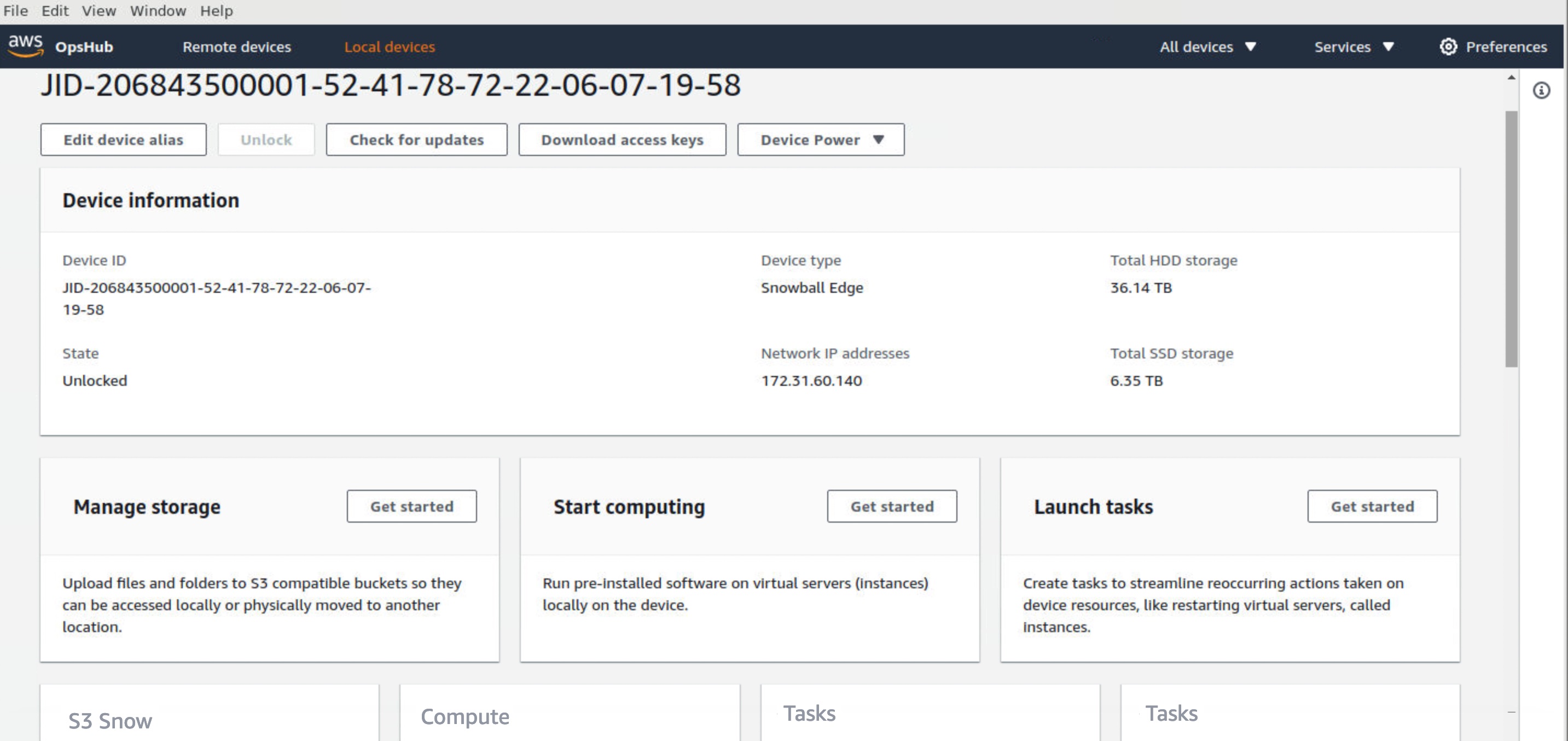
For Start service setup type, choose Simple if your network uses dynamic host configuration protocol (DHCP). With this option, the virtual network interface cards (VNICs) are created automatically on each device when you start the service. When your network uses static IP addresses, you need to create VNICs for each device manually, so choose the Advanced option.
Once the service starts, you’ll see its status is active with a list of endpoints. The following example shows the service activated in a single device:
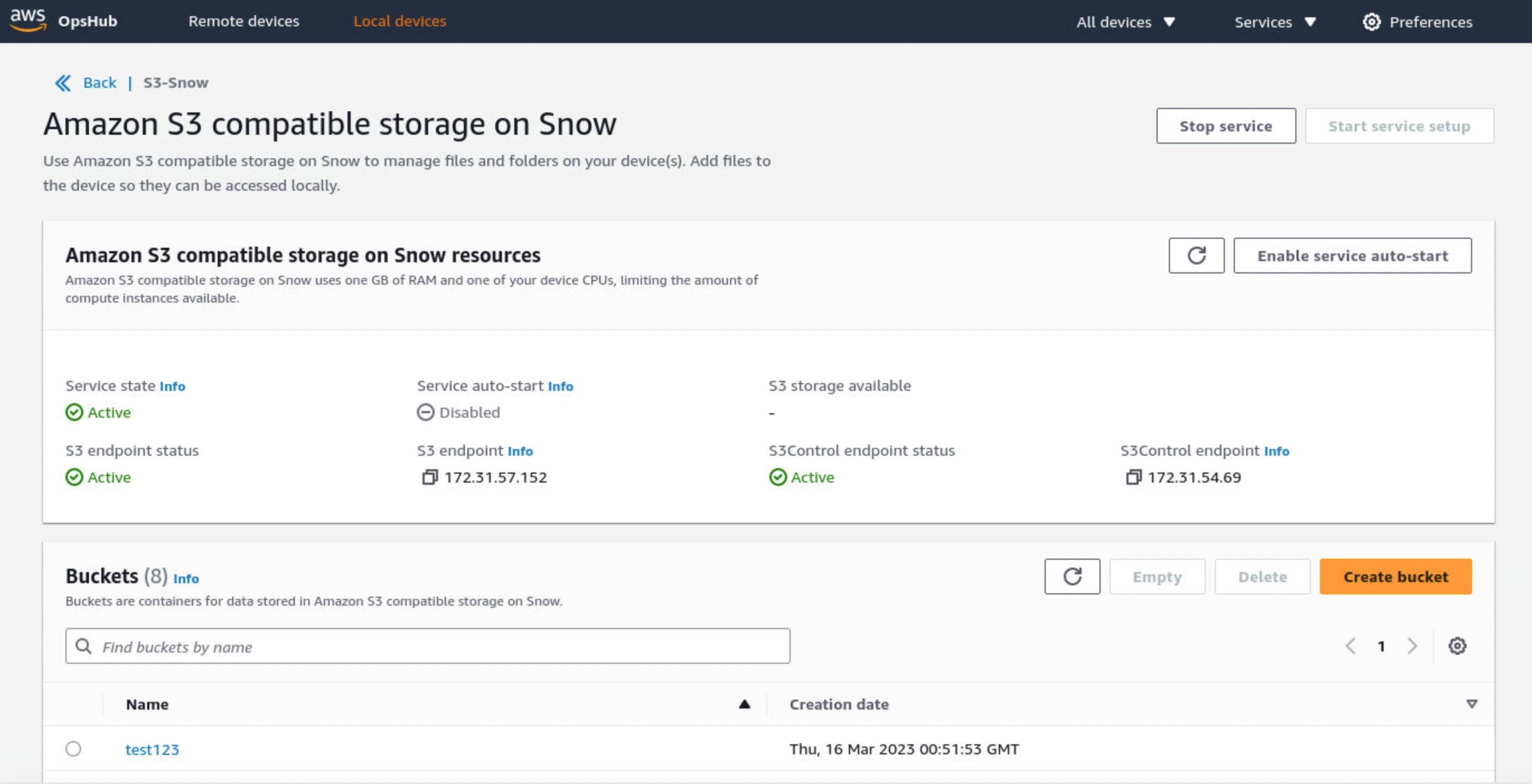
Choose Create bucket if you want the new S3 bucket in your device. Otherwise, you can upload files to your selected bucket. New uploaded objects have destination URLs such as s3-snow://test123/test_file with the unique bucket name in the device or cluster.
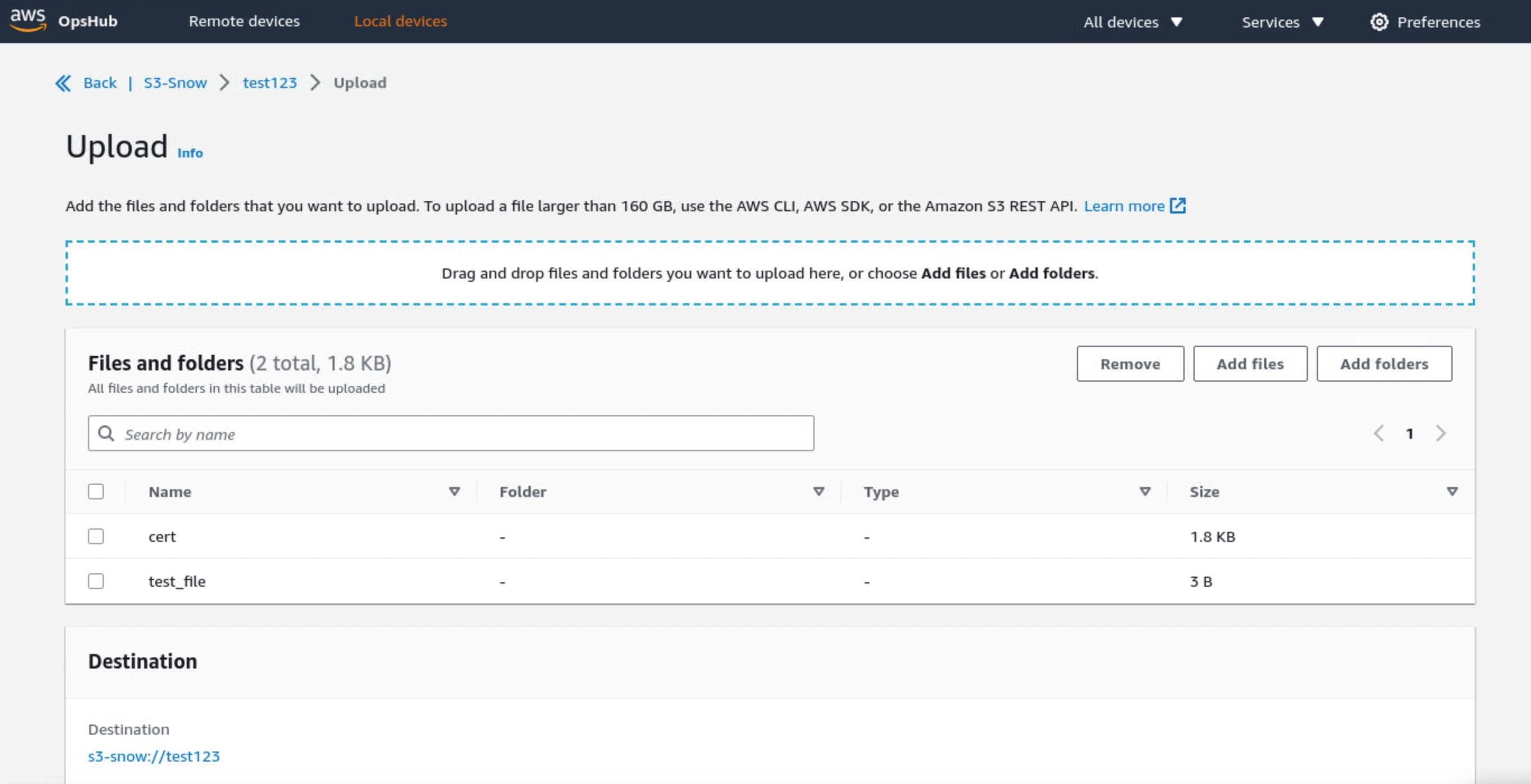
You can also use the bucket lifecycle rule to define when to trigger object deletion based on age or date. Choose Create lifecycle rule in the Management tab to add a new lifecycle rule.

You can select either Delete objects or Delete incomplete multipart uploads as a rule action. Configure the rule trigger that schedules deletion based on a specific date or object’s age. In this example, I set two days to delete objects after being uploaded.

You can also use the Amazon S3 SDK/CLI for all API operations supported by S3 for Snowball Edge. To learn more, see API Operations Supported on Amazon S3 for Snowball Edge in the AWS documentation.
Things to know
Keep these things in mind regarding additional features and considerations when you use Amazon S3 compatible storage on Snow:
- Capacity: If you fully utilize Amazon S3 capacity on your device or cluster, your write (
PUT) requests return an insufficient capacity error. Read (GET) operations continue to function normally. To monitor the available Amazon S3 capacity, you can use the OpsHub S3 on the Snow page or use thedescribe-serviceCLI command. Upon detecting insufficient capacity on the Snow device or cluster, you must free up space by deleting data or transferring data to an S3 bucket in the Region or another on-premises device. - Resiliency: Amazon S3 compatible storage on Snow stores data redundantly across multiple disks on each Snow device and multiple devices in your cluster, with built-in protection against correlated hardware failures. In the event of a disk or device failure within the quorum range, Amazon S3 compatible storage on Snow continues to operate until hardware is replaced. Additionally, Amazon S3 compatible storage on Snow continuously scrubs data on the device to make sure of data integrity and recover any corrupted data. For workloads that require local storage, the best practice is to back up your data to further protect your data stored on Snow devices.
- Notifications: Amazon S3 compatible storage on Snow continuously monitors the health status of the device or cluster. Background processes respond to data inconsistencies and temporary failures to heal and recover data to make sure of resiliency. In the case of nonrecoverable hardware failures, Amazon S3 compatible storage on Snow can continue operations and provides proactive notifications through emails, prompting you to work with AWS to replace failed devices. For connected devices, you have the option to enable the “Remote Monitoring” feature, which will allow AWS to monitor service health online and proactively notify you of any service issues.
- Security: Amazon S3 compatible storage on Snow supports encryption using server-side encryption with Amazon S3 managed encryption keys (SSE-S3) or customer-provided keys (SSE-C) and authentication and authorization using Snow IAM actions namespace (
s3:*) to provide you with distinct controls for data stored on your Snow devices. Amazon S3 compatible storage on Snow doesn’t support object-level access control list and bucket policies. Amazon S3 compatible storage on Snow defaults to Bucket Owner is Object Owner, making sure that the bucket owner has control over objects in the bucket.
Now Available
Amazon S3 compatible storage on Snow is now generally available for AWS Snowball Edge Compute Optimized devices in all AWS Commercial and GovCloud Regions where AWS Snow is available.
To learn more, see the AWS Snowball Edge Developer Guide and send feedback to AWS re:Post for AWS Snowball or through your usual AWS support contacts.
– Channy
from AWS News Blog https://ift.tt/7wHUPML
via IFTTT
Wednesday, April 19, 2023
Discover Building without Limits at AWS Developer Innovation Day
We hope you can join us on Wednesday, April 26, for a free-to-attend online event, AWS Developer Innovation Day. AWS will stream the event simultaneously across multiple platforms, including LinkedIn Live, Twitter, YouTube, and Twitch.
Developer Innovation Day is a brand-new event designed specifically for developers and development teams. In the event, sessions throughout the day will show how you can improve productivity and collaboration, provide a first look at new product updates, and go deep on AWS tools for development and delivery. Topics to be addressed include how you can speed up web and mobile application development and how you can build and deliver faster by taking advantage of modern infrastructure, DevOps, and generative AI-enabled tools.
We’ll be starting the day with a keynote from Adam Seligman, Vice President of Developer Experience at AWS. And, to wrap up the event, there are closing sessions from Dr. Werner Vogels, CTO at Amazon, Harry Mower, Director, AWS Code Suite, and Doug Seven, Director of Software Development, Amazon CodeWhisperer. A panel of experts will join Werner to discuss the latest trends in generative AI and what it all means for developers. Harry and Doug will discuss trends in developer and team productivity. Of course, no event would be complete without our own Jeff Barr, VP of AWS Evangelism, who’ll be sharing a “Best practices and key takeaways” session with a recap of key stories, announcements, and moments from the day!
AWS staff will present the technical breakout sessions during the day, and AWS Heroes and Community Builders will also be involved, presenting community spotlights, which are an excellent chance to get involved with the global AWS community. During and after the event there’s also a chance to sign up for an AWS Amplify hackathon that will be held in May and also an Amazon CodeCatalyst immersion day. Other fun events are also in the works—watch the event details page for more information.

There’s no up-front registration required to join AWS Developer Innovation Day, which, I’ll remind you, is also free to attend. Simply head on over to the event page and select Add to calendar. I’m excited to be joined by colleagues from the AWS on Air team to host the event, and we all hope you’ll choose to join in the fun and learning opportunities at this brand-new event!
from AWS News Blog https://ift.tt/jFGJTzD
via IFTTT
Monday, April 17, 2023
AWS Week in Review: New Service for Generative AI and Amazon EC2 Trn1n, Inf2, and CodeWhisperer now GA – April 17, 2023
AWS Week in Review: New Service for Generative AI and Amazon EC2 Trn1n, Inf2, and CodeWhisperer now GA – April 17, 2023
I could almost title this blog post the “AWS AI/ML Week in Review.” This past week, we announced several new innovations and tools for building with generative AI on AWS. Let’s dive right into it.
Last Week’s Launches
Here are some launches that got my attention during the previous week:
Announcing Amazon Bedrock and Amazon Titan models – Amazon Bedrock is a new service to accelerate your development of generative AI applications using foundation models through an API without managing infrastructure. You can choose from a wide range of foundation models built by leading AI startups and Amazon. The new Amazon Titan foundation models are pre-trained on large datasets, making them powerful, general-purpose models. You can use them as-is or privately to customize them with your own data for a particular task without annotating large volumes of data. Amazon Bedrock is currently in limited preview. Sign up here to learn more.
Amazon EC2 Trn1n and Inf2 instances are now generally available – Trn1n instances, powered by AWS Trainium accelerators, double the network bandwidth (compared to Trn1 instances) to 1,600 Gbps of Elastic Fabric Adapter (EFAv2). The increased bandwidth delivers even higher performance for training network-intensive generative AI models such as large language models (LLMs) and mixture of experts (MoE). Inf2 instances, powered by AWS Inferentia2 accelerators, deliver high performance at the lowest cost in Amazon EC2 for generative AI models, including LLMs and vision transformers. They are the first inference-optimized instances in Amazon EC2 to support scale-out distributed inference with ultra-high-speed connectivity between accelerators. Compared to Inf1 instances, Inf2 instances deliver up to 4x higher throughput and up to 10x lower latency. Check out my blog posts on Trn1 instances and Inf2 instances for more details.
Amazon CodeWhisperer, free for individual use, is now generally available – Amazon CodeWhisperer is an AI coding companion that generates real-time single-line or full-function code suggestions in your IDE to help you build applications faster. With GA, we introduce two tiers: CodeWhisperer Individual and CodeWhisperer Professional. CodeWhisperer Individual is free to use for generating code. You can sign up with an AWS Builder ID based on your email address. The Individual Tier provides code recommendations, reference tracking, and security scans. CodeWhisperer Professional—priced at $19 per user, per month—offers additional enterprise administration capabilities. Steve’s blog post has all the details.
Amazon GameLift adds support for Unreal Engine 5 – Amazon GameLift is a fully managed solution that allows you to manage and scale dedicated game servers for session-based multiplayer games. The latest version of the Amazon GameLift Server SDK 5.0 lets you integrate your Unreal 5-based game servers with the Amazon GameLift service. In addition, the latest Amazon GameLift Server SDK with Unreal 5 plugin is built to work with Amazon GameLift Anywhere so that you can test and iterate Unreal game builds faster and manage game sessions across any server hosting infrastructure. Check out the release notes to learn more.
Amazon Rekognition launches Face Liveness to deter fraud in facial verification – Face Liveness verifies that only real users, not bad actors using spoofs, can access your services. Amazon Rekognition Face Liveness analyzes a short selfie video to detect spoofs presented to the camera, such as printed photos, digital photos, digital videos, or 3D masks, as well as spoofs that bypass the camera, such as pre-recorded or deepfake videos. This AWS Machine Learning Blog post walks you through the details and shows how you can add Face Liveness to your web and mobile applications.
For a full list of AWS announcements, be sure to keep an eye on the What's New at AWS page.Other AWS News
Here are some additional news items and blog posts that you may find interesting:
Updates to the AWS Well-Architected Framework – The most recent content updates and improvements focus on providing expanded guidance across the AWS service portfolio to help you make more informed decisions when developing implementation plans. Services that were added or expanded in coverage include AWS Elastic Disaster Recovery, AWS Trusted Advisor, AWS Resilience Hub, AWS Config, AWS Security Hub, Amazon GuardDuty, AWS Organizations, AWS Control Tower, AWS Compute Optimizer, AWS Budgets, Amazon CodeWhisperer, and Amazon CodeGuru. This AWS Architecture Blog post has all the details.
Amazon releases largest dataset for training “pick and place” robots – In an effort to improve the performance of robots that pick, sort, and pack products in warehouses, Amazon has publicly released the largest dataset of images captured in an industrial product-sorting setting. Where the largest previous dataset of industrial images featured on the order of 100 objects, the Amazon dataset, called ARMBench, features more than 190,000 objects. Check out this Amazon Science Blog post to learn more.
AWS open-source news and updates – My colleague Ricardo writes this weekly open-source newsletter in which he highlights new open-source projects, tools, and demos from the AWS Community. Read edition #153 here.
Upcoming AWS Events
Check your calendars and sign up for these AWS events:
 #BuildOn Generative AI – Join our weekly live Build On Generative AI Twitch show. Every Monday morning, 9:00 US PT, my colleagues Emily and Darko take a look at aspects of generative AI. They host developers, scientists, startup founders, and AI leaders and discuss how to build generative AI applications on AWS.
#BuildOn Generative AI – Join our weekly live Build On Generative AI Twitch show. Every Monday morning, 9:00 US PT, my colleagues Emily and Darko take a look at aspects of generative AI. They host developers, scientists, startup founders, and AI leaders and discuss how to build generative AI applications on AWS.
In today’s episode, Emily walks us through the latest AWS generative AI announcements. You can watch the video here.
 .NET Developer Day – .NET Enterprise Developer Day EMEA 2023 (April 25) is a free, one-day virtual event providing enterprise developers with the most relevant information to swiftly and efficiently migrate and modernize their .NET applications and workloads on AWS.
.NET Developer Day – .NET Enterprise Developer Day EMEA 2023 (April 25) is a free, one-day virtual event providing enterprise developers with the most relevant information to swiftly and efficiently migrate and modernize their .NET applications and workloads on AWS.
 AWS Developer Innovation Day – AWS Developer Innovation Day (April 26) is a new, free, one-day virtual event designed to help developers and teams be productive and collaborate from discovery to delivery, to running software and building applications. Get a first look at exciting product updates, technical deep dives, and keynotes.
AWS Developer Innovation Day – AWS Developer Innovation Day (April 26) is a new, free, one-day virtual event designed to help developers and teams be productive and collaborate from discovery to delivery, to running software and building applications. Get a first look at exciting product updates, technical deep dives, and keynotes.
 AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work: Tokyo (April 20–21), Singapore (May 4), Stockholm (May 11), Hong Kong (May 23), Tel Aviv (May 31), Amsterdam (June 1), London (June 7), Washington, DC (June 7–8), Toronto (June 14), Madrid (June 15), and Milano (June 22).
AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work: Tokyo (April 20–21), Singapore (May 4), Stockholm (May 11), Hong Kong (May 23), Tel Aviv (May 31), Amsterdam (June 1), London (June 7), Washington, DC (June 7–8), Toronto (June 14), Madrid (June 15), and Milano (June 22).
You can browse all upcoming AWS-led in-person and virtual events and developer-focused events such as Community Days.
That’s all for this week. Check back next Monday for another Week in Review!
— Antje
This post is part of our Week in Review series. Check back each week for a quick roundup of interesting news and announcements from AWS!
from AWS News Blog https://ift.tt/vTHx4db
via IFTTT
Thursday, April 13, 2023
Amazon CodeWhisperer, Free for Individual Use, is Now Generally Available
Today, Amazon CodeWhisperer, a real-time AI coding companion, is generally available and also includes a CodeWhisperer Individual tier that’s free to use for all developers. Originally launched in preview last year, CodeWhisperer keeps developers in the zone and productive, helping them write code quickly and securely and without needing to break their flow by leaving their IDE to research something. Faced with creating code for complex and ever-changing environments, developers can improve their productivity and simplify their work by making use of CodeWhisperer inside their favorite IDEs, including Visual Studio Code, IntelliJ IDEA, and others. CodeWhisperer helps with creating code for routine or time-consuming, undifferentiated tasks, working with unfamiliar APIs or SDKs, making correct and effective use of AWS APIs, and other common coding scenarios such as reading and writing files, image processing, writing unit tests, and lots more.
Using just an email account, you can sign up and, in just a few minutes, become more productive writing code—and you don’t even need to be an AWS customer. For business users, CodeWhisperer offers a Professional tier that adds administrative features, like SSO and IAM Identity Center integration, policy control for referenced code suggestions, and higher limits on security scanning. And in addition to generating code suggestions for Python, Java, JavaScript, TypeScript, and C#, the generally available release also now supports Go, Rust, PHP, Ruby, Kotlin, C, C++, Shell scripting, SQL, and Scala. CodeWhisperer is available to developers working in Visual Studio Code, IntelliJ IDEA, CLion, GoLand, WebStorm, Rider, PhpStorm, PyCharm, RubyMine, and DataGrip IDEs (when the appropriate AWS extensions for those IDEs are installed), or natively in AWS Cloud9 or AWS Lambda console.
Helping to keep developers in their flow is increasingly important as, facing increasing time pressure to get their work done, developers are often forced to break that flow to turn to an internet search, sites such as StackOverflow, or their colleagues for help in completing tasks. While this can help them obtain the starter code they need, it’s disruptive as they’ve had to leave their IDE environment to search or ask questions in a forum or find and ask a colleague—further adding to the disruption. Instead, CodeWhisperer meets developers where they are most productive, providing recommendations in real time as they write code or comments in their IDE. During the preview we ran a productivity challenge, and participants who used CodeWhisperer were 27% more likely to complete tasks successfully and did so an average of 57% faster than those who didn’t use CodeWhisperer.

Code generation from a comment
The code developers eventually locate may, however, contain issues such as hidden security vulnerabilities, be biased or unfair, or fail to handle open source responsibly. These issues won’t improve the developer’s productivity when they later have to resolve them. CodeWhisperer is the best coding companion when it comes to coding securely and using AI responsibly. To help you code responsibly, CodeWhisperer filters out code suggestions that might be considered biased or unfair, and it’s the only coding companion that can filter or flag code suggestions that may resemble particular open-source training data. It provides additional data for suggestions—for example, the repository URL and license—when code similar to training data is generated, helping lower the risk of using the code and enabling developers to reuse it with confidence.
![]()
Open-source reference tracking
CodeWhisperer is also the only AI coding companion to have security scanning for finding and suggesting remediations for hard-to-detect vulnerabilities, scanning both generated and developer-written code looking for vulnerabilities such as those in the top ten listed in the Open Web Application Security Project (OWASP). If it finds a vulnerability, CodeWhisperer provides suggestions to help remediate the issue.
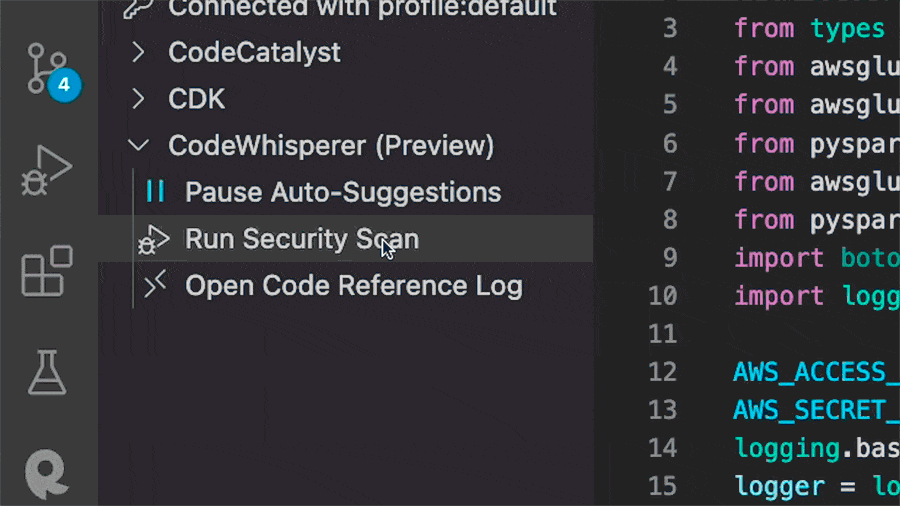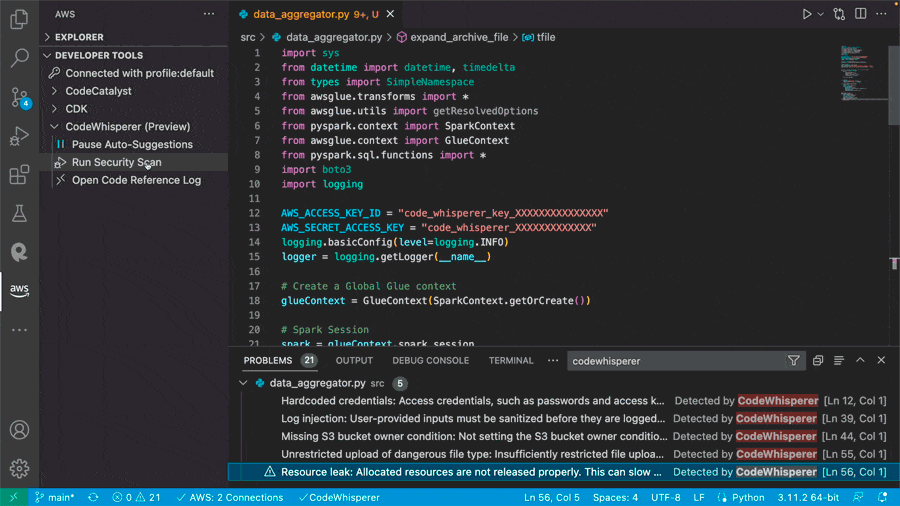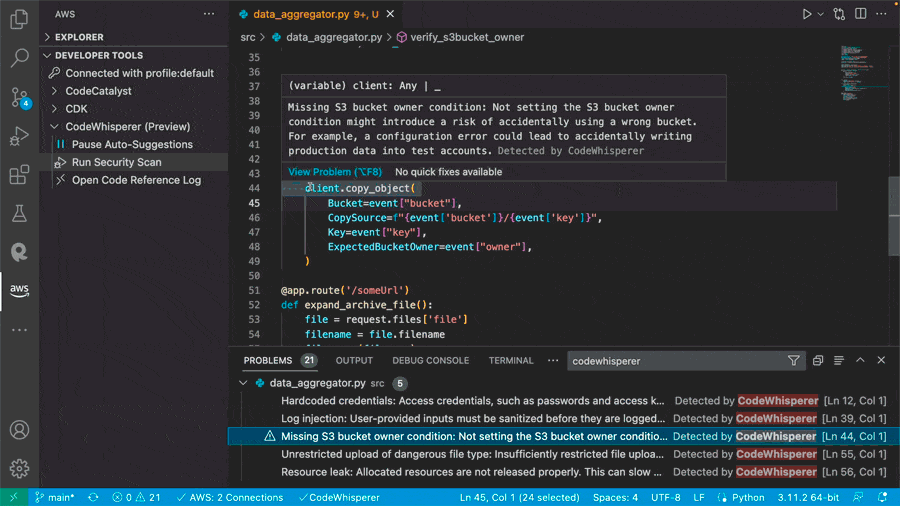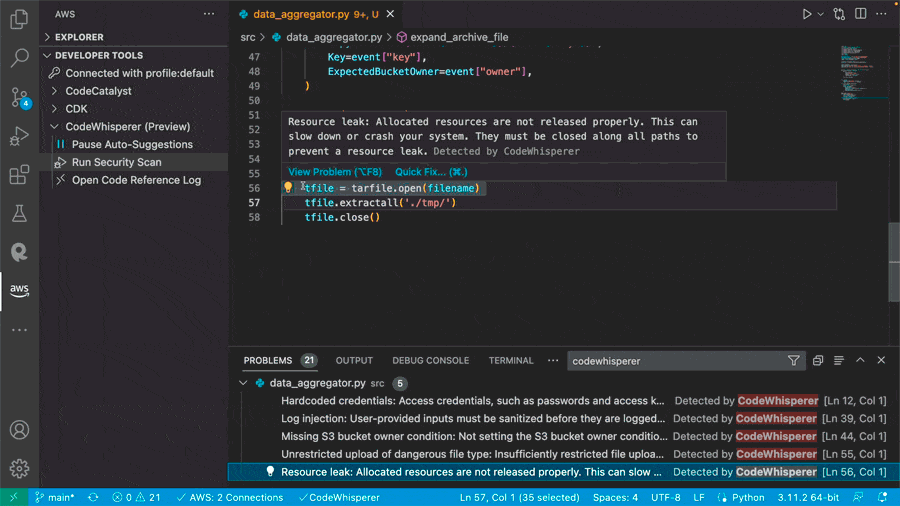
Scanning for vulnerabilities
Code suggestions provided by CodeWhisperer are not specific to working with AWS. However, CodeWhisperer is optimized for the most-used AWS APIs, for example AWS Lambda, or Amazon Simple Storage Service (Amazon S3), making it the best coding companion for those building applications on AWS. While CodeWhisperer provides suggestions for general-purpose use cases across a variety of languages, the tuning performed using additional data on AWS APIs means you can be confident it is the highest quality, most accurate code generation you can get for working with AWS.
Meet Your new AI Code Companion Today
Amazon CodeWhisperer is generally available today to all developers—not just those with an AWS account or working with AWS—writing code in Python, Java, JavaScript, TypeScript, C#, Go, Rust, PHP, Ruby, Kotlin, C, C++, Shell scripting, SQL, and Scala. You can sign up with just an email address, and, as I mentioned at the top of this post, CodeWhisperer offers an Individual tier that’s freely available to all developers. More information on the Individual tier, and pricing for the Professional tier, can be found at https://aws.amazon.com/codewhisperer/pricing.
from AWS News Blog https://ift.tt/wsSVGWI
via IFTTT
Monday, April 10, 2023
Week in Review: Terraform in Service Catalog, AWS Supply Chain, Streaming Response in Lambda, and Amplify Library for Swift – April 10, 2023
The AWS Summit season has started. AWS Summits are free technical and business conferences happening in large cities across the planet. This week, we were happy to welcome our customers and partners in Sydney and Paris. In France, 9,973 customers and partners joined us for the day to meet and exchange ideas but also to attend one of the more than 145 technical breakout sessions and the keynote. This is the largest cloud computing event in France, and I can’t resist sharing a picture from the main room during the opening keynote.

There are AWS Summits on all continents ; you can find the list and the links for registration here https://aws.amazon.com/events/summits. The next on my agenda are listed at the end of this post.
These two Summits did not slow down our services teams. I counted 44 new capabilities since last Monday. Here are the few that caught my attention.
Last Week on AWS
AWS Lambda response streaming – Response streaming is a new invocation pattern that lets functions progressively stream response payloads back to clients. You can use Lambda response payload streaming to send response data to callers as it becomes available. Response streaming also allows you to build functions that return larger payloads and perform long-running operations while reporting incremental progress (within the 15 minutes execution period). My colleague Julian wrote an incredibly detailed blog post to help you to get started.
AWS Supply Chain Now Generally Available – AWS Supply Chain is a cloud application that mitigates risk and lowers costs with unified data and built-in contextual collaboration. It connects to your existing enterprise resource planning (ERP) and supply chain management systems to bring you ML-powered actionable insights into your supply chain.
AWS Service Catalog Supports Terraform Templates – With AWS Service Catalog, you can create, govern, and manage a catalog of infrastructure as code (IaC) templates that are approved for use on AWS. You can now define AWS Service Catalog products and their resources using either AWS CloudFormation or Hashicorp Terraform and choose the tool that better aligns with your processes and expertise.
Amazon S3 enforces two security best practices and brings new visibility into object replication status – As announced on December 13, 2022, Amazon S3 is now deploying two new default bucket security settings by automatically enabling S3 Block Public Access and disabling S3 access control lists (ACLs) for all new S3 buckets. Amazon S3 also adds a new Amazon CloudWatch metric that can be used to diagnose and correct S3 Replication configuration issues more quickly. The OperationFailedReplication metric, available in both the Amazon S3 console and in Amazon CloudWatch, gives you per-minute visibility into the number of objects that did not replicate to the destination bucket for each of your replication rules.
AWS Security Hub launches four security best practices – AWS Security Hub has released 4 new controls for its National Institute of Standards and Technology (NIST) SP 800-53 Rev. 5 standard. These controls conduct fully-automatic security checks against Elastic Load Balancing (ELB), Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Redshift, and Amazon Simple Storage Service (Amazon S3). To use these controls, you should first turn on the NIST standard.
AWS Cloud Operation Competency Partners – AWS Cloud Operations covers five fundamental solution areas: Cloud Governance, Cloud Financial Management, Monitoring and Observability, Compliance and Auditing, and Operations Management. The new competency enables customers to select validated AWS Partners who offer comprehensive solutions with an integrated approach across multiple areas.
Amplify Library for Swift on macOS – Amplify is an open-source, client-side library making it easier to access a cloud backend from your front-end application code. It provides language-specific constructs to abstract low-level details of the cloud API. It helps you to integrate services such as analytics, object storage, REST or GraphQL APIs, user authentication, geolocation and mapping, and push notifications. You can now write beautiful macOS applications that connect to the same cloud backend as their iOS counterparts.
X in Y Jeff started this section a while ago to list the expansion of new services and capabilities to additional Regions. I noticed 11 Regional expansions this week:
- New Direct Connect location in Mumbai, India.
- AWS Codebuild is available in three additional Regions: Asia Pacific (Hyderabad) and Europe (Spain, Zurich)
- AWS CodePipeline is available in three additional Regions: Africa (Cape Town), Europe (Zurich), and Middle East (Bahrain)
- Amplify Studio is available in Europe (Milan)
- Amazon HealthLake is available in Asia Pacific (Mumbai)
- Amazon Polly offers full support in Asia Pacific (Osaka)
- Amazon CloudFormation StackSets is available in Asia Pacific (Hyderabad) and Middle East (UAE)
- Amazon Kinesis Data Analytics is available in three additional Regions: Asia Pacific (Hyderabad) and Europe (Spain, Zurich)
- Amazon SageMaker is available in Asia Pacific (Hyderabad)
- Amazon Glue is available in Europe (Spain, Zurich)
- Amazon Appstream 2.0 is available in AWS GovCloud (US-East)
Upcoming AWS Events
And to finish this post, I recommend you check your calendars and sign up for these AWS-led events:
.Net Developer Day – .NET Enterprise Developer Day EMEA 2023 (April 25) is a free, one-day virtual conference providing enterprise developers with the most relevant information to swiftly and efficiently migrate and modernize their .NET applications and workloads on AWS.
![]() AWS re:Inforce 2023 – Now register AWS re:Inforce, in Anaheim, California, June 13–14. AWS Chief Information Security Officer CJ Moses will share the latest innovations in cloud security and what AWS Security is focused on. The breakout sessions will provide real-world examples of how security is embedded into the way businesses operate. To learn more and get the limited discount code to register, see CJ’s blog post of Gain insights and knowledge at AWS re:Inforce 2023 in the AWS Security Blog.
AWS re:Inforce 2023 – Now register AWS re:Inforce, in Anaheim, California, June 13–14. AWS Chief Information Security Officer CJ Moses will share the latest innovations in cloud security and what AWS Security is focused on. The breakout sessions will provide real-world examples of how security is embedded into the way businesses operate. To learn more and get the limited discount code to register, see CJ’s blog post of Gain insights and knowledge at AWS re:Inforce 2023 in the AWS Security Blog.
AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work: Seoul (May 3–4), Berlin and Singapore (May 4), Stockholm (May 11), Hong Kong (May 23), Amsterdam (June 1), London (June 7), Madrid (June 15), and Milano (June 22).
![]() AWS Community Day – Join community-led conferences driven by AWS user group leaders close to your city: Lima (April 15), Helsinki (April 20), Chicago (June 15), Manila (June 29–30), and Munich (September 14). Recently, we have been bringing together AWS user groups from around the world into Meetup Pro accounts. Find your group and its meetups in your city!
AWS Community Day – Join community-led conferences driven by AWS user group leaders close to your city: Lima (April 15), Helsinki (April 20), Chicago (June 15), Manila (June 29–30), and Munich (September 14). Recently, we have been bringing together AWS user groups from around the world into Meetup Pro accounts. Find your group and its meetups in your city!
You can browse all upcoming AWS-led in-person and virtual events, and developer-focused events such as AWS DevDay.
Stay Informed
That was my selection for this week! To better keep up with all of this news, don’t forget to check out the following resources:
- What’s New with AWS – All AWS announcements. You might want to add the RSS feed to your news reader.
- The Official AWS Podcast – Listen each week for updates on the latest AWS news and deep dives into exciting use cases. There are also official AWS podcasts in your local languages. Check out the ones in French, German, Italian, and Spanish.
- AWS News Blog – This blog.
- And subscribe to the open-source newsletter brought to you by my most excellent colleague Ricardo.
That’s all for this week. Check back next Monday for another Week in Review!
-- sebfrom AWS News Blog https://ift.tt/y6aMFgz
via IFTTT
Wednesday, April 5, 2023
Tuesday, April 4, 2023
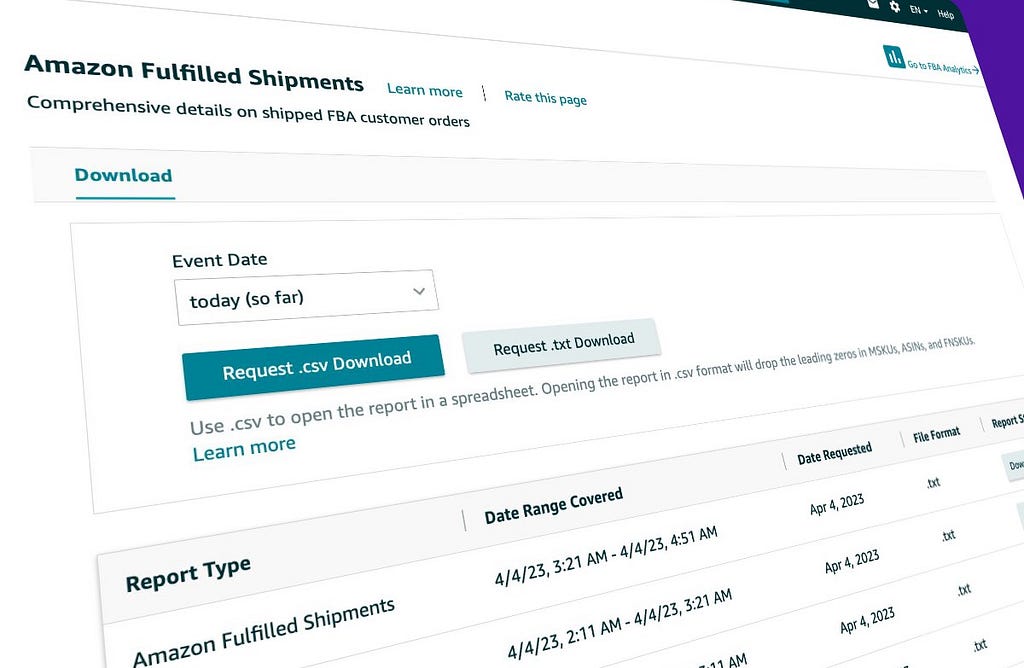
Monday, April 3, 2023
New – Self-Service Provisioning of Terraform Open-Source Configurations with AWS Service Catalog
With AWS Service Catalog, you can create, govern, and manage a catalog of infrastructure as code (IaC) templates that are approved for use on AWS. These IaC templates can include everything from virtual machine images, servers, software, and databases to complete multi-tier application architectures. You can control which IaC templates and versions are available, what is configured by each version, and who can access each template based on individual, group, department, or cost center. End users such as engineers, database administrators, and data scientists can then quickly discover and self-service provision approved AWS resources that they need to use to perform their daily job functions.
When using Service Catalog, the first step is to create products based on your IaC templates. You can then collect products, together with configuration information, in a portfolio.
Starting today, you can define Service Catalog products and their resources using either AWS CloudFormation or Hashicorp Terraform and choose the tool that better aligns with your processes and expertise. You can now integrate your existing Terraform configurations into Service Catalog to have them part of a centrally approved portfolio of products and share it with the AWS accounts used by your end users. In this way, you can prevent inconsistencies and mitigate the risk of noncompliance.
When resources are deployed by Service Catalog, you can maintain least privilege access during provisioning and govern tagging on the deployed resources. End users of Service Catalog pick and choose what they need from the list of products and versions they have access to. Then, they can provision products in a single action regardless of the technology (CloudFormation or Terraform) used for the deployment.
The Service Catalog hub-and-spoke model that enables organizations to govern at scale can now be extended to include Terraform configurations. With the Service Catalog hub and spoke model, you can centrally manage deployments using a management/user account relationship:
- One management account – Used to create Service Catalog products, organize them into portfolios, and share portfolios with user accounts
- Multiple user accounts (up to thousands) – A user account is any AWS account in which the end users of Service Catalog are provisioning resources.
Let’s see how this works in practice.
Creating an AWS Service Catalog Product Using Terraform
To get started, I install the Terraform Reference Engine (provided by AWS on GitHub) that configures the code and infrastructure required for the Terraform open-source engine to work with AWS Service Catalog. I only need to do this once, in the management account for Service Catalog, and the setup takes just minutes. I use the automated installation script:
./deploy-tre.sh -r us-east-1To keep things simple for this post, I create a product deploying a single EC2 instance using AWS Graviton processors and the Amazon Linux 2023 operating system. Here’s the content of my main.tf file:
I sign in to the AWS Management Console in the management account for Service Catalog. In the Service Catalog console, I choose Product list in the Administration section of the navigation pane. There, I choose Create product.
In Product details, I select Terraform open source as Product type. I enter a product name and description and the name of the owner.

In the Version details, I choose to Upload a template file (using a tar.gz archive). Optionally, I can specify the template using an S3 URL or an external code repository (on GitHub, GitHub Enterprise Server, or Bitbucket) using an AWS CodeStar provider.

I enter support details and custom tags. Note that tags can be used to categorize your resources and also to check permissions to create a resource. Then, I complete the creation of the product.
Adding an AWS Service Catalog Product Using Terraform to a Portfolio
Now that the Terraform product is ready, I add it to my portfolio. A portfolio can include both Terraform and CloudFormation products. I choose Portfolios from the Administrator section of the navigation pane. There, I search for my portfolio by name and open it. I choose Add product to portfolio. I search for the Terraform product by name and select it.

Terraform products require a launch constraint. The launch constraint specifies the name of an AWS Identity and Access Management (IAM) role that is used to deploy the product. I need to separately ensure that this role is created in every account with which the product is shared.
The launch role is assumed by the Terraform open-source engine in the management account when an end user launches, updates, or terminates a product. The launch role also contains permissions to describe, create, and update a resource group for the provisioned product and tag the product resources. In this way, Service Catalog keeps the resource group up-to-date and tags the resources associated with the product.
The launch role enables least privilege access for end users. With this feature, end users don’t need permission to directly provision the product’s underlying resources because your Terraform open-source engine assumes the launch role to provision those resources, such as an approved configuration of an Amazon Elastic Compute Cloud (Amazon EC2) instance.
In the Launch constraint section, I choose Enter role name to use a role I created before for this product:
- The trust relationship of the role defines the entities that can assume the role. For this role, the trust relationship includes Service Catalog and the management account that contains the Terraform Reference Engine.
- For permissions, the role allows to provision, update, and terminate the resources required by my product and to manage resource groups and tags on those resources.

I complete the addition of the product to my portfolio. Now the product is available to the end users who have access to this portfolio.
Launching an AWS Service Catalog Product Using Terraform
End users see the list of products and versions they have access to and can deploy them in a single action. If you already use Service Catalog, the experience is the same as with CloudFormation products.
I sign in to the AWS Console in the user account for Service Catalog. The portfolio I used before has been shared by the management account with this user account. In the Service Catalog console, I choose Products from the Provisioning group in the navigation pane. I search for the product by name and choose Launch product.
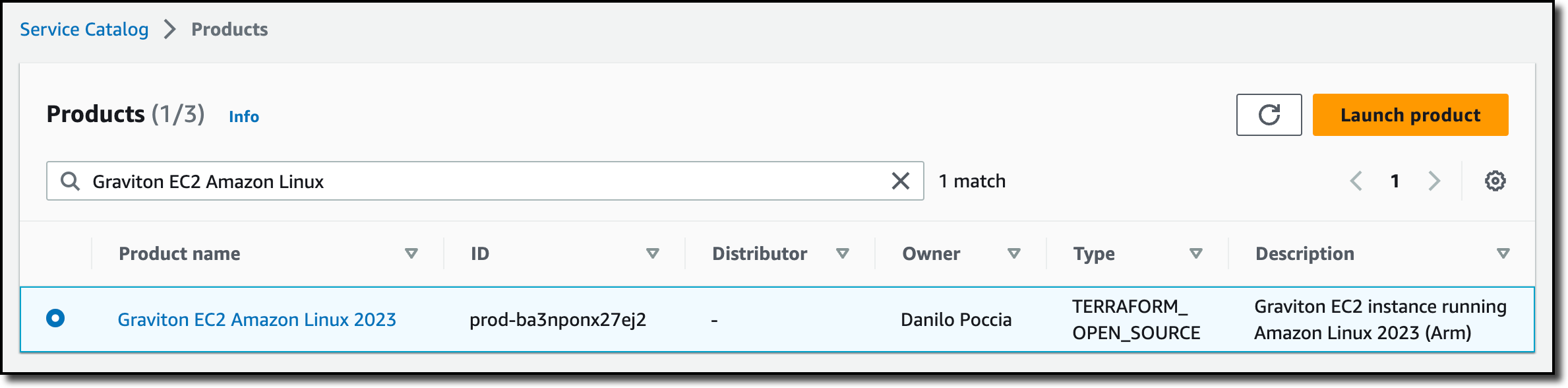
I let Service Catalog generate a unique name for the provisioned product and select the product version to deploy. Then, I launch the product.

After a few minutes, the product has been deployed and is available. The deployment has been managed by the Terraform Reference Engine.
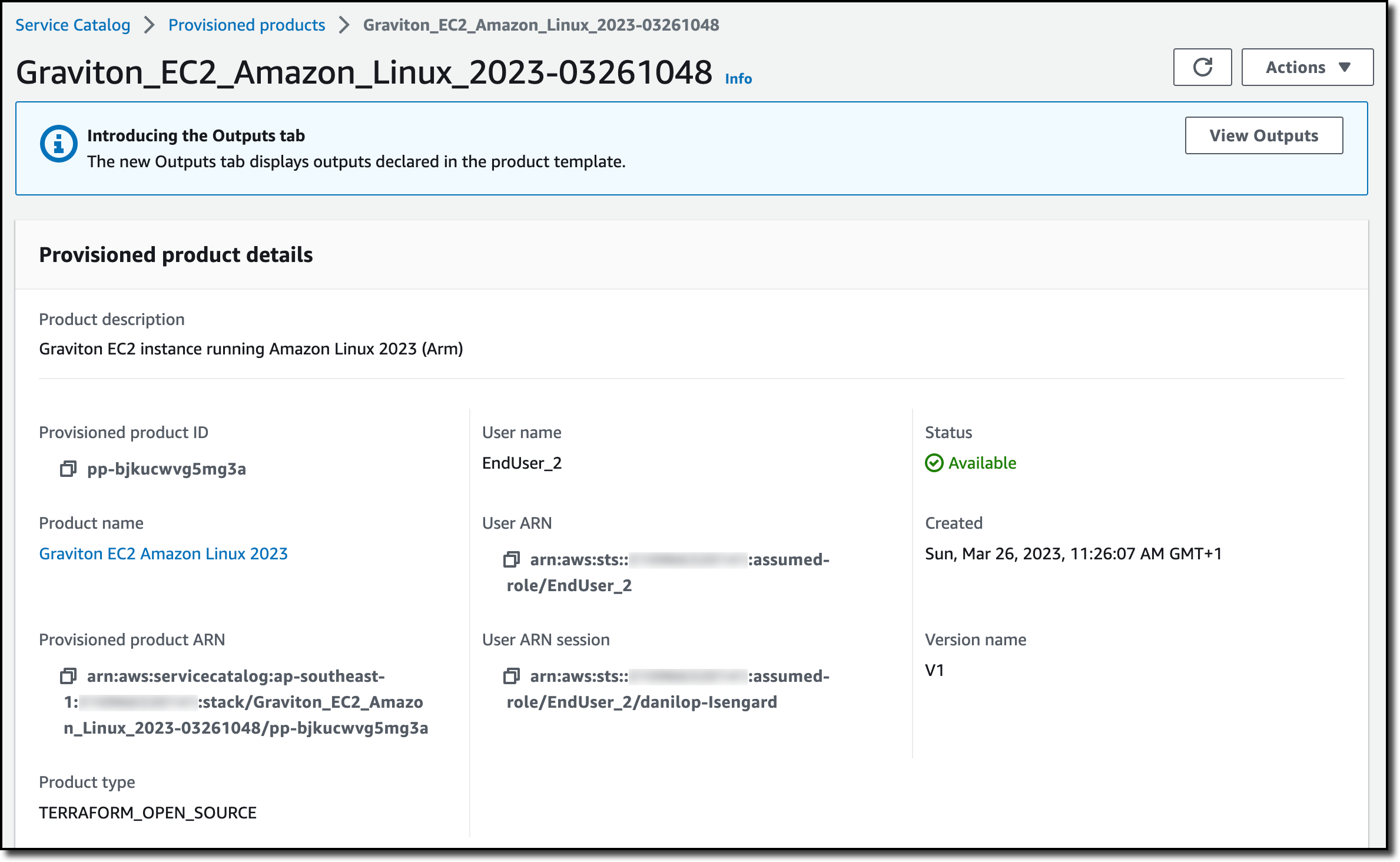
In the Associated tags tab, I see that Service Catalog automatically added information on the portfolio and the product.

In the Resources tab, I see the resources created by the provisioned product. As expected, it’s an EC2 instance, and I can follow the link to open the Amazon EC2 console and get more information.

End users such as engineers, database administrators, and data scientists can continue to use Service Catalog and launch the products they need without having to consider if they are provisioned using Terraform or CloudFormation.
Availability and Pricing
AWS Service Catalog support for Terraform open-source configurations is available today in all AWS Regions where it is offered. There is no change in pricing when using Terraform. With Service Catalog, you pay for the API calls you make to the service, and you can start for free with the free tier. You also pay for the resources used and created by the Terraform Reference Engine. For more information, see Service Catalog Pricing.
Enable self-service provisioning at scale for your Terraform open-source configurations.
— Danilo
from AWS News Blog https://ift.tt/TjtL91N
via IFTTT
Subscribe to:
Comments (Atom)