Recent advancements in machine learning (ML) have unlocked opportunities for customers across organizations of all sizes and industries to reinvent new products and transform their businesses. However, the growth in demand for GPU capacity to train, fine-tune, experiment, and inference these ML models has outpaced industry-wide supply, making GPUs a scarce resource. Access to GPU capacity is an obstacle for customers whose capacity needs fluctuate depending on the research and development phase they’re in.
Today, we are announcing Amazon Elastic Compute Cloud (Amazon EC2) Capacity Blocks for ML, a new Amazon EC2 usage model that further democratizes ML by making it easy to access GPU instances to train and deploy ML and generative AI models. With EC2 Capacity Blocks, you can reserve hundreds of GPUs collocated in EC2 UltraClusters designed for high-performance ML workloads, using Elastic Fabric Adapter (EFA) networking in a peta-bit scale non-blocking network, to deliver the best network performance available in Amazon EC2.
This is an innovative new way to schedule GPU instances where you can reserve the number of instances you need for a future date for just the amount of time you require. EC2 Capacity Blocks are currently available for Amazon EC2 P5 instances powered by NVIDIA H100 Tensor Core GPUs in the AWS US East (Ohio) Region. With EC2 Capacity Blocks, you can reserve GPU instances in just a few clicks and plan your ML development with confidence. EC2 Capacity Blocks make it easy for anyone to predictably access EC2 P5 instances that offer the highest performance in EC2 for ML training.
EC2 Capacity Block reservations work similarly to hotel room reservations. With a hotel reservation, you specify the date and duration you want your room for and the size of beds you’d like─a queen bed or king bed, for example. Likewise, with EC2 Capacity Block reservations, you select the date and duration you require GPU instances and the size of the reservation (the number of instances). On your reservation start date, you’ll be able to access your reserved EC2 Capacity Block and launch your P5 instances. At the end of the EC2 Capacity Block duration, any instances still running will be terminated.
You can use EC2 Capacity Blocks when you need capacity assurance to train or fine-tune ML models, run experiments, or plan for future surges in demand for ML applications. Alternatively, you can continue using On-Demand Capacity Reservations for all other workload types that require compute capacity assurance, such as business-critical applications, regulatory requirements, or disaster recovery.
Getting started with Amazon EC2 Capacity Blocks for ML
To reserve your Capacity Blocks, choose Capacity Reservations on the Amazon EC2 console in the US East (Ohio) Region. You can see two capacity reservation options. Select Purchase Capacity Blocks for ML and then Get started to start looking for an EC2 Capacity Block.
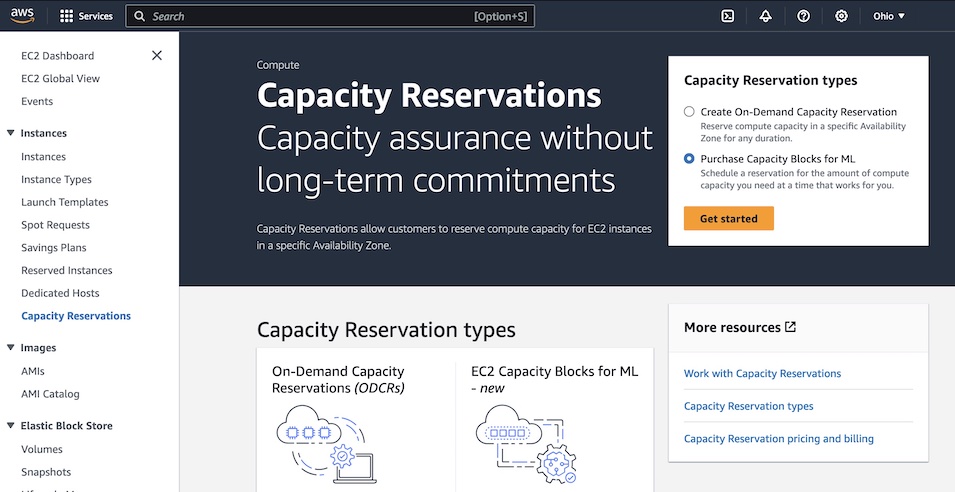
Choose your total capacity and specify how long you need the EC2 Capacity Block. You can reserve an EC2 Capacity Block in the following sizes: 1, 2, 4, 8, 16, 32, or 64 p5.48xlarge instances. The total number of days that you can reserve EC2 Capacity Blocks is 1– 14 days in 1-day increments. EC2 Capacity Blocks can be purchased up to 8 weeks in advance.
EC2 Capacity Block prices are dynamic and depend on total available supply and demand at the time you purchase the EC2 Capacity Block. You can adjust the size, duration, or date range in your specifications to search for other EC2 Capacity Block options. When you select Find Capacity Blocks, AWS returns the lowest-priced offering available that meets your specifications in the date range you have specified. At this point, you will be shown the price for the EC2 Capacity Block.
After reviewing EC2 Capacity Blocks details, tags, and total price information, choose Purchase. The total price of an EC2 Capacity Block is charged up front, and the price does not change after purchase. The payment will be billed to your account within 12 hours after you purchase the EC2 Capacity Blocks.
All EC2 Capacity Blocks reservations start at 11:30 AM Coordinated Universal Time (UTC). EC2 Capacity Blocks can’t be modified or canceled after purchase.
You can also use AWS Command Line Interface (AWS CLI) and AWS SDKs to purchase EC2 Capacity Blocks. Use the describe-capacity-block-offerings API to provide your cluster requirements and discover an available EC2 Capacity Block for purchase.
$ aws ec2 describe-capacity-block-offerings \
--instance-type p5.48xlarge \
--instance-count 4 \
--start-date-range 2023-10-30T00:00:00Z \
--end-date-range 2023-11-01T00:00:00Z \
–-capacity-duration 48After you find an available EC2 Capacity Block with the CapacityBlockOfferingId and capacity information from the preceding command, you can use purchase-capacity-block-reservation API to purchase it.
$ aws ec2 purchase-capacity-block-reservation \
--capacity-block-offering-id cbr-0123456789abcdefg \
–-instance-platform Linux/UNIXFor more information about new EC2 Capacity Blocks APIs, see the Amazon EC2 API documentation.
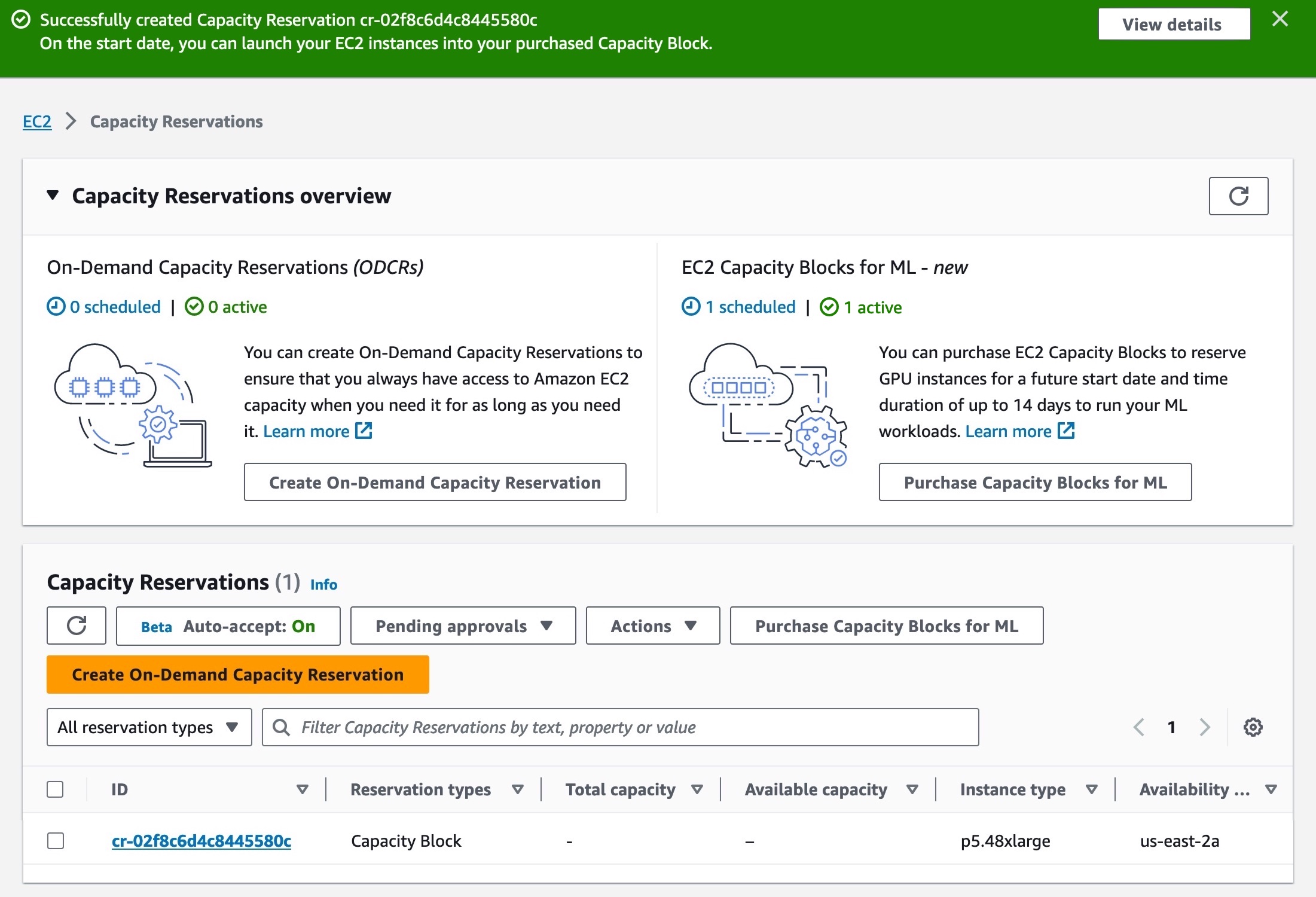
Your EC2 Capacity Block has now been scheduled successfully. On the scheduled start date, your EC2 Capacity Block will become active. To use an active EC2 Capacity Block on your starting date, choose the capacity reservation ID for your EC2 Capacity Block. You can see a breakdown of the reserved instance capacity, which shows how the capacity is currently being utilized in the Capacity details section.
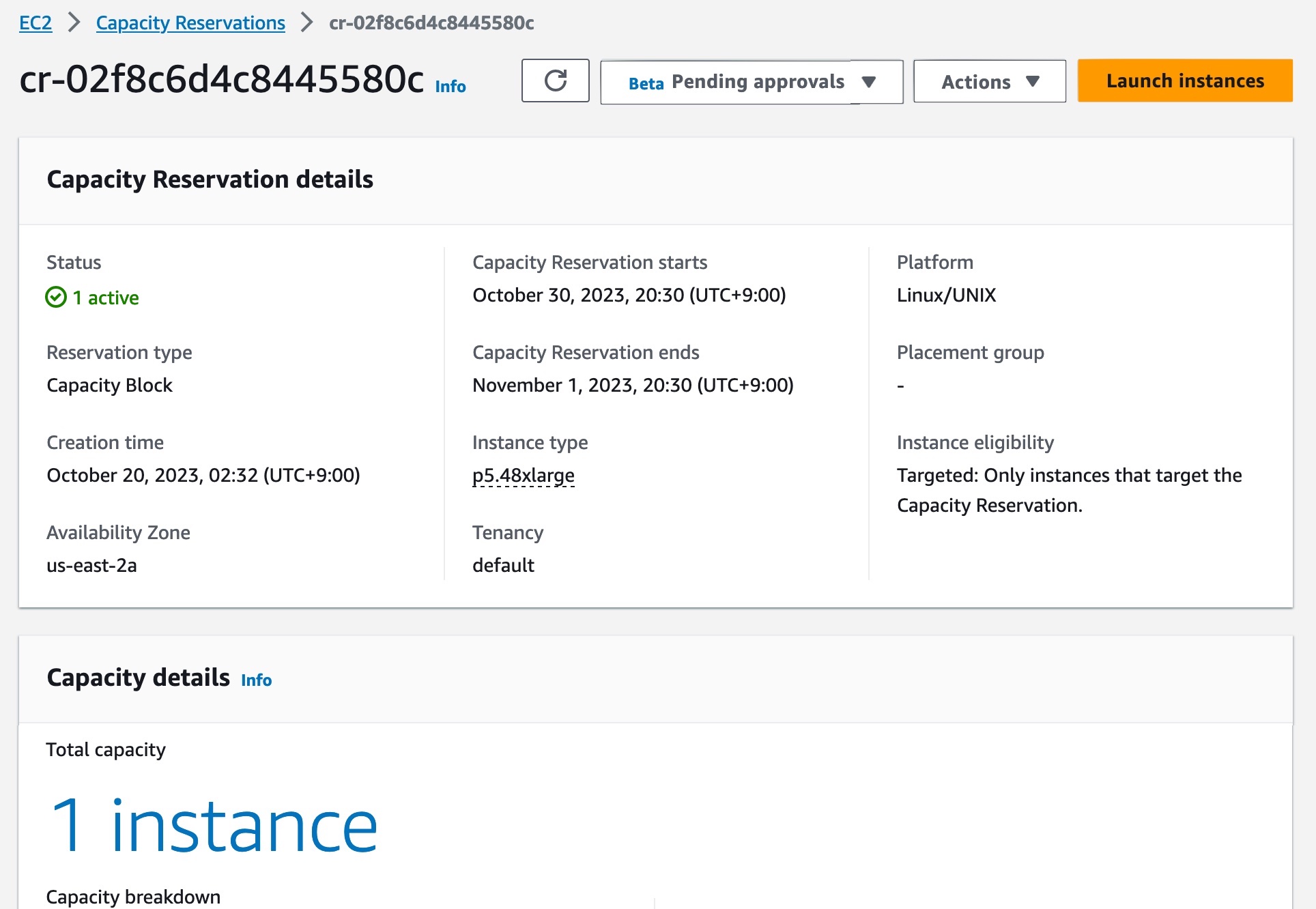
To launch instances into your active EC2 Capacity Block, choose Launch instances and follow the normal process of launching EC2 instances and running your ML workloads.
In the Advanced details section, choose Capacity Blocks as the purchase option and select the capacity reservation ID of the EC2 Capacity Block you’re trying to target.
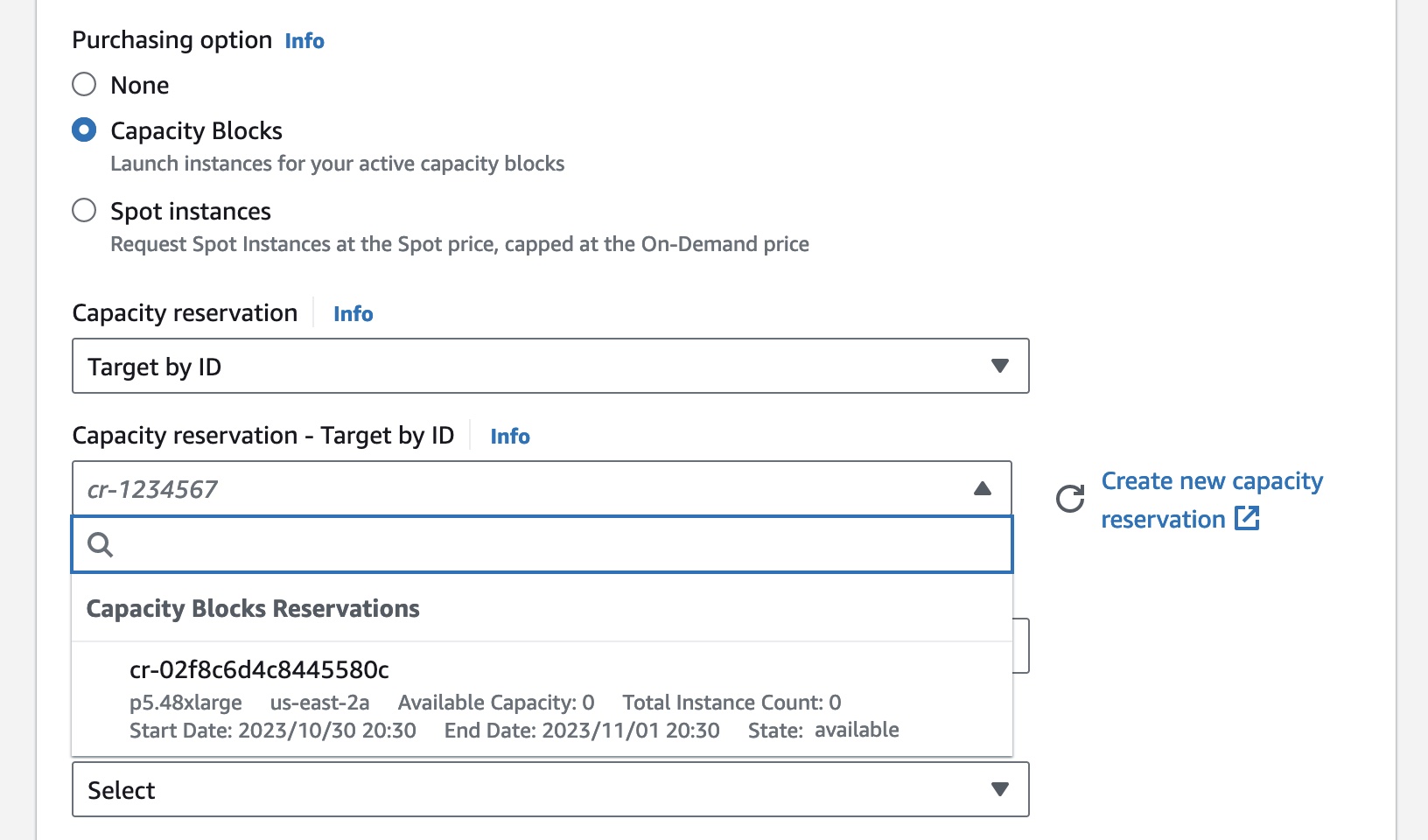
As your EC2 Capacity Block end time approaches, Amazon EC2 will emit an event through Amazon EventBridge, letting you know your reservation is ending soon so you can checkpoint your workload. Any instances running in the EC2 Capacity Block go into a shutting-down state 30 minutes before your reservation ends. The amount you were charged for your EC2 Capacity Block does not include this time period. When your EC2 Capacity Block expires, any instances still running will be terminated.
Now available
Amazon EC2 Capacity Blocks are now available for p5.48xlarge instances in the AWS US East (Ohio) Region. You can view the price of an EC2 Capacity Block before you reserve it, and the total price of an EC2 Capacity Block is charged up-front at the time of purchase. For more information, see the EC2 Capacity Blocks pricing page.
To learn more, see the EC2 Capacity Blocks documentation and send feedback to AWS re:Post for EC2 or through your usual AWS Support contacts.
— Channy
from AWS News Blog https://ift.tt/iHBVTpe
via IFTTT







 Don’t be surprised if you have seen the Certificate Update in the
Don’t be surprised if you have seen the Certificate Update in the