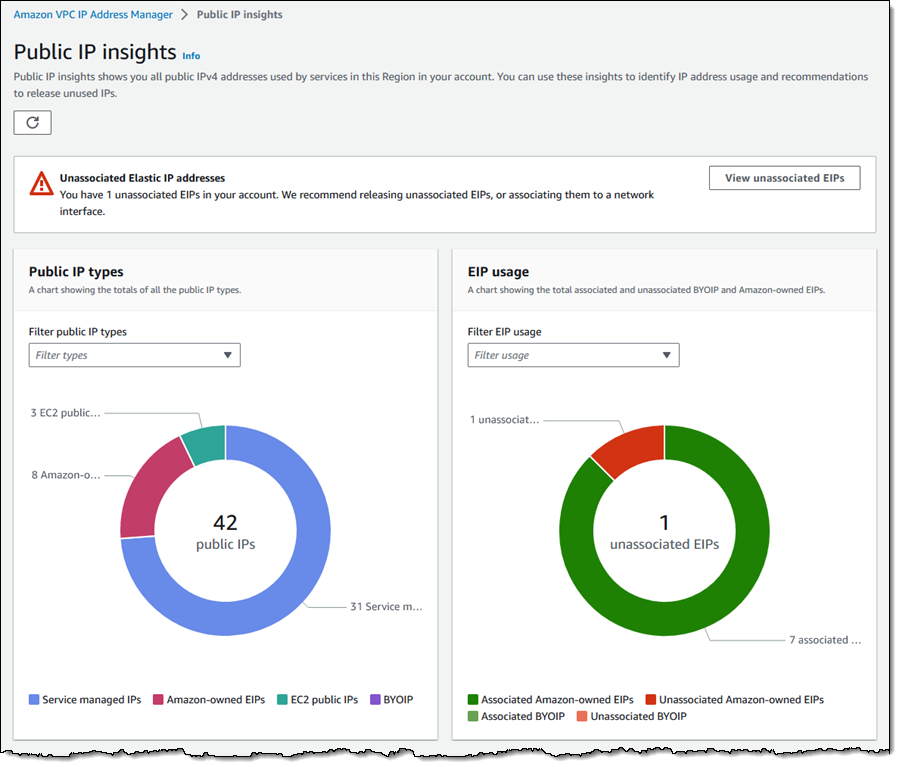
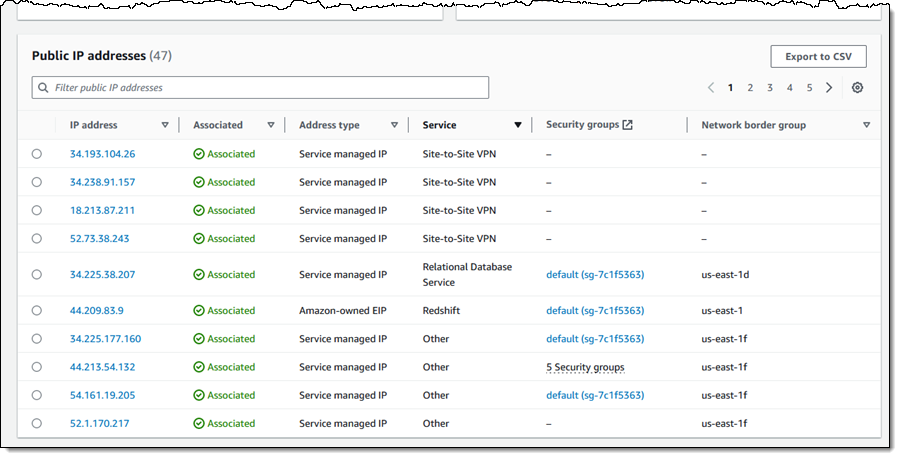
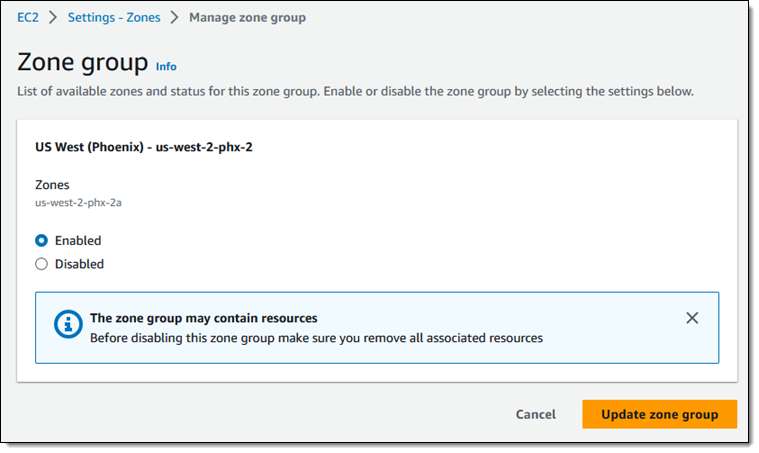
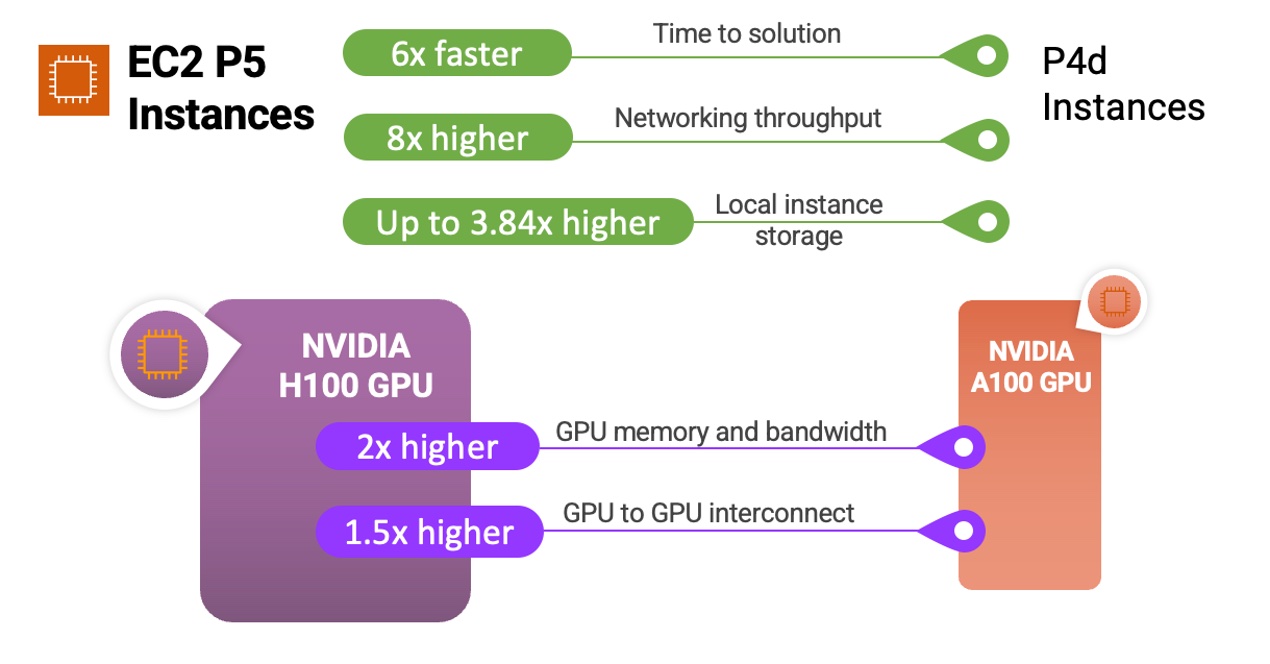
This July, AWS communities in ASEAN wrote a new history. First, the AWS User Group Malaysia recently held the first AWS Community Day in Malaysia.

Another significant milestone has been achieved by the AWS User Group Philippines. They just celebrated their tenth anniversary by running 2 days of AWS Community Day Philippines. Here are a few photos from the event, including Jeff Barr sharing his experiences attending AWS User Group meetup, in Manila, Philippines 10 years ago.

Big congratulations to AWS Community Heroes, AWS Community Builders, AWS User Group leaders and all volunteers who organized and delivered AWS Community Days! Also, thank you to everyone who attended and help support our AWS communities.
Last Week’s Launches
We had interesting launches last week, including from AWS Summit, New York. Here are some of my personal highlights:
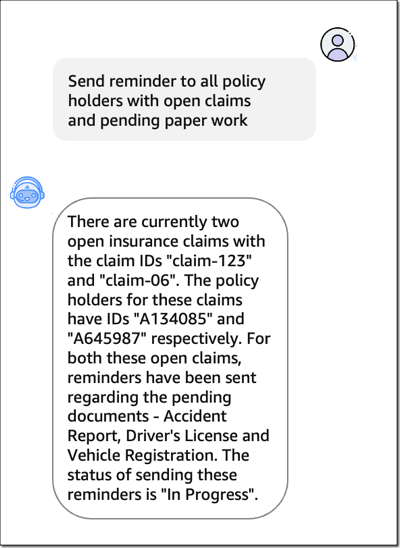
(Preview) Agents for Amazon Bedrock – You can now create managed agents for Amazon Bedrock to handle tasks using API calls to company systems, understand user requests, break down complex tasks into steps, hold conversations to gather more information, and take actions to fulfill requests.
(Coming Soon) New LLM Capabilities in Amazon QuickSight Q – We are expanding the innovation in QuickSight Q by introducing new LLM capabilities through Amazon Bedrock. These Generative BI capabilities will allow organizations to easily explore data, uncover insights, and facilitate sharing of insights.
AWS Glue Studio support for Amazon CodeWhisperer – You can now write specific tasks in natural language (English) as comments in the Glue Studio notebook, and Amazon CodeWhisperer provides code recommendations for you.

(Preview) Vector Engine for Amazon OpenSearch Serverless – This capability empowers you to create modern ML-augmented search experiences and generative AI applications without the need to handle the complexities of managing the underlying vector database infrastructure.
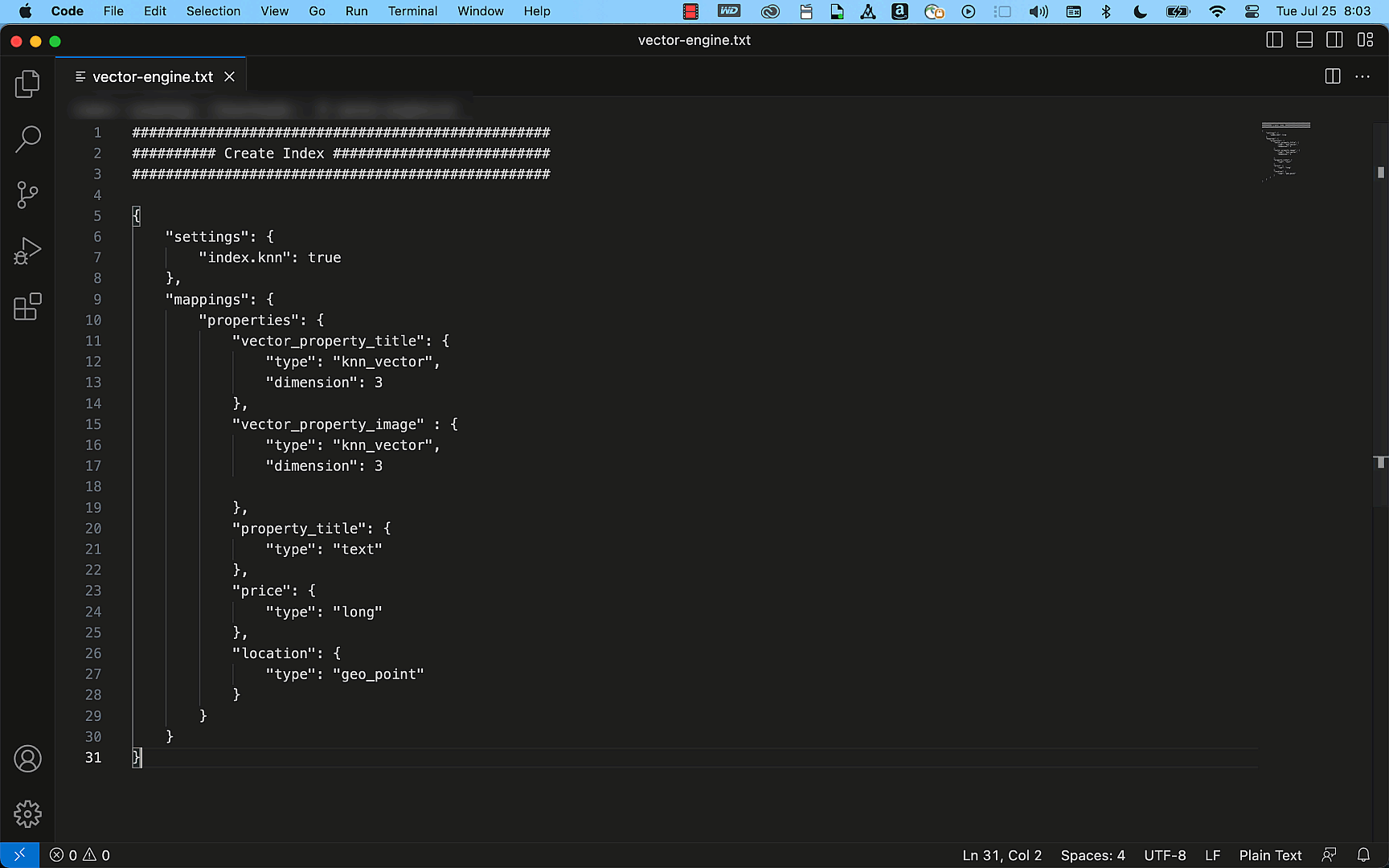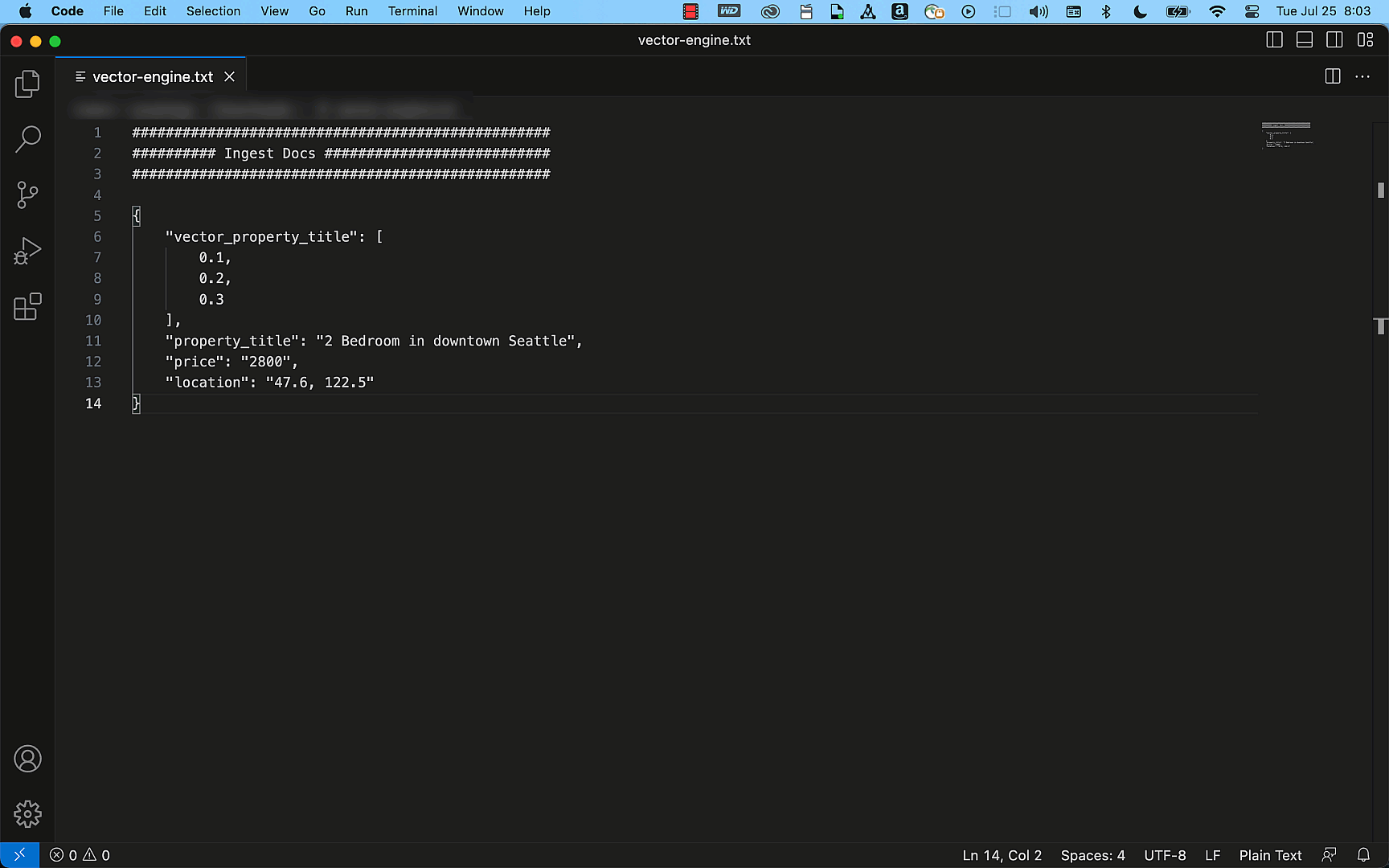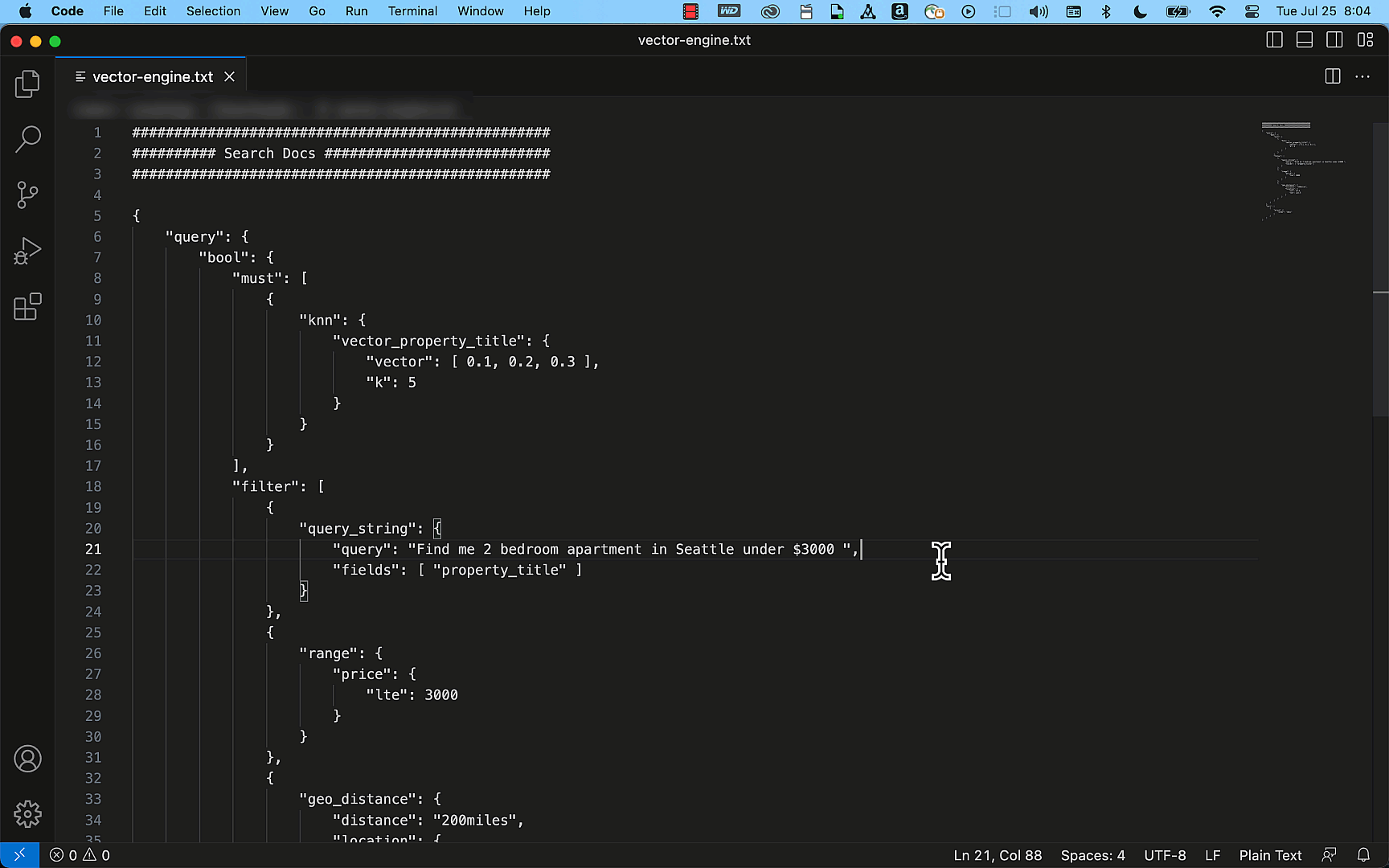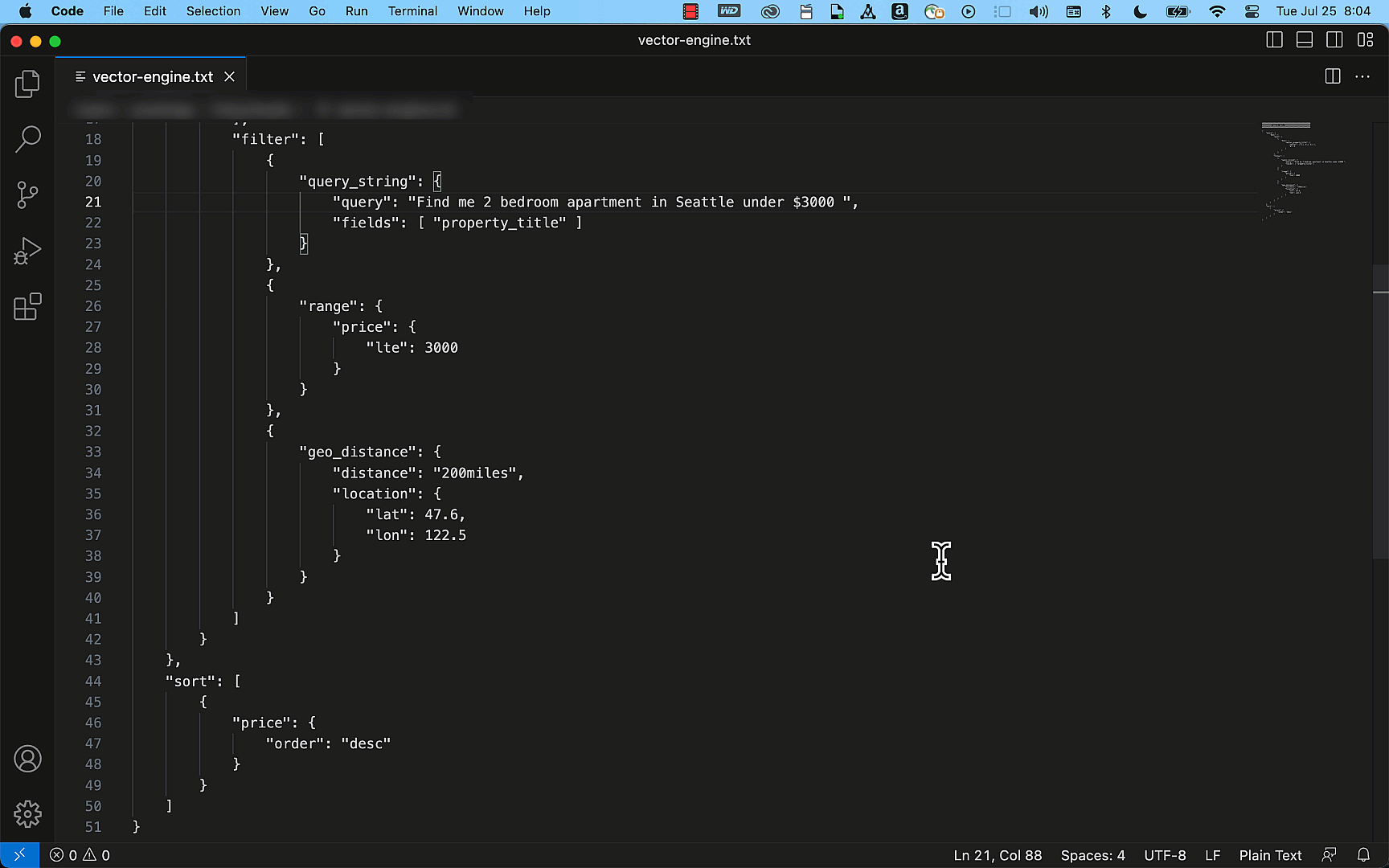
Last week, Amazon SageMaker Canvas also released a set of new capabilities:
- Training ML models with different objective metrics
- Sharing ML models with Amazon QuickSight
- Custom Amazon S3 output location for ML artifacts
- Document queries powered by Amazon Textract
AWS Open-Source Updates
As always, my colleague Ricardo has curated the latest updates for open-source news at AWS. Here are some of the highlights.
cdk-aws-observability-accelerator is a set of opinionated modules to help you set up observability for your AWS environments with AWS native services and AWS-managed observability services such as Amazon Managed Service for Prometheus, Amazon Managed Grafana, AWS Distro for OpenTelemetry (ADOT) and Amazon CloudWatch.
iac-devtools-cli-for-cdk is a command line interface tool that automates many of the tedious tasks of building, adding to, documenting, and extending AWS CDK applications.
Upcoming AWS Events
There are upcoming events that you can join to learn. Let’s start with AWS events:
- AWS Storage Day (August 9)
- AWS Summit Taiwan (August 2-3)
- AWS Summit São Paulo (August 3)
- AWS Summit Mexico City (August 30)
And let’s learn from our fellow builders and join AWS Community Days:
- AWS Community Day Colombia (August 12)
- AWS Community Day West Africa (August 19)
Open for Registration for AWS re:Invent
We want to be sure you know that AWS re:Invent registration is now open!

This learning conference hosted by AWS for the global cloud computing community will be held from November 27 to December 1, 2023, in Las Vegas.
Pro-tip: You can use information on the Justify Your Trip page to prove the value of your trip to AWS re:Invent trip.
Give Us Your Feedback
We’re focused on improving our content to provide a better customer experience, and we need your feedback to do so. Please take this quick survey to share insights on your experience with the AWS Blog. Note that this survey is hosted by an external company, so the link does not lead to our website. AWS handles your information as described in the AWS Privacy Notice.
That’s all for this week. Check back next Monday for another Week in Review.
Happy building!
— Donnie
P.S. We’re focused on improving our content to provide a better customer experience, and we need your feedback to do so. Please take this quick survey to share insights on your experience with the AWS Blog. Note that this survey is hosted by an external company, so the link does not lead to our website. AWS handles your information as described in the AWS Privacy Notice.
from AWS News Blog https://ift.tt/hOrF13m
via IFTTT