This April, we announced Amazon Bedrock as part of a set of new tools for building with generative AI on AWS. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, including AI21 Labs, Anthropic, Cohere, Stability AI, and Amazon, along with a broad set of capabilities to build generative AI applications, simplifying the development while maintaining privacy and security.
Today, I’m happy to announce that Amazon Bedrock is now generally available! I’m also excited to share that Meta’s Llama 2 13B and 70B parameter models will soon be available on Amazon Bedrock.

Amazon Bedrock’s comprehensive capabilities help you experiment with a variety of top FMs, customize them privately with your data using techniques such as fine-tuning and retrieval-augmented generation (RAG), and create managed agents that perform complex business tasks—all without writing any code. Check out my previous posts to learn more about agents for Amazon Bedrock and how to connect FMs to your company’s data sources.
Note that some capabilities, such as agents for Amazon Bedrock, including knowledge bases, continue to be available in preview. I’ll share more details on what capabilities continue to be available in preview towards the end of this blog post.
Since Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with.
Amazon Bedrock is integrated with Amazon CloudWatch and AWS CloudTrail to support your monitoring and governance needs. You can use CloudWatch to track usage metrics and build customized dashboards for audit purposes. With CloudTrail, you can monitor API activity and troubleshoot issues as you integrate other systems into your generative AI applications. Amazon Bedrock also allows you to build applications that are in compliance with the GDPR and you can use Amazon Bedrock to run sensitive workloads regulated under the U.S. Health Insurance Portability and Accountability Act (HIPAA).
Get Started with Amazon Bedrock
You can access available FMs in Amazon Bedrock through the AWS Management Console, AWS SDKs, and open-source frameworks such as LangChain.
In the Amazon Bedrock console, you can browse FMs and explore and load example use cases and prompts for each model. First, you need to enable access to the models. In the console, select Model access in the left navigation pane and enable the models you would like to access. Once model access is enabled, you can try out different models and inference configuration settings to find a model that fits your use case.
For example, here’s a contract entity extraction use case example using Cohere’s Command model:

The example shows a prompt with a sample response, the inference configuration parameter settings for the example, and the API request that runs the example. If you select Open in Playground, you can explore the model and use case further in an interactive console experience.
Amazon Bedrock offers chat, text, and image model playgrounds. In the chat playground, you can experiment with various FMs using a conversational chat interface. The following example uses Anthropic’s Claude model:

As you evaluate different models, you should try various prompt engineering techniques and inference configuration parameters. Prompt engineering is a new and exciting skill focused on how to better understand and apply FMs to your tasks and use cases. Effective prompt engineering is about crafting the perfect query to get the most out of FMs and obtain proper and precise responses. In general, prompts should be simple, straightforward, and avoid ambiguity. You can also provide examples in the prompt or encourage the model to reason through more complex tasks.
Inference configuration parameters influence the response generated by the model. Parameters such as Temperature, Top P, and Top K give you control over the randomness and diversity, and Maximum Length or Max Tokens control the length of model responses. Note that each model exposes a different but often overlapping set of inference parameters. These parameters are either named the same between models or similar enough to reason through when you try out different models.
We discuss effective prompt engineering techniques and inference configuration parameters in more detail in week 1 of the Generative AI with Large Language Models on-demand course, developed by AWS in collaboration with DeepLearning.AI. You can also check the Amazon Bedrock documentation and the model provider’s respective documentation for additional tips.
Next, let’s see how you can interact with Amazon Bedrock via APIs.
Using the Amazon Bedrock API
Working with Amazon Bedrock is as simple as selecting an FM for your use case and then making a few API calls. In the following code examples, I’ll use the AWS SDK for Python (Boto3) to interact with Amazon Bedrock.
List Available Foundation Models
First, let’s set up the boto3 client and then use list_foundation_models() to see the most up-to-date list of available FMs:
import boto3
import json
bedrock = boto3.client(
service_name='bedrock',
region='us-east-1'
)
bedrock.list_foundation_models()Run Inference Using Amazon Bedrock’s InvokeModel API
Next, let’s perform an inference request using Amazon Bedrock’s InvokeModel API and boto3 runtime client. The runtime client manages the data plane APIs, including the InvokeModel API.

The InvokeModel API expects the following parameters:
The modelId parameter identifies the FM you want to use. The request body is a JSON string containing the prompt for your task, together with any inference configuration parameters. Note that the prompt format will vary based on the selected model provider and FM. The contentType and accept parameters define the MIME type of the data in the request body and response and default to application/json. For more information on the latest models, InvokeModel API parameters, and prompt formats, see the Amazon Bedrock documentation.
Example: Text Generation Using AI21 Lab’s Jurassic-2 Model
Here is a text generation example using AI21 Lab’s Jurassic-2 Ultra model. I’ll ask the model to tell me a knock-knock joke—my version of a Hello World.
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region='us-east-1'
)
modelId = 'ai21.j2-ultra-v1'
accept = 'application/json'
contentType = 'application/json'
body = json.dumps(
{"prompt": "Knock, knock!",
"maxTokens": 200,
"temperature": 0.7,
"topP": 1,
}
)
response = bedrock_runtime.invoke_model(
body=body,
modelId=modelId,
accept=accept,
contentType=contentType
)
response_body = json.loads(response.get('body').read())Here’s the response:
You can also use the InvokeModel API to interact with embedding models.
Example: Create Text Embeddings Using Amazon’s Titan Embeddings Model
Text embedding models translate text inputs, such as words, phrases, or possibly large units of text, into numerical representations, known as embedding vectors. Embedding vectors capture the semantic meaning of the text in a high-dimension vector space and are useful for applications such as personalization or search. In the following example, I’m using the Amazon Titan Embeddings model to create an embedding vector.
prompt = "Knock-knock jokes are hilarious."
body = json.dumps({
"inputText": prompt,
})
model_id = 'amazon.titan-embed-g1-text-02'
accept = 'application/json'
content_type = 'application/json'
response = bedrock_runtime.invoke_model(
body=body,
modelId=model_id,
accept=accept,
contentType=content_type
)
response_body = json.loads(response['body'].read())
embedding = response_body.get('embedding')The embedding vector (shortened) will look similar to this:
[0.82421875, -0.6953125, -0.115722656, 0.87890625, 0.05883789, -0.020385742, 0.32421875, -0.00078201294, -0.40234375, 0.44140625, ...]
Note that Amazon Titan Embeddings is available today. The Amazon Titan Text family of models for text generation continues to be available in limited preview.
Run Inference Using Amazon Bedrock’s InvokeModelWithResponseStream API
The InvokeModel API request is synchronous and waits for the entire output to be generated by the model. For models that support streaming responses, Bedrock also offers an InvokeModelWithResponseStream API that lets you invoke the specified model to run inference using the provided input but streams the response as the model generates the output.

Streaming responses are particularly useful for responsive chat interfaces to keep the user engaged in an interactive application. Here is a Python code example using Amazon Bedrock’s InvokeModelWithResponseStream API:
response = bedrock_runtime.invoke_model_with_response_stream(
modelId=modelId,
body=body)
stream = response.get('body')
if stream:
for event in stream:
chunk=event.get('chunk')
if chunk:
print(json.loads(chunk.get('bytes').decode))Data Privacy and Network Security
With Amazon Bedrock, you are in control of your data, and all your inputs and customizations remain private to your AWS account. Your data, such as prompts, completions, and fine-tuned models, is not used for service improvement. Also, the data is never shared with third-party model providers.
Your data remains in the Region where the API call is processed. All data is encrypted in transit with a minimum of TLS 1.2 encryption. Data at rest is encrypted with AES-256 using AWS KMS managed data encryption keys. You can also use your own keys (customer managed keys) to encrypt the data.
You can configure your AWS account and virtual private cloud (VPC) to use Amazon VPC endpoints (built on AWS PrivateLink) to securely connect to Amazon Bedrock over the AWS network. This allows for secure and private connectivity between your applications running in a VPC and Amazon Bedrock.
Governance and Monitoring
Amazon Bedrock integrates with IAM to help you manage permissions for Amazon Bedrock. Such permissions include access to specific models, playground, or features within Amazon Bedrock. All AWS-managed service API activity, including Amazon Bedrock activity, is logged to CloudTrail within your account.
Amazon Bedrock emits data points to CloudWatch using the AWS/Bedrock namespace to track common metrics such as InputTokenCount, OutputTokenCount, InvocationLatency, and (number of) Invocations. You can filter results and get statistics for a specific model by specifying the model ID dimension when you search for metrics. This near real-time insight helps you track usage and cost (input and output token count) and troubleshoot performance issues (invocation latency and number of invocations) as you start building generative AI applications with Amazon Bedrock.
Billing and Pricing Models
Here are a couple of things around billing and pricing models to keep in mind when using Amazon Bedrock:
Billing – Text generation models are billed per processed input tokens and per generated output tokens. Text embedding models are billed per processed input tokens. Image generation models are billed per generated image.
Pricing Models – Amazon Bedrock offers two pricing models, on-demand and provisioned throughput. On-demand pricing allows you to use FMs on a pay-as-you-go basis without having to make any time-based term commitments. Provisioned throughput is primarily designed for large, consistent inference workloads that need guaranteed throughput in exchange for a term commitment. Here, you specify the number of model units of a particular FM to meet your application’s performance requirements as defined by the maximum number of input and output tokens processed per minute. For detailed pricing information, see Amazon Bedrock Pricing.
Now Available
Amazon Bedrock is available today in AWS Regions US East (N. Virginia) and US West (Oregon). To learn more, visit Amazon Bedrock, check the Amazon Bedrock documentation, explore the generative AI space at community.aws, and get hands-on with the Amazon Bedrock workshop. You can send feedback to AWS re:Post for Amazon Bedrock or through your usual AWS contacts.
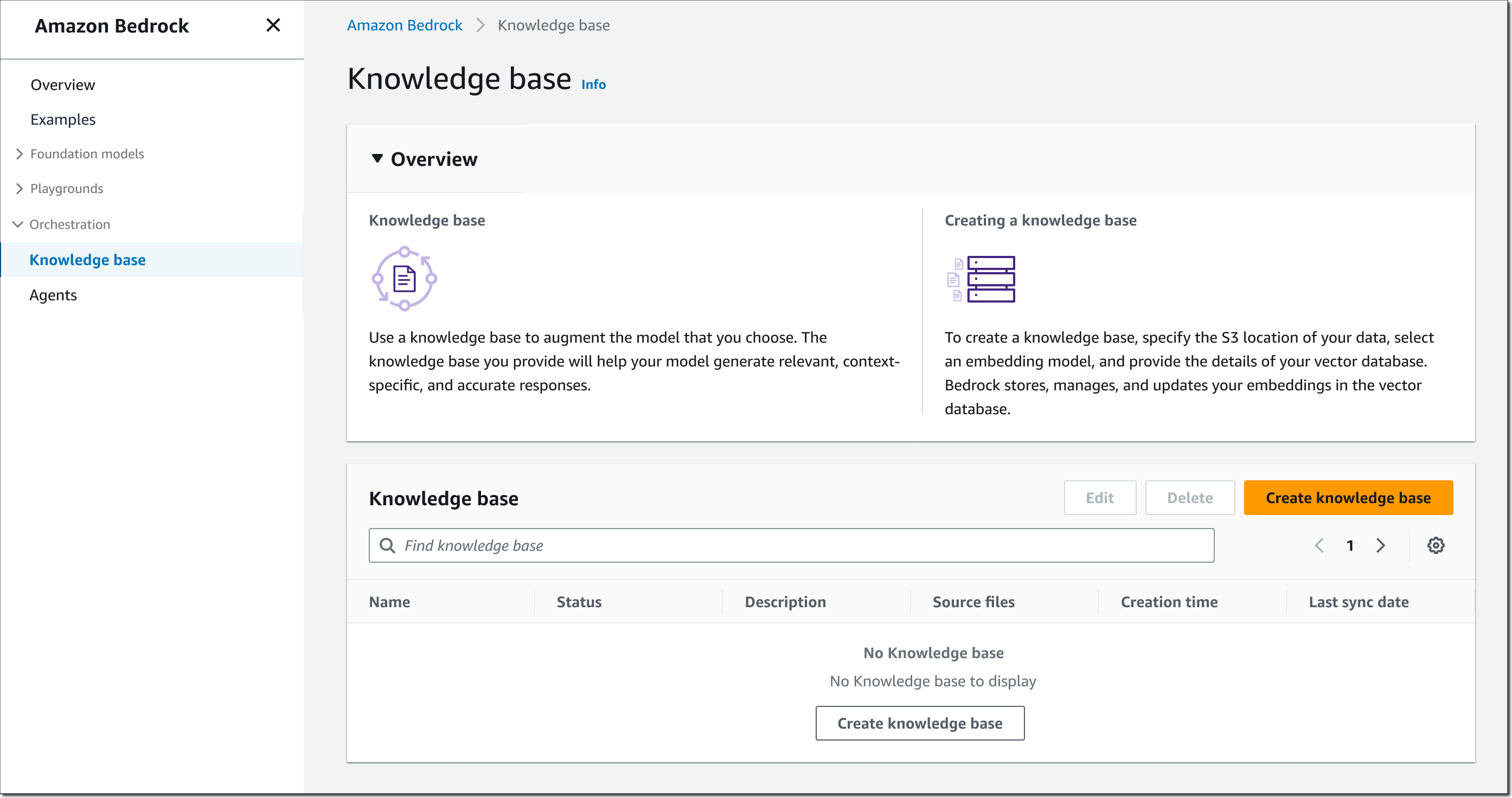
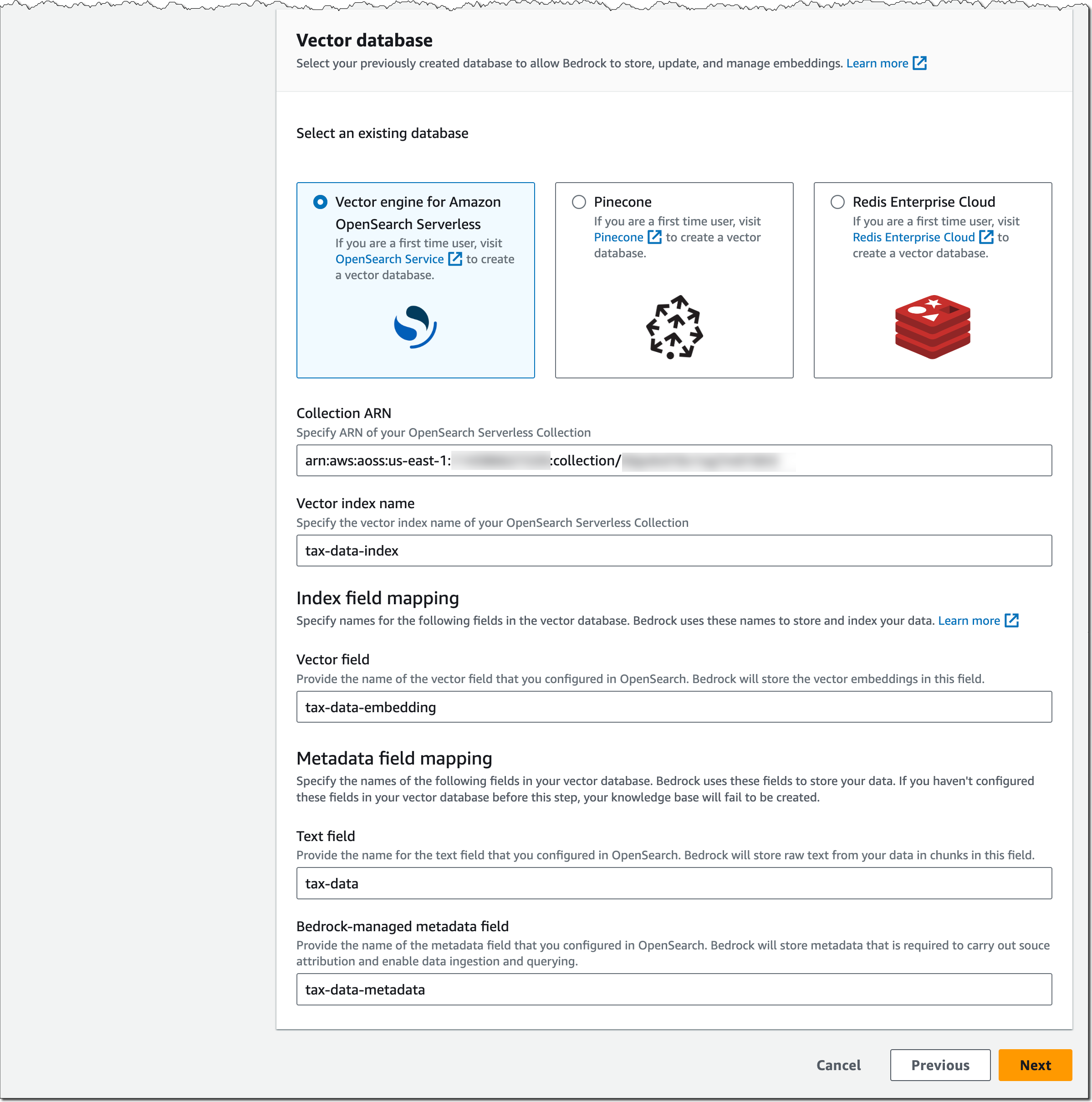
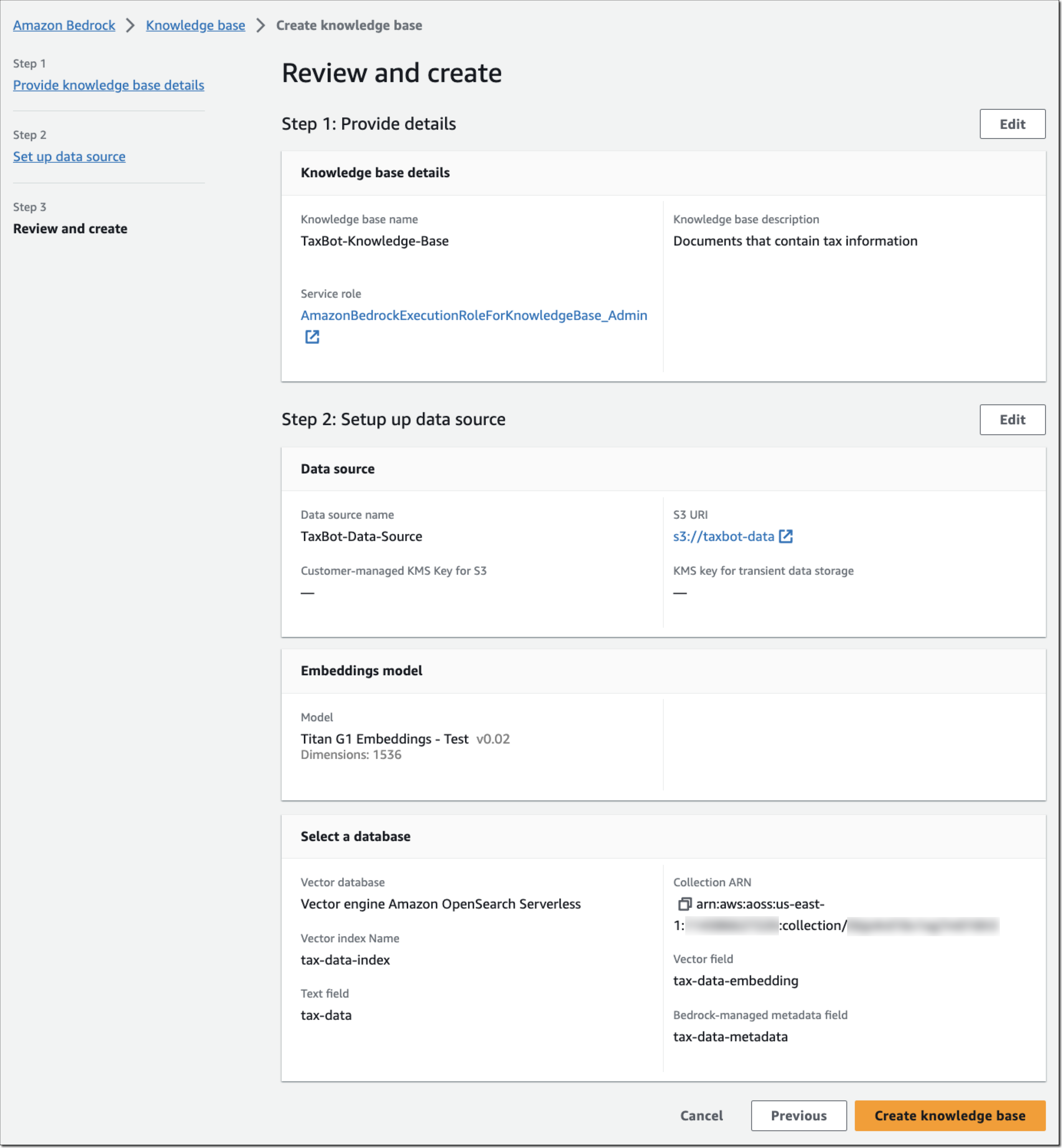
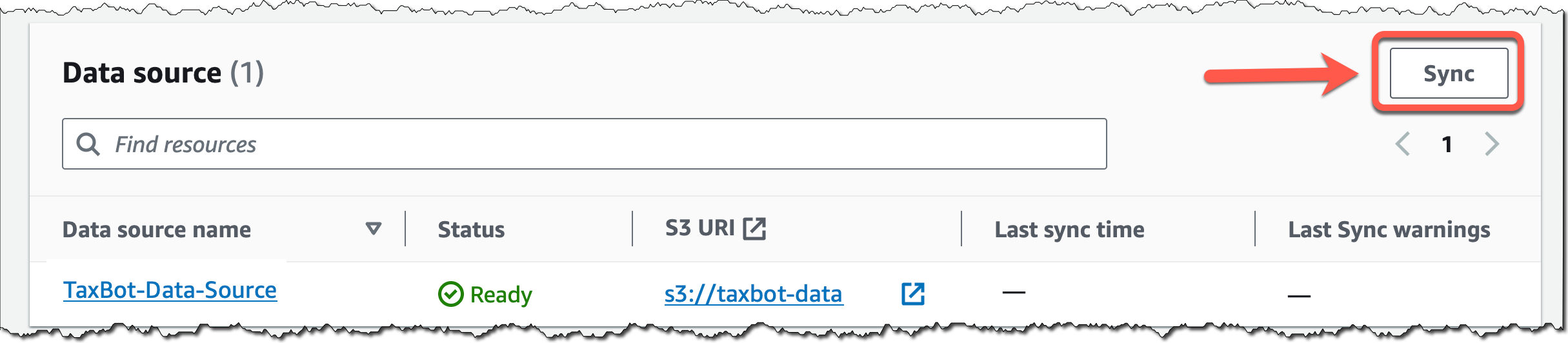
(Available in Preview) The Amazon Titan Text family of text generation models, Stability AI’s Stable Diffusion XL image generation model, and agents for Amazon Bedrock, including knowledge bases, continue to be available in limited preview. Reach out through your usual AWS contacts if you’d like access.
(Coming Soon) The Llama 2 13B and 70B parameter models by Meta will soon be available via Amazon Bedrock’s fully managed API for inference and fine-tuning.
Start building generative AI applications with Amazon Bedrock, today!
— Antje
from AWS News Blog https://ift.tt/BnxvyLr
via IFTTT



 available.
available.