Amazon GuardDuty is a machine learning (ML)-based security monitoring and intelligent threat detection service that analyzes and processes various AWS data sources, continuously monitors your AWS accounts and workloads for malicious activity, and delivers detailed security findings for visibility and remediation.
Today, we are announcing the general availability of Amazon GuardDuty EC2 Runtime Monitoring to expand threat detection coverage for EC2 instances at runtime and complement the anomaly detection that GuardDuty already provides by continuously monitoring VPC Flow Logs, DNS query logs, and AWS CloudTrail management events. You now have visibility into on-host, OS-level activities and container-level context into detected threats.
With GuardDuty EC2 Runtime Monitoring, you can identify and respond to potential threats that might target the compute resources within your EC2 workloads. Threats to EC2 workloads often involve remote code execution that leads to the download and execution of malware. This could include instances or self-managed containers in your AWS environment that are connecting to IP addresses associated with cryptocurrency-related activity or to malware command-and-control related IP addresses.
GuardDuty Runtime Monitoring provides visibility into suspicious commands that involve malicious file downloads and execution across each step, which can help you discover threats during initial compromise and before they become business-impacting events. You can also centrally enable runtime threat detection coverage for accounts and workloads across the organization using AWS Organizations to simplify your security coverage.
Configure EC2 Runtime Monitoring in GuardDuty
With a few clicks, you can enable GuardDuty EC2 Runtime Monitoring in the GuardDuty console. For your first use, you need to enable Runtime Monitoring.
Any customers that are new to the EC2 Runtime Monitoring feature can try it for free for 30 days and gain access to all features and detection findings. The GuardDuty console shows how many days are left in the free trial.
Now, you can set up the GuardDuty security agent for the individual EC2 instances for which you want to monitor the runtime behavior. You can choose to deploy the GuardDuty security agent either automatically or manually. At GA, you can enable Automated agent configuration, which is a preferred option for most customers as it allows GuardDuty to manage the security agent on their behalf.
When you enable EC2 Runtime Monitoring, you can find the covered EC2 instances list, account ID, and coverage status, and whether the agent is able to receive runtime events from the corresponding resource in the EC2 instance runtime coverage tab.
Even when the coverage status is Unhealthy, meaning it is not currently able to receive runtime findings, you still have defense in depth for your EC2 instance. GuardDuty continues to provide threat detection to the EC2 instance by monitoring CloudTrail, VPC flow, and DNS logs associated with it.
Check out GuardDuty EC2 Runtime security findings
When GuardDuty detects a potential threat and generates security findings, you can view the details of the healthy information.
Choose Findings in the left pane if you want to find security findings specific to Amazon EC2 resources. You can use the filter bar to filter the findings table by specific criteria, such as a Resource type of Instance. The severity and details of the findings differ based on the resource role, which indicates whether the EC2 resource was the target of suspicious activity or the actor performing the activity.
With today’s launch, we support over 30 runtime security findings for EC2 instances, such as detecting abused domains, backdoors, cryptocurrency-related activity, and unauthorized communications. For the full list, visit Runtime Monitoring finding types in the AWS documentation.
Resolve your EC2 security findings
Choose each EC2 security finding to know more details. You can find all the information associated with the finding and examine the resource in question to determine if it is behaving in an expected manner.
If the activity is authorized, you can use suppression rules or trusted IP lists to prevent false positive notifications for that resource. If the activity is unexpected, the security best practice is to assume the instance has been compromised and take the actions detailed in Remediating a potentially compromised Amazon EC2 instance in the AWS documentation.
You can integrate GuardDuty EC2 Runtime Monitoring with other AWS security services, such as AWS Security Hub or Amazon Detective. Or you can use Amazon EventBridge, allowing you to use integrations with security event management or workflow systems, such as Splunk, Jira, and ServiceNow, or trigger automated and semi-automated responses such as isolating a workload for investigation.
When you choose Investigate with Detective, you can find Detective-created visualizations for AWS resources to quickly and easily investigate security issues. To learn more, visit Integration with Amazon Detective in the AWS documentation.
Things to know
GuardDuty EC2 Runtime Monitoring support is now available for EC2 instances running Amazon Linux 2 or Amazon Linux 2023. You have the option to configure maximum CPU and memory limits for the agent. To learn more and for future updates, visit Prerequisites for Amazon EC2 instance support in the AWS documentation.
To estimate the daily average usage costs for GuardDuty, choose Usage in the left pane. During the 30-day free trial period, you can estimate what your costs will be after the trial period. At the end of the trial period, we charge you per vCPU hours tracked monthly for the monitoring agents. To learn more, visit the Amazon GuardDuty pricing page.
Enabling EC2 Runtime Monitoring also allows for a cost-saving opportunity on your GuardDuty cost. When the feature is enabled, you won’t be charged for GuardDuty foundational protection VPC Flow Logs sourced from the EC2 instances running the security agent. This is due to similar, but more contextual, network data available from the security agent. Additionally, GuardDuty would still process VPC Flow Logs and generate relevant findings so you will continue to get network-level security coverage even if the agent experiences downtime.
Now available
Amazon GuardDuty EC2 Runtime Monitoring is now available in all AWS Regions where GuardDuty is available, excluding AWS GovCloud (US) Regions and AWS China Regions. For a full list of Regions where EC2 Runtime Monitoring is available, visit Region-specific feature availability.
Amazon Advertising AMC SQL Unveiled: Tips, Tricks, and Hidden Features
One of the barriers to getting started with Amazon Ads Marketing Cloud is understanding the data and how to write AMC SQL. The datasets are complex, and AMC SQL has a steep learning curve.
Ultimately, the goal of tapping into AMC data is to refine advertising strategy, have a deeper insight into AMC audiences and segments, and create a feedback loop where you have the capabilities to create actionable insights rapidly to optimize advertising campaigns.
This post demonstrates various examples of AMC SQL queries and how to gain free access to an AMC SQL Data Analyst AI copilot.
Using An AMC AI Data Copilot!
Most people interested in AMC are not data scientists or software engineers with the skills to author structured query language (SQL) queries against complex AMC data.
To lower barriers and increase velocity with AMC, we released “Chatlytics,” a free Amazon Marketing Cloud data analyst AI copilot trained on all things Amazon Marketing Cloud SQL. Using the Chatlytics data analyst copilot is as simple as starting a conversation about your AMC query or dataset.
When you're stuck hunting down a SQL error or exploring new ways to create insights, ask the AMC AI Data Analyst Copilot*.
*This post's SQL, analysis, and visualizations were all developed in collaboration with the AMC SQL AI Copilot!
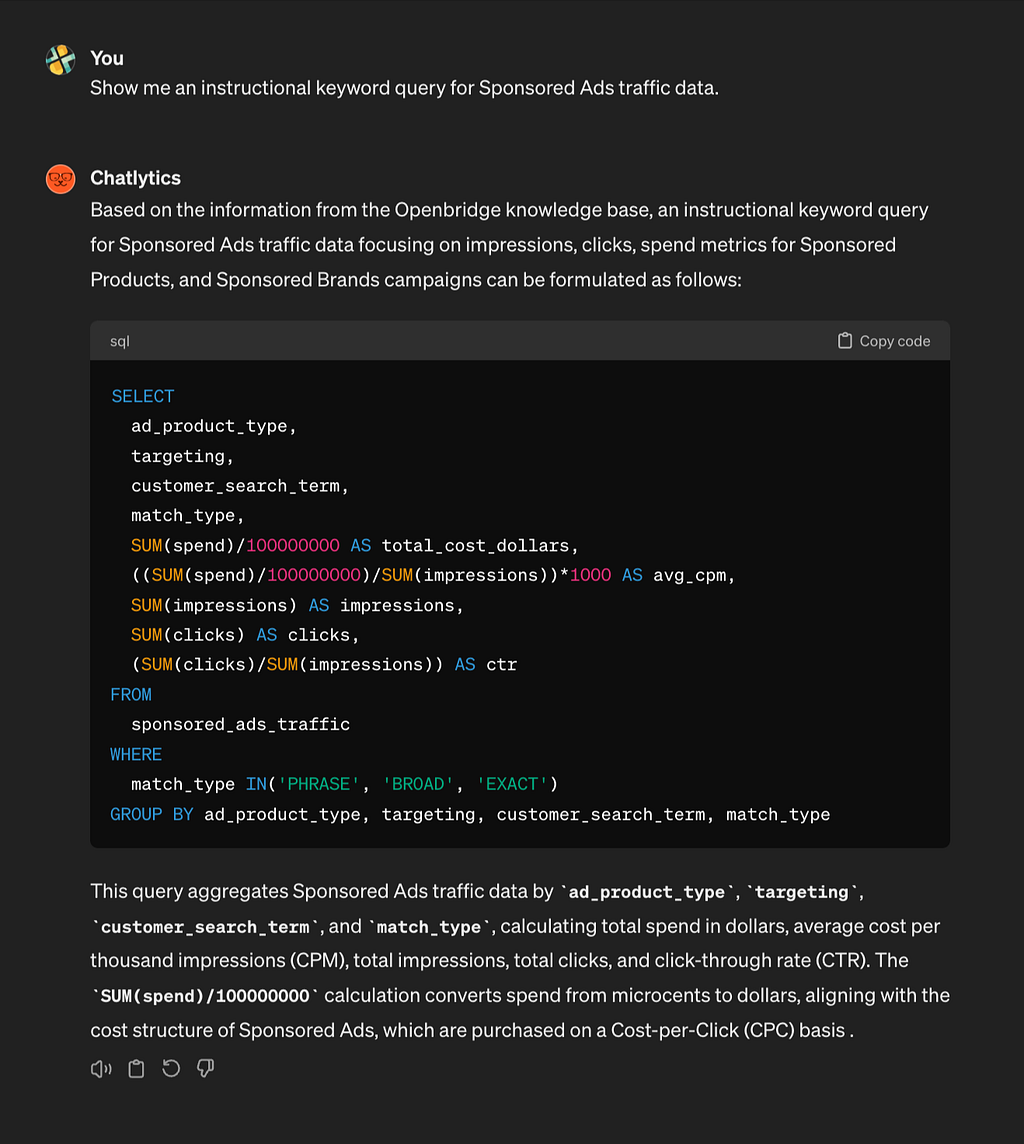
Sponsored Ads Traffic AMC SQL
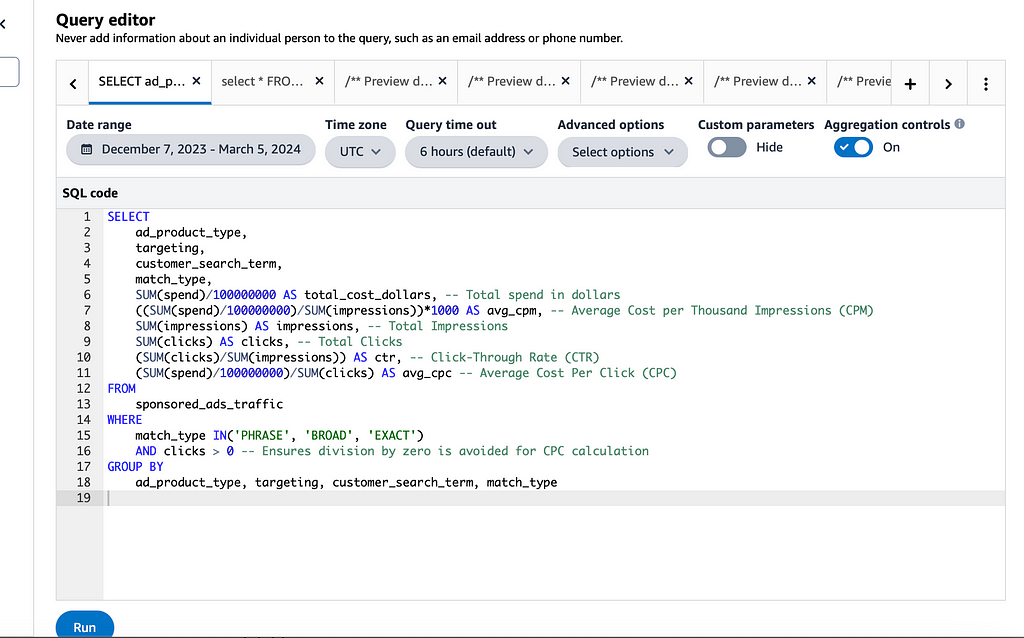
AMC covers Amazon DSP, Amazon Sponsored Ads (like Sponsored Products), Amazon Attribution, and other AMC data sets. In this example is a query for retrieving impressions, clicks, and spending metrics for Sponsored Products and Sponsored brand campaigns from the sponsored_ads_traffic table:
SELECT ad_product_type, targeting, customer_search_term, match_type, SUM(spend)/100000000 AS total_cost_dollars, ((SUM(spend)/100000000)/SUM(impressions))*1000 AS avg_cpm, SUM(impressions) AS impressions, SUM(clicks) AS clicks, (SUM(clicks)/SUM(impressions)) AS ctr FROM sponsored_ads_traffic WHERE match_type IN('PHRASE', 'BROAD', 'EXACT') GROUP BY ad_product_type, targeting, customer_search_term, match_type
This query calculates total spend in dollars, the average cost per thousand impressions (avg_cpm), total impressions, total clicks, and click-through rate (ctr) for Sponsored Products and Sponsored Brands campaigns. The query filters data for specific match types (PHRASE, BROAD, EXACT) and groups the results by ad_product_type, targeting, customer_search_term, and match_type .
Based on the Openbridge knowledge base, here are five instructional AMC SQL queries designed to cover a range of fundamental concepts and operations in AMC SQL. These queries offer a structured approach to learning AMC SQL, focusing on different aspects such as aggregation, join operations, conditional logic, and advanced analytics.
Aggregate Impressions and Clicks by Campaign:
SELECT SUM(c.clicks) AS total_clicks, COALESCE(SUM(a.conversions), 0) AS total_conversions FROM dsp_clicks c LEFT JOIN amazon_attributed_events_by_conversion_time a ON c.request_tag = a.request_tag
DSP Clicks advertiser performance, campaign details, and cost efficiency
Here's an instructional AMC SQL example query for analyzing DSP (Demand Side Platform) clicks data focusing on advertiser performance, campaign details, and cost efficiency. This query aims to aggregate click data by advertiser, campaign, and device type, offering insights into the effectiveness of different campaigns and the devices on which they perform best.
SELECT advertiser, campaign, device_type, COUNT(clicks) AS total_clicks, -- Aggregating the total number of clicks SUM(click_cost)/100000 AS total_click_cost_dollars, -- Convert click cost from millicents to dollars AVG(click_cost)/100 AS avg_click_cost_cents, -- Calculate average click cost in cents MAX(click_cost)/100 AS max_click_cost_cents, -- Identify the maximum click cost in cents for benchmarking MIN(click_cost)/100 AS min_click_cost_cents -- Find the minimum click cost in cents for optimization opportunities FROM dsp_clicks GROUP BY advertiser, campaign, device_type
This query performs the following operations:
Groups, the DSP clicks data by advertiser, campaign, and device type to analyze performance across these dimensions.
Counts the total number of clicks (total_clicks) for each group to measure engagement.
Calculate the total click cost in dollars (total_click_cost_dollars), converting from millicents to ensure the cost is easily interpretable.
Computes the average, maximum, and minimum click costs (avg_click_cost_cents, max_click_cost_cents, min_click_cost_cents), providing insights into cost variability and efficiency across campaigns.
DSP Impresssion and DSP Clicks
Here's an instructional AMC SQL example for an analysis that combines DSP impressions and clicks data to evaluate campaign performance, including impressions, clicks, and click-through rate (CTR). This query joins the dsp_impressions and dsp_clicks tables on campaign and advertiser IDs, providing a comprehensive view of campaign effectiveness across different devices and browsers.
WITH impressions AS ( SELECT advertiser_id, campaign_id, device_type, COUNT(impression_date) AS total_impressions -- Assuming 'impression_date' can represent each unique impression FROM dsp_impressions GROUP BY advertiser_id, campaign_id, device_type ), clicks AS ( SELECT advertiser_id, campaign_id, COUNT(click_date) AS total_clicks -- Assuming 'click_date' can represent each unique click FROM dsp_clicks GROUP BY advertiser_id, campaign_id ), combined_data AS ( SELECT i.advertiser_id, i.campaign_id, i.device_type, i.total_impressions, COALESCE(c.total_clicks, 0) AS total_clicks FROM impressions i LEFT JOIN clicks c ON i.advertiser_id = c.advertiser_id AND i.campaign_id = c.campaign_id )
SELECT advertiser_id, campaign_id, device_type, total_impressions, total_clicks, CASE WHEN total_impressions > 0 THEN ROUND((total_clicks / total_impressions) * 100, 2) ELSE 0 END AS ctr FROM combined_data
In this query, we:
Create separate CTEs (impressions and clicks) to aggregate total impressions and clicks by advertiser_id and campaign_id, counting occurrences based on the existence of impression_date and click_date, respectively.
Join these CTEs in combined_data to align clicks with their corresponding impressions.
Calculate the CTR as (total_clicks / total_impressions) * 100, rounding to two decimal places where applicable, with safeguards against division by zero.
This approach ensures compliance with AMC’s SQL requirements and provides an analysis framework for DSP campaign performance across different device types.
To extend the approach to include dsp_views dsp_impressions and dsp_clicks, creating a more comprehensive analysis of DSP data, we'll introduce another CTE for views. This will aggregate total views alongside impressions and clicks for each campaign and advertiser. This updated query will provide insights into how many impressions and clicks each campaign received and how many impressions were viewable.
WITH impressions AS ( SELECT advertiser_id, campaign_id, device_type, COUNT(impression_date) AS total_impressions -- Assuming 'impression_date' represents each unique impression FROM dsp_impressions GROUP BY advertiser_id, campaign_id, device_type ), clicks AS ( SELECT advertiser_id, campaign_id, COUNT(click_date) AS total_clicks -- Assuming 'click_date' represents each unique click FROM dsp_clicks GROUP BY advertiser_id, campaign_id ), views AS ( SELECT advertiser_id, campaign_id, COUNT(event_date) AS total_views -- Assuming 'event_date' can represent each unique view FROM dsp_views GROUP BY advertiser_id, campaign_id ), combined_data AS ( SELECT i.advertiser_id, i.campaign_id, i.device_type, i.total_impressions, COALESCE(c.total_clicks, 0) AS total_clicks, COALESCE(v.total_views, 0) AS total_views FROM impressions i LEFT JOIN clicks c ON i.advertiser_id = c.advertiser_id AND i.campaign_id = c.campaign_id LEFT JOIN views v ON i.advertiser_id = v.advertiser_id AND i.campaign_id = v.campaign_id )
SELECT advertiser_id, campaign_id, device_type, total_impressions, total_clicks, total_views, CASE WHEN total_impressions > 0 THEN ROUND((total_clicks / total_impressions) * 100, 2) ELSE 0 END AS ctr, CASE WHEN total_impressions > 0 THEN ROUND((total_views / total_impressions) * 100, 2) ELSE 0 END AS view_rate FROM combined_data
This query includes:
A CTE named views to count the total number of views (total_views) for each combination of advertiser_id and campaign_id.
An updated combined_data CTE that joins the views data with impressions and clicks to align views alongside clicks and impressions for the same campaign and advertiser.
Calculations for both CTR and view rate (view_rate), where view rate is defined as the percentage of viewable impressions using logic similar to CTR calculation.
The query offers a multi-dimensional view of DSP campaign performance, incorporating the engagement metrics (clicks) and the visibility of ads (views) across different devices. This enhanced analysis allows advertisers to understand which campaigns generate interactions and which are effectively reaching and being seen by the audience.
Calculating DSP Campaign and Sponsored Display Campaign Costs
Combining the principles from the DSP campaigns and Sponsored Display campaigns, the goal is to create a comprehensive query that calculates the costs for both types of campaigns in one unified view. This query will incorporate conversion from millicents and microcents to dollars for DSP ads and Sponsored Display ads, respectively, while accounting for the different billing strategies of CPC (Cost Per Click) and vCPM (Cost per thousand viewable impressions) for Sponsored Display.
-- DSP Campaigns Cost Calculation WITH dsp_campaign_costs AS ( SELECT CAST('DSP Campaign' AS VARCHAR(255)) AS campaign_type, CAST(campaign_id AS VARCHAR(255)) AS campaign_id, CAST(campaign AS VARCHAR(255)) AS campaign_name, CAST(currency_name AS VARCHAR(255)) AS currency_name, CAST(currency_iso_code AS VARCHAR(255)) AS currency_iso_code, CAST(SUM(impression_cost) / 100000.0 AS DECIMAL(10, 2)) AS impression_cost_dollars, CAST(SUM(total_cost) / 100000.0 AS DECIMAL(10, 2)) AS total_cost_dollars FROM dsp_impressions GROUP BY campaign_id, campaign, currency_name, currency_iso_code ),
-- Sponsored Display Campaigns Cost Calculation sponsored_display_costs AS ( SELECT CAST('Sponsored Display Campaign' AS VARCHAR(255)) AS campaign_type, CAST(NULL AS VARCHAR(255)) AS campaign_id, -- Explicitly casting NULL for campaign_id CAST(campaign AS VARCHAR(255)) AS campaign, CAST(NULL AS VARCHAR(255)) AS currency_name, -- Assuming uniform currency, explicitly casting NULL CAST(NULL AS VARCHAR(255)) AS currency_iso_code, -- Assuming uniform currency, explicitly casting NULL CAST(0.0 AS DECIMAL(10,2)) AS impression_cost_dollars, -- Placeholder for consistent column structure CAST(SUM(spend) / 100000000.0 AS DECIMAL(10, 2)) AS spend_dollars FROM sponsored_ads_traffic WHERE ad_product_type = 'sponsored_display' GROUP BY campaign )
-- Final Selection with explicit casts to ensure data type consistency across UNION ALL SELECT campaign_type, campaign_id, campaign_name, currency_name, currency_iso_code, impression_cost_dollars, total_cost_dollars FROM dsp_campaign_costs
UNION ALL
SELECT campaign_type, campaign_id, campaign, currency_name, currency_iso_code, impression_cost_dollars, spend_dollars AS total_cost_dollars -- Matching the column name and data type in the SELECT above FROM sponsored_display_costs ORDER BY campaign_type, campaign_name;
Explicit Data Type Specifications: All literals and NULL values are cast to VARCHAR(255) to ensure consistency across the UNION ALL operation. This includes campaign types, campaign IDs (where applicable), and currency fields.
Decimal Calculations: Monetary values converted from microcents/millicents to dollars are explicitly cast as DECIMAL(10, 2) to ensure precise financial reporting and to match data types across the unioned parts.
Placeholder Values for Sponsored Display: For columns in the Sponsored Display section that don’t have a direct counterpart in DSP campaigns (like currency_name, currency_iso_code, and impression_cost_dollars), placeholders are used with explicit casting to ensure column data type alignment.
Ad-attributed Branded Searches
Calculating the branded search rate and cost per branded search streamlines the analysis of ad-attributed branded searches. The objective is to create a comprehensive view that captures the branded search activity and offers insights into its efficiency and cost-effectiveness. The optimization simplifies data handling and ensures all calculations are done within a cohesive query structure.
WITH branded_searches AS ( SELECT ae.campaign_id, ae.campaign, SUBSTRING(ae.tracked_item FROM 9) AS keyword, -- Extracting the keyword explicitly COUNT(ae.conversions) AS number_of_branded_searches -- Counting conversions explicitly FROM amazon_attributed_events_by_conversion_time ae WHERE ae.tracked_item LIKE 'keyword%' -- Ensuring LIKE is used for pattern matching GROUP BY ae.campaign_id, ae.campaign, SUBSTRING(ae.tracked_item FROM 9) ), campaign_costs AS ( SELECT di.campaign_id, di.campaign, SUM(di.impressions) AS total_impressions, SUM(di.impression_cost) / 100000.0 AS total_impression_cost_dollars -- Converting millicents to dollars FROM dsp_impressions di GROUP BY di.campaign_id, di.campaign ), -- Merging branded searches with campaign costs for analysis campaign_analysis AS ( SELECT cc.campaign_id AS campaign_id, cc.campaign AS campaign_name, bs.keyword AS branded_keyword, cc.total_impressions AS impressions, cc.total_impression_cost_dollars AS impression_cost_dollars, COALESCE(bs.number_of_branded_searches, 0) AS branded_searches_count FROM campaign_costs cc LEFT JOIN branded_searches bs ON cc.campaign_id = bs.campaign_id ) SELECT campaign_id, campaign_name, branded_keyword, impressions, impression_cost_dollars, branded_searches_count, CASE WHEN impressions > 0 THEN CAST(branded_searches_count AS FLOAT) / CAST(impressions AS FLOAT) ELSE 0.0 END AS branded_search_rate, CASE WHEN branded_searches_count > 0 THEN impression_cost_dollars / CAST(branded_searches_count AS FLOAT) ELSE 0.0 END AS cost_per_branded_search FROM campaign_analysis
Integration of Branded Searches and Campaign Metrics: The branded_searches CTE isolates branded search events while campaign_metrics aggregating campaign-level metrics like impressions and cost. The combined_data CTE then merges these datasets to provide a comprehensive view.
Efficient Calculation of Metrics: By combining data incombined_data, we enable direct calculation of the branded search rate and cost per branded search within a single SELECT statement, improving query efficiency and readability.
Conditional Aggregations: The use of CASE statements ensure safe division, avoiding division by zero and ensuring the calculations only proceed when valid data is available.
Explicit Data Handling: Converting impression costs from millicents to dollars in the campaign_metrics CTE ensures clarity and consistency in cost reporting across different data sources.
This approach streamlines the analysis process and ensures that the insights derived from the DSP campaign performance regarding branded searches are accurate, comprehensive, and actionable, aligning with the intended use case of optimizing analysis for brand search.
From AMC SQL to AMC Insights
What can you do with the results of AMC SQL queries? A lot! Here are just a few examples of the types of analysis you can undertake data analysis and visualization to optimize advertising strategies on the same result set.
CTR Performance by Device Type
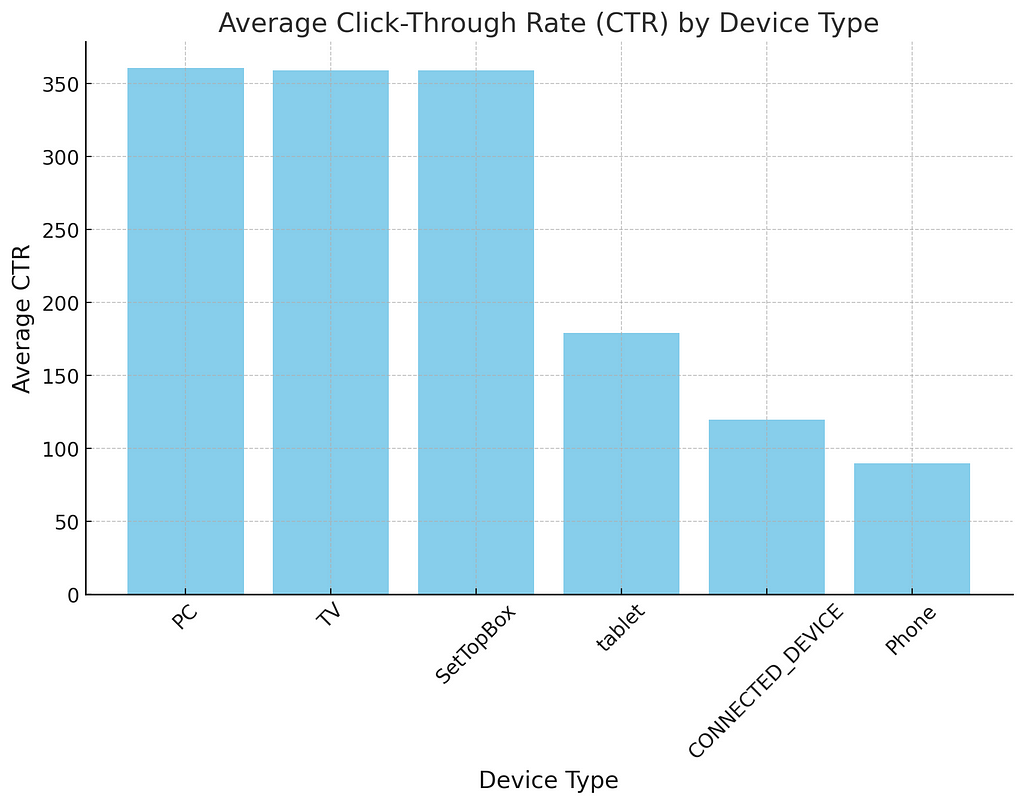
The AMC SQL results allow us to calculate the average CTR for each device type across all campaigns to identify which devices yield higher engagement. This could help focus advertising efforts on the most effective devices.
A bar chart comparing the average CTR across different device types (e.g., Connected Device, PC, Phone, SetTopBox, TV) would visually highlight the devices with higher engagement.
The analysis reveals each device type's average Click-Through Rate (CTR), indicating significant variations across different devices. Here’s a summary of the findings, sorted from highest to lowest average CTR:
PC: 360.75
TV: 359.21
SetTopBox: 359.08
Tablet: 179.18
Connected Device: 119.73
Phone: 89.69
These results suggest that advertising on PCs, TVs, and SetTopBoxes yields the highest engagement in terms of CTR, while Phones and Connected Devices have the lowest. Advertising strategies might be optimized by allocating more resources to the higher-performing device types or by exploring ways to improve engagement on the underperforming ones.
Next, let’s visualize these findings with a bar chart to better illustrate the differences in CTR across device types.
The bar chart visually represents the average Click-Through Rate (CTR) by device type, highlighting the significant variance in CTR across different devices. PCs, TVs, and SetTopBoxes show the highest average CTR, suggesting these platforms are more effective for engaging users with advertisements. Conversely, Phones and Connected Devices exhibit lower CTRs, indicating potential areas for optimization or strategy adjustment.
This analysis suggests focusing advertising efforts on the higher-performing devices or investigating strategies to enhance engagement on platforms with lower CTRs. Adjusting creative content, ad placement, or targeting criteria could improve performance on underperforming devices.
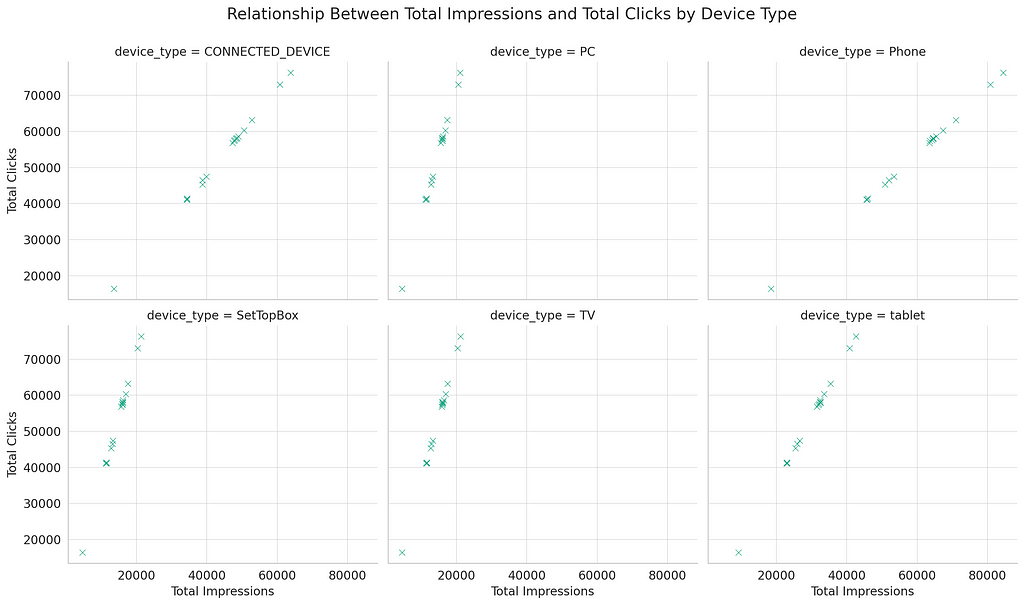
Impressions and Clicks Relationship
The outputs of the AMC SQL allow us to investigate the relationship between the number of impressions and clicks across different device types. This could identify if more impressions always lead to more clicks or if there’s a saturation point beyond which additional impressions don’t translate into proportionally more clicks.
Scatter plots for each device type, with total impressions on the X-axis and total clicks on the Y-axis, could help visualize this relationship. Adding a trend line would make it easier to see if the relationship is linear or if diminishing returns are evident.
The scatter plots illustrate the relationship between total impressions and clicks for each device type. Here are some observations:
For most device types, there appears to be a positive relationship between the number of impressions and the number of clicks, indicating that, generally, more impressions lead to more clicks.
The density and distribution of points vary across device types, suggesting differences in how users engage with ads on these platforms.
Certain device types might show signs of saturation or diminishing returns, where beyond a certain point, increases in impressions do not lead to proportional increases in clicks. This effect would be easier to identify with a larger dataset or by applying trend lines.
These insights can help inform advertising strategies by identifying optimal levels of ad exposure across different devices and adjusting campaign efforts to maximize engagement without overspending on impressions that do not convert to clicks.
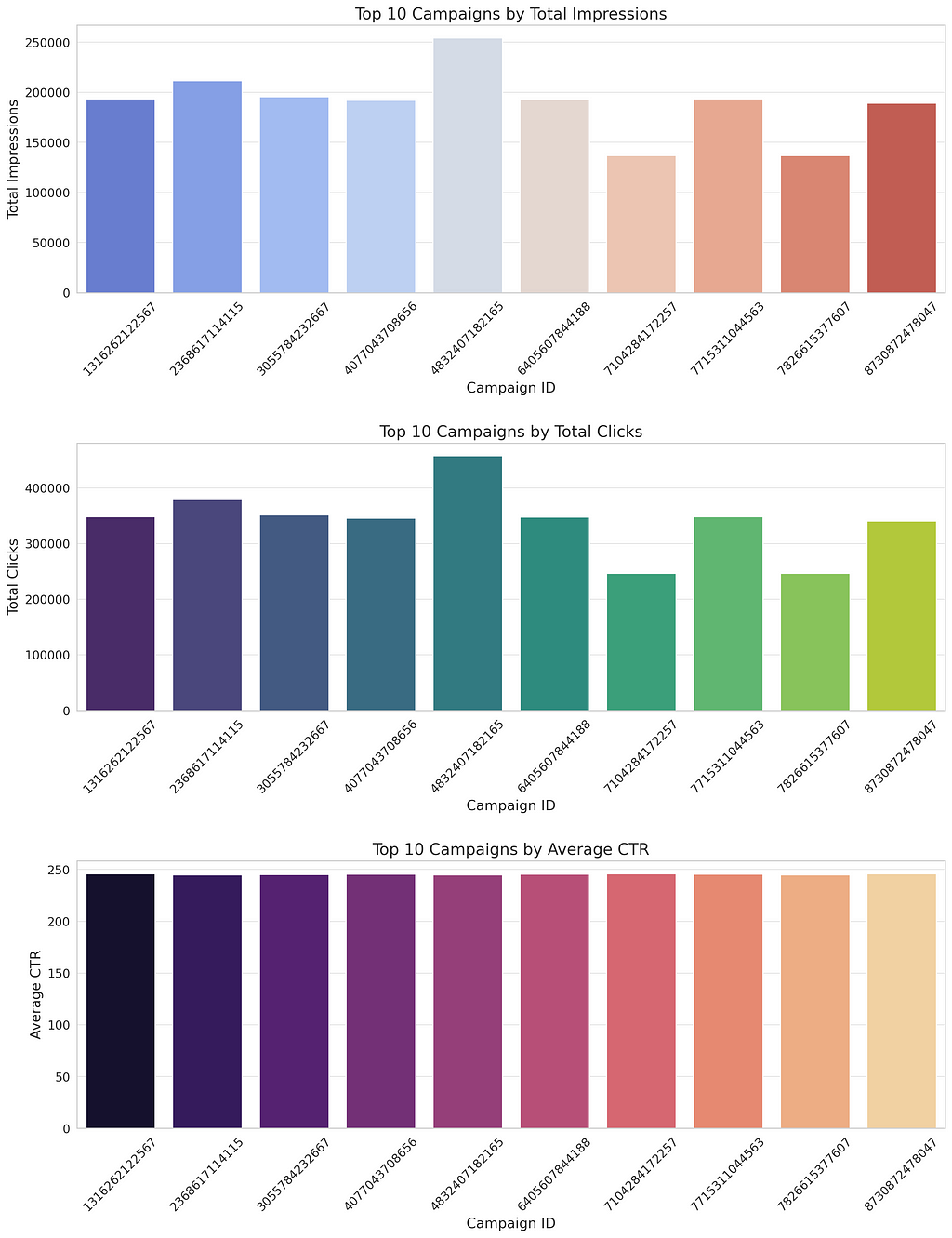
Campaign Performance Analysis
Calculate each campaign's key performance indicators, such as impressions, clicks, and average CTR. This can help identify high-performing campaigns and understand the characteristics that contribute to their success.
The dashboard-like visualization presents the performance metrics of the top 10 campaigns, focusing on Total Impressions, Total Clicks, and Average Click-Through Rate (CTR). This comparative view allows for a more straightforward analysis of what makes these campaigns successful and offers insights into optimizing future advertising strategies:
The Total Impressions chart shows each campaign's reach. Campaigns with higher impressions have the potential for broader visibility.
The Total Clicks chart reflects the engagement level, indicating how often users interacted with the ads.
The Average CTR chart highlights each campaign's efficiency in converting impressions into clicks, a key measure of ad effectiveness.
Analyzing these metrics together provides a comprehensive view of campaign performance, helping identify strengths to replicate and areas for improvement. For example, campaigns with high impressions but lower CTRs may need to refine targeting or creative content, while those with high CTRs demonstrate successful engagement strategies worth emulating.
Starting today, administrators of package repositories can manage the configuration of multiple packages in one single place with the new AWS CodeArtifact package group configuration capability. A package group allows you to define how packages are updated by internal developers or from upstream repositories. You can now allow or block internal developers to publish packages or allow or block upstream updates for a group of packages.
CodeArtifact is a fully managed package repository service that makes it easy for organizations to securely store and share software packages used for application development. You can use CodeArtifact with popular build tools and package managers such as NuGet, Maven, Gradle, npm, yarn, pip, twine, and the Swift Package Manager.
CodeArtifact supports on-demand importing of packages from public repositories such as npmjs.com, maven.org, and pypi.org. This allows your organization’s developers to fetch all their packages from one single source of truth: your CodeArtifact repository.
Simple applications routinely include dozens of packages. Large enterprise applications might have hundreds of dependencies. These packages help developers speed up the development and testing process by providing code that solves common programming challenges such as network access, cryptographic functions, or data format manipulation. These packages might be produced by other teams in your organization or maintained by third parties, such as open source projects.
To minimize the risks of supply chain attacks, some organizations manually vet the packages that are available in internal repositories and the developers who are authorized to update these packages. There are three ways to update a package in a repository. Selected developers in your organization might push package updates. This is typically the case for your organization’s internal packages. Packages might also be imported from upstream repositories. An upstream repository might be another CodeArtifact repository, such as a company-wide source of approved packages or external public repositories offering popular open source packages.
Here is a diagram showing different possibilities to expose a package to your developers.
When managing a repository, it is crucial to define how packages can be downloaded and updated. Allowing package installation or updates from external upstream repositories exposes your organization to typosquatting or dependency confusion attacks, for example. Imagine a bad actor publishing a malicious version of a well-known package under a slightly different name. For example, instead of coffee-script, the malicious package is cofee-script, with only one “f.” When your repository is configured to allow retrieval from upstream external repositories, all it takes is a distracted developer working late at night to type npm install cofee-script instead of npm install coffee-script to inject malicious code into your systems.
CodeArtifact defines three permissions for the three possible ways of updating a package. Administrators can allow or block installation and updates coming from internal publish commands, from an internal upstream repository, or from an external upstream repository.
Until today, repository administrators had to manage these important security settings package by package. With today’s update, repository administrators can define these three security parameters for a group of packages at once. The packages are identified by their type, their namespace, and their name. This new capability operates at the domain level, not the repository level. It allows administrators to enforce a rule for a package group across all repositories in their domain. They don’t have to maintain package origin controls configuration in every repository.
Let’s see in detail how it works Imagine that I manage an internal package repository with CodeArtifact and that I want to distribute only the versions of the AWS SDK for Python, also known as boto3, that have been vetted by my organization.
I navigate to the CodeArtifact page in the AWS Management Console, and I create a python-aws repository that will serve vetted packages to internal developers.
This creates a staging repository in addition to the repository I created. The external packages from pypi will first be staged in the pypi-store internal repository, where I will verify them before serving them to the python-aws repository. Here is where my developers will connect to download them.
By default, when a developer authenticates against CodeArtifact and types pip install boto3, CodeArtifact downloads the packages from the public pypi repository, stages them on pypi-store, and copies them on python-aws.
Now, imagine I want to block CodeArtifact from fetching package updates from the upstream external pypi repository. I want python-aws to only serve packages that I approved from my pypi-store internal repository.
With the new capability that we released today, I can now apply this configuration for a group of packages. I navigate to my domain and select the Package Groups tab. Then, I select the Create Package Group button.
I enter the Package group definition. This expression defines what packages are included in this group. Packages are identified using a combination of three components: package format, an optional namespace, and name.
Here are a few examples of patterns that you can use for each of the allowed combinations:
All package formats: /*
A specific package format: /npm/*
Package format and namespace prefix: /maven/com.amazon~
Package format and namespace: /npm/aws-amplify/*
Package format, namespace, and name prefix: /npm/aws-amplify/ui~
Package format, namespace, and name: /maven/org.apache.logging.log4j/log4j-core$
I invite you to read the documentation to learn all the possibilities.
In my example, there is no concept of namespace for Python packages, and I want the group to include all packages with names starting with boto3 coming from pypi. Therefore, I write /pypi//boto3~.
Then, I define the security parameters for my package group. In this example, I don’t want my organization’s developers to publish updates. I also don’t want CodeArtifact to fetch new versions from the external upstream repositories. I want to authorize only package updates from my internal staging directory.
I uncheck all Inherit from parent group boxes. I select Block for Publish and External upstream. I leave Allow on Internal upstream. Then, I select Create Package Group.
Once defined, developers are unable to install different package versions than the ones authorized in the python-aws repository. When I, as a developer, try to install another version of the boto3 package, I receive an error message. This is expected because the newer version of the boto3 package is not available in the upstream staging repo, and there is block rule that prevents fetching packages or package updates from external upstream repositories.
Similarly, let’s imagine your administrator wants to protect your organization from dependency substitution attacks. All your internal Python package names start with your company name (mycompany). The administrator wants to block developers for accidentally downloading from pypi.org packages that start with mycompany.
Administrator creates a rule with the pattern /pypi//mycompany~ with publish=allow, external upstream=block, and internal upstream=block. With this configuration, internal developers or your CI/CD pipeline can publish those packages, but CodeArtifact will not import any packages from pypi.org that start with mycompany, such as mycompany.foo or mycompany.bar. This prevents dependency substitution attacks for these packages.
Package groups are available in all AWS Regions where CodeArtifact is available, at no additional cost. It helps you to better control how packages and package updates land in your internal repositories. It helps to prevent various supply chain attacks, such as typosquatting or dependency confusion. It’s one additional configuration that you can add today into your infrastructure-as-code (IaC) tools to create and manage your CodeArtifact repositories.
The Chatlytics Amazon Marketing Cloud AI Copilot is your data analysis partner, simplifying the traditionally complex process of authoring AMC SQL.
One of the barriers to getting started with Amazon Marketing Cloud is understanding the data and how to write AMC SQL. The datasets are complex, and AMC SQL has a steep learning curve.
We released a free Amazon Marketing Cloud Copilot called “Chatlytics.” If you are hunting down an SQL error or exploring new ways to create insights, start a conversation about your AMC query or dataset. When you’re stuck, ask the Chatlytics Copilot.
Generate AMC SQL
The Chatlytics Copilot empowers non-technical users with a straightforward approach to understanding AMC’s operation.
Paste SQL into the AMC Query Editor
It’s interactive, iterative, and conversational, making learning enjoyable and relatable. This saves time, reduces frustration, and instills a sense of capability in navigating a complex tool like AMC.
Ask for ideas on how to query DSP Impressions, Clicks, Conversions, Sponsored Ads…
Let it help uncover new strategies to explore insight opportunities.
Trace and troubleshoot errors in AMC SQL. If AMC throws an SQL error, Chatlytics can help you solve it.
Download your AMC Query Results
The Chatlytics service is free. However, to access the Chatlytics AMC Copilot, you must have an OpenAI ChatGPT Plus plan.
Storage, storage, storage! Last week, we celebrated 18 years of innovation on Amazon Simple Storage Service (Amazon S3) at AWS Pi Day 2024. Amazon S3 mascot Buckets joined the celebrations and had a ton of fun! The 4-hour live stream was packed with puns, pie recipes powered by PartyRock, demos, code, and discussions about generative AI and Amazon S3.
AWS Pi Day 2024 — Twitch live stream on March 14, 2024
Up to 40 percent faster stack creation with AWS CloudFormation — AWS CloudFormation now creates stacks up to 40 percent faster and has a new event called CONFIGURATION_COMPLETE. With this event, CloudFormation begins parallel creation of dependent resources within a stack, speeding up the whole process. The new event also gives users more control to shortcut their stack creation process in scenarios where a resource consistency check is unnecessary. To learn more, read this AWS DevOps Blog post.
Amazon SageMaker Canvas extends its model registry integration — SageMaker Canvas has extended its model registry integration to include time series forecasting models and models fine-tuned through SageMaker JumpStart. Users can now register these models to the SageMaker Model Registry with just a click. This enhancement expands the model registry integration to all problem types supported in Canvas, such as regression/classification tabular models and CV/NLP models. It streamlines the deployment of machine learning (ML) models to production environments. Check the Developer Guide for more information.
Amazon S3 Connector for PyTorch — The Amazon S3 Connector for PyTorch now lets PyTorch Lightning users save model checkpoints directly to Amazon S3. Saving PyTorch Lightning model checkpoints is up to 40 percent faster with the Amazon S3 Connector for PyTorch than writing to Amazon Elastic Compute Cloud (Amazon EC2) instance storage. You can now also save, load, and delete checkpoints directly from PyTorch Lightning training jobs to Amazon S3. Check out the open source project on GitHub.
AWS open source news and updates — My colleague Ricardo writes this weekly open source newsletter in which he highlights new open source projects, tools, and demos from the AWS Community.
Upcoming AWS events
Check your calendars and sign up for these AWS events:
AWS at NVIDIA GTC 2024 — The NVIDIA GTC 2024 developer conference is taking place this week (March 18–21) in San Jose, CA. If you’re around, visit AWS at booth #708 to explore generative AI demos and get inspired by AWS, AWS Partners, and customer experts on the latest offerings in generative AI, robotics, and advanced computing at the in-booth theatre. Check out the AWS sessions and request 1:1 meetings.
AWS Summits — It’s AWS Summit season again! The first one is Paris (April 3), followed by Amsterdam (April 9), Sydney (April 10–11), London (April 24), Berlin (May 15–16), and Seoul (May 16–17). AWS Summits are a series of free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS.
AWS re:Inforce — Join us for AWS re:Inforce (June 10–12) in Philadelphia, PA. AWS re:Inforce is a learning conference focused on AWS security solutions, cloud security, compliance, and identity. Connect with the AWS teams that build the security tools and meet AWS customers to learn about their security journeys.
Starting today, you can use InfluxDB as a database engine in Amazon Timestream. This support makes it easy for you to run near real-time time-series applications using InfluxDB and open source APIs, including open source Telegraf agents that collect time-series observations.
Now you have two database engines to choose in Timestream: Timestream for LiveAnalytics and Timestream for InfluxDB.
You should use the Timestream for InfluxDB engine if your use cases require near real-time time-series queries or specific features in InfluxDB, such as using Flux queries. Another option is the existing Timestream for LiveAnalytics engine, which is suitable if you need to ingest more than tens of gigabytes of time-series data per minute and run SQL queries on petabytes of time-series data in seconds.
With InfluxDB support in Timestream, you can use a managed instance that is automatically configured for optimal performance and availability. Furthermore, you can increase resiliency by configuring multi-Availability Zone support for your InfluxDB databases.
Timestream for InfluxDB and Timestream for LiveAnalytics complement each other for low-latency and large-scale ingestion of time-series data.
Getting started with Timestream for InfluxDB
Let me show you how to get started.
First, I create an InfluxDB instance. I navigate to the Timestream console, go to InfluxDB databases in Timestream for InfluxDB and select Create Influx database.
On the next page, I specify the database credentials for the InfluxDB instance.
I also specify my instance class in Instance configuration and the storage type and volume to suit my needs.
In the next part, I can choose a multi-AZ deployment, which synchronously replicates data to a standby database in a different Availability Zone or just a single instance of InfluxDB. In the multi-AZ deployment, if a failure is detected, Timestream for InfluxDB will automatically fail over to the standby instance without data loss.
Then, I configure how to connect to my InfluxDB instance in Connectivity configuration. Here, I have the flexibility to define network type, virtual private cloud (VPC), subnets, and database port. I also have the flexibility to configure my InfluxDB instance to be publicly accessible by specifying public subnets and set the public access to Publicly Accessible, allowing Amazon Timestream will assign a public IP address to my InfluxDB instance. If you choose this option, make sure that you have proper security measures to protect your InfluxDB instances.
In this demo, I set my InfluxDB instance as Not publicly accessible, which also means I can only access it through the VPC and subnets I defined in this section.
Once I configure my database connectivity, I can define the database parameter group and the log delivery settings. In Parameter group, I can define specific configurable parameters that I want to use for my InfluxDB database. In the log delivery settings, I also can define which Amazon Simple Storage Service (Amazon S3) bucket I have to export the system logs. To learn more about the required AWS Identity and Access Management (IAM) policy for the Amazon S3 bucket, visit this page.
Once I’m happy with the configuration, I select Create Influx database.
Once my InfluxDB instance is created, I can see more information on the detail page.
With the InfluxDB instance created, I can also access the InfluxDB user interface (UI). If I configure my InfluxDB as publicly accessible, I can access the UI using the console by selecting InfluxDB UI. As shown on the setup, I configured my InfluxDB instance as not publicly accessible. In this case, I need to access the InfluxDB UI with SSH tunneling through an Amazon Elastic Compute Cloud (Amazon EC2) instance within the same VPC as my InfluxDB instance.
With the URL endpoint from the detail page, I navigate to the InfluxDB UI and use the username and password I configured in the creation process.
With access to the InfluxDB UI, I can now create a token to interact with my InfluxDB instance.
I can also use the Influx command line interface (CLI) to create a token. Before I can create the token, I create a configuration to interact with my InfluxDB instance. The following is the sample command to create a configuration:
influx config create --config-name demo \
--host-url https://<TIMESTREAM for INFLUX DB ENDPOINT> \
--org demo-org
--username-password [USERNAME] \
--active
With the InfluxDB configuration created, I can now create an operator, all-access or read/write token. The following is an example for creating an all-access token to grant permissions to all resources in the organization that I defined:
influx auth create --org demo-org --all-access
With the required token for my use case, I can use various tools, such as the Influx CLI, Telegraf agent, and InfluxDB client libraries, to start ingesting data into my InfluxDB instance. Here, I’m using the Influx CLI to write sample home sensor data in the line protocol format, which you can also get from the InfluxDB documentation page.
Finally, I can query the data using the InfluxDB UI. I navigate to the Data Explorer page in the InfluxDB UI, create a simple Flux script, and select Submit.
Timestream for InfluxDB makes it easier for you to develop applications using InfluxDB, while continuing to use your existing tools to interact with the database. With the multi-AZ configuration, you can increase the availability of your InfluxDB data without worrying about the underlying infrastructure.
AWS and InfluxDB partnership Celebrating this launch, here’s what Paul Dix, Founder and Chief Technology Officer at InfluxData, said about this partnership:
“The future of open source is powered by the public cloud—reaching the broadest community through simple entry points and practical user experience. Amazon Timestream for InfluxDB delivers on that vision. Our partnership with AWS turns InfluxDB open source into a force multiplier for real-time insights on time-series data, making it easier than ever for developers to build and scale their time-series workloads on AWS.”
Things to know
Here are some additional information that you need to know:
Availability – Timestream for InfluxDB is now generally available in the following AWS Regions: US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Mumbai, Singapore, Sydney, Tokyo), and Europe (Frankfurt, Ireland, Stockholm).
Migration scenario – To migrate from a self-managed InfluxDB instance, you can simply restore a backup from an existing InfluxDB database into Timestream for InfluxDB. If you need to migrate from existing Timestream LiveAnalytics engine to Timestream for InfluxDB, you can leverage Amazon S3. Read more on how to do migration for various use cases on Migrating data from self-managed InfluxDB to Timestream for InfluxDB page.
Supported version – Timestream for InfluxDB currently supports the open source 2.7.5 version of InfluxDB
Demo – To see Timestream for InfluxDB in action, have a look at this demo created by my colleague, Derek:
Start building time-series applications and dashboards with millisecond response times using Timestream for InfluxDB. To learn more, visit Amazon Timestream for InfluxDB page.
Because Amazon S3 stores more than 350 trillion objects and exabytes of data for virtually any use case and averages over 100 million requests per second, it may be the starting point of your generative AI journey. But no matter how much data you have or where you have it stored, what counts the most is its quality. Higher quality data improves the accuracy and reliability of model response. In a recent survey of chief data officers (CDOs), almost half (46 percent) of CDOs view data quality as one of their top challenges to implementing generative AI.
This year, with AWS Pi Day, we’ll spend Amazon S3’s birthday looking at how AWS Storage, from data lakes to high performance storage, has transformed data strategy to becom the starting point for your generative AI projects.
This live online event starts at 1 PM PT today (March 14, 2024), right after the conclusion of AWS Innovate: Generative AI + Data edition. It will be live on the AWS OnAir channel on Twitch and will feature 4 hours of fresh educational content from AWS experts. Not only will you learn how to use your data and existing data architecture to build and audit your customized generative AI applications, but you’ll also learn about the latest AWS storage innovations. As usual, the show will be packed with hands-on demos, letting you see how you can get started using these technologies right away.
Data for generative AI Data is growing at an incredible rate, powered by consumer activity, business analytics, IoT sensors, call center records, geospatial data, media content, and other drivers. That data growth is driving a flywheel for generative AI. Foundation models (FMs) are trained on massive datasets, often from sources like Common Crawl, which is an open repository of data that contains petabytes of web page data from the internet. Organizations use smaller private datasets for additional customization of FM responses. These customized models will, in turn, drive more generative AI applications, which create even more data for the data flywheel through customer interactions.
There are three data initiatives you can start today regardless of your industry, use case, or geography.
First, use your existing data to differentiate your AI systems. Most organizations sit on a lot of data. You can use this data to customize and personalize foundation models to suit them to your specific needs. Some personalization techniques require structured data, and some do not. Some others require labeled data or raw data. Amazon Bedrock and Amazon SageMaker offer you multiple solutions to fine-tune or pre-train a wide choice of existing foundation models. You can also choose to deploy Amazon Q, your business expert, for your customers or collaborators and point it to one or more of the 43 data sources it supports out of the box.
But you don’t want to create a new data infrastructure to help you grow your AI usage. Generative AI consumes your organization’s data just like existing applications.
You can also reuse or extend data pipelines that are already in place today. Many of you use AWS streaming technologies such as Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Managed Service for Apache Flink, and Amazon Kinesis to do real-time data preparation in traditional machine learning (ML) and AI. You can extend these workflows to capture changes to your data and make them available to large language models (LLMs) in near real-time by updating the vector databases, make these changes available in the knowledge base with MSK’s native streaming ingestion to Amazon OpenSearch Service, or update your fine-tuning datasets with integrated data streaming in Amazon S3 through Amazon Kinesis Data Firehose.
When talking about LLM training, speed matters. Your data pipeline must be able to feed data to the many nodes in your training cluster. To meet their performance requirements, our customers who have their data lake on Amazon S3 either use an object storage class like Amazon S3 Express One Zone, or a file storage service like Amazon FSx for Lustre. FSx for Lustre provides deep integration and enables you to accelerate object data processing through a familiar, high performance file interface.
The good news is that if your data infrastructure is built using AWS services, you are already most of the way towards extending your data for generative AI.
Third, you must become your own best auditor. Every data organization needs to prepare for the regulations, compliance, and content moderation that will come for generative AI. You should know what datasets are used in training and customization, as well as how the model made decisions. In a rapidly moving space like generative AI, you need to anticipate the future. You should do it now and do it in a way that is fully automated while you scale your AI system.
Your data architecture uses different AWS services for auditing, such as AWS CloudTrail, Amazon DataZone, Amazon CloudWatch, and OpenSearch to govern and monitor data usage. This can be easily extended to your AI systems. If you are using AWS managed services for generative AI, you have the capabilities for data transparency built in. We launched our generative AI capabilities with CloudTrail support because we know how critical it is for enterprise customers to have an audit trail for their AI systems. Any time you create a data source in Amazon Q, it’s logged in CloudTrail. You can also use a CloudTrail event to list the API calls made by Amazon CodeWhisperer. Amazon Bedrock has over 80 CloudTrail events that you can use to audit how you use foundation models.
New capabilities just launched Pi Day is also the occasion to celebrate innovation in AWS storage and data services. Here is a selection of the new capabilities that we’ve just announced:
The Amazon S3 Connector for PyTorch now supports saving PyTorch Lightning model checkpoints directly to Amazon S3. Model checkpointing typically requires pausing training jobs, so the time needed to save a checkpoint directly impacts end-to-end model training times. PyTorch Lightning is an open source framework that provides a high-level interface for training and checkpointing with PyTorch. Read the What’s New post for more details about this new integration.
What to expect during the live stream We will address some of these new capabilities during the 4-hour live show today. My colleague Darko will host a number of AWS experts for hands-on demonstrations so you can discover how to put your data to work for your generative AI projects. Here is the schedule of the day. All times are expressed in Pacific Time (PT) time zone (GMT-8):
Extend your existing data architecture to generative AI (1 PM – 2 PM).
If you run analytics on top of AWS data lakes, you’re most of your way there to your data strategy for generative AI.
Accelerate the data path to compute for generative AI (2 PM – 3 PM).
Speed matters for compute data path for model training and inference. Check out the different ways we make it happen.
Customize with RAG and fine-tuning (3 PM – 4 PM).
Discover the latest techniques to customize base foundation models.
Be your own best auditor for GenAI (4 PM – 5 PM).
Use existing AWS services to help meet your compliance objectives.
Last week, Anthropic announced their Claude 3 foundation model family. The family includes three models: Claude 3 Haiku, the fastest and most compact model for near-instant responsiveness; Claude 3 Sonnet, the ideal balanced model between skills and speed; and Claude 3 Opus, the most intelligent offering for top-level performance on highly complex tasks. AWS also announced the general availability of Claude 3 Sonnet in Amazon Bedrock.
Today, we are announcing the availability of Claude 3 Haiku on Amazon Bedrock. The Claude 3 Haiku foundation model is the fastest and most compact model of the Claude 3 family, designed for near-instant responsiveness and seamless generative artificial intelligence (AI) experiences that mimic human interactions. For example, it can read a data-dense research paper on arXiv (~10k tokens) with charts and graphs in less than three seconds.
With Claude 3 Haiku’s availability on Amazon Bedrock, you can build near-instant responsive generative AI applications for enterprises that need quick and accurate targeted performance. Like Sonnet and Opus, Haiku has image-to-text vision capabilities, can understand multiple languages besides English, and boasts increased steerability in a 200k context window.
Claude 3 Haiku use cases
Claude 3 Haiku is smarter, faster, and more affordable than other models in its intelligence category. It answers simple queries and requests with unmatched speed. With its fast speed and increased steerability, you can create AI experiences that seamlessly imitate human interactions.
Here are some use cases for using Claude 3 Haiku:
Customer interactions: quick and accurate support in live interactions, translations
Content moderation: catch risky behavior or customer requests
Cost-saving tasks: optimized logistics, inventory management, fast knowledge extraction from unstructured data
Claude 3 Haiku in action
If you are new to using Anthropic models, go to the Amazon Bedrock console and choose Model access on the bottom left pane. Request access separately for Claude 3 Haiku.
To test Claude 3 Haiku in the console, choose Text or Chat under Playgrounds in the left menu pane. Then choose Select model and select Anthropic as the category and Claude 3 Haiku as the model.
To test more Claude prompt examples, choose Load examples. You can view and run examples specific to Claude 3 Haiku, such as advanced Q&A with citations, crafting a design brief, and non-English content generation.
Using Compare mode, you can also compare the speed and intelligence between Claude 3 Haiku and the Claude 2.1 model using a sample prompt to generate personalized email responses to address customer questions.
By choosing View API request, you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDKs. Here is a sample of the AWS CLI command:
aws bedrock-runtime invoke-model \
--model-id anthropic.claude-3-haiku-20240307-v1:0 \
--body "{\"messages\":[{\"role\":\"user\",\"content\":[{\"type\":\"text\",\"text\":\"Write the test case for uploading the image to Amazon S3 bucket\\nCertainly! Here's an example of a test case for uploading an image to an Amazon S3 bucket using a testing framework like JUnit or TestNG for Java:\\n\\n...."}]}],\"anthropic_version\":\"bedrock-2023-05-31\",\"max_tokens\":2000}" \
--cli-binary-format raw-in-base64-out \
--region us-east-1 \
invoke-model-output.txt
Now available
Claude 3 Haiku is available now in the US West (Oregon) Region with more Regions coming soon; check the full Region list for future updates.
Claude 3 Haiku is the most cost-effective choice. For example, Claude 3 Haiku is cheaper, up to 68 percent of the price per 1,000 input/output tokens compared to Claude Instant, with higher levels of intelligence. To learn more, see Amazon Bedrock Pricing.







































 Here are some use cases for using Claude 3 Haiku:
Here are some use cases for using Claude 3 Haiku:

