Thursday, June 27, 2024

Amazon WorkSpaces Pools: Cost-effective, non-persistent virtual desktops
You can now create a pool of non-persistent virtual desktops using Amazon WorkSpaces and share them across a group of users. As the desktop administrator you can manage your entire portfolio of persistent and non-persistent virtual desktops using one GUI, command line, or set of API-powered tools. Your users can log in to these desktops using a browser, a client application (Windows, Mac, or Linux), or a thin client device.
Amazon WorkSpaces Pools (non-persistent desktops)
WorkSpaces Pools ensures that each user gets the same applications and the same experience. When the user logs in, they always get access to a fresh WorkSpace that’s based on the latest configuration for the pool, centrally managed by their administrator. If the administrator enables application settings persistence for the pool, users can configure certain application settings, such as browser favorites, plugins, and UI customizations. Users can also access persistent file or object storage external to the desktop.
These desktops are a great fit for many types of users and use cases including remote workers, task workers (shared service centers, finance, procurement, HR, and so forth), contact center workers, and students.
As the administrator for the pool, you have full control over the compute resources (bundle type) and the initial configuration of the desktops in the pool, including the set of applications that are available to the users. You can use an existing custom WorkSpaces image, create a new one, or use one of the standard ones. You can also include Microsoft 365 Apps for Enterprise on the image. You can configure the pool to accommodate the size and working hours of your user base, and you can optionally join the pool to your organization’s domain and active directory.
Getting started
Let’s walk through the process of setting up a pool and inviting some users. I open the WorkSpaces console and choose Pools to get started:
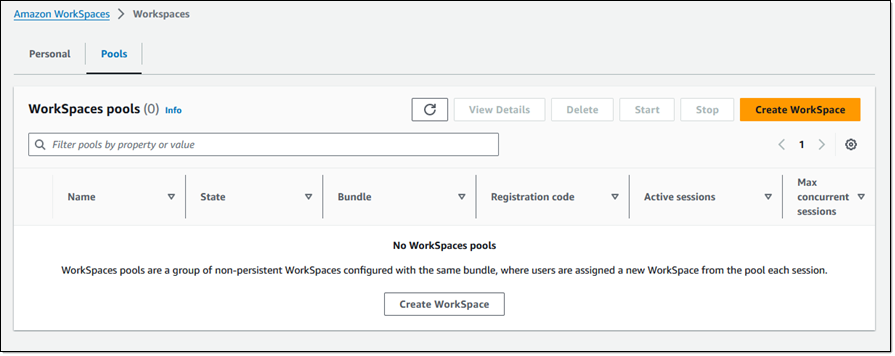
I have no pools, so I choose Create WorkSpace on the Pools tab to begin the process of creating a pool:
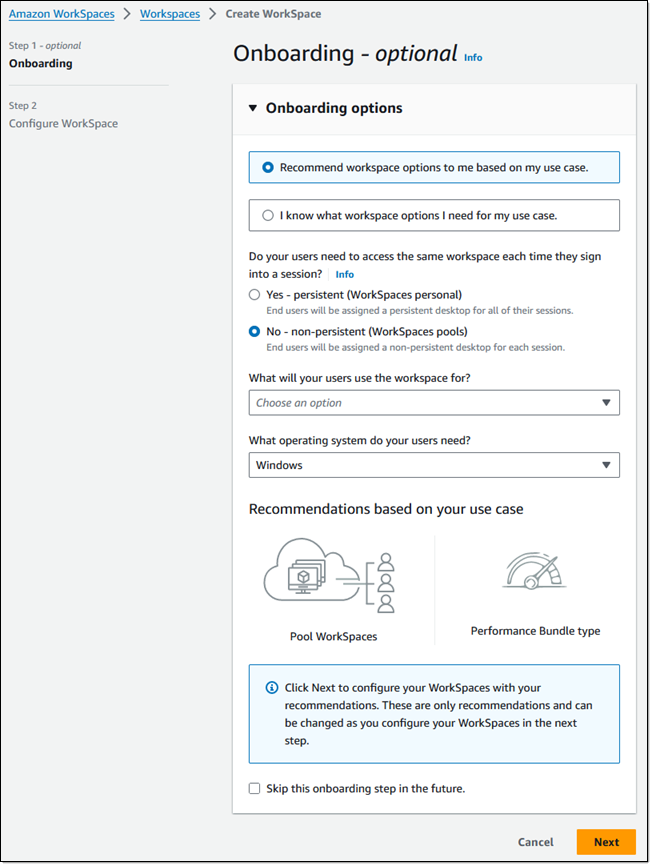
The console can recommend workspace options for me, or I can choose what I want. I leave Recommend workspace options… selected, and choose No – non-persistent to create a pool of non-persistent desktops. Then I select my use cases from the menu and pick the operating system and choose Next to proceed:
The use case menu has lots of options:
On the next page I start by reviewing the WorkSpace options and assigning a name to my pool:
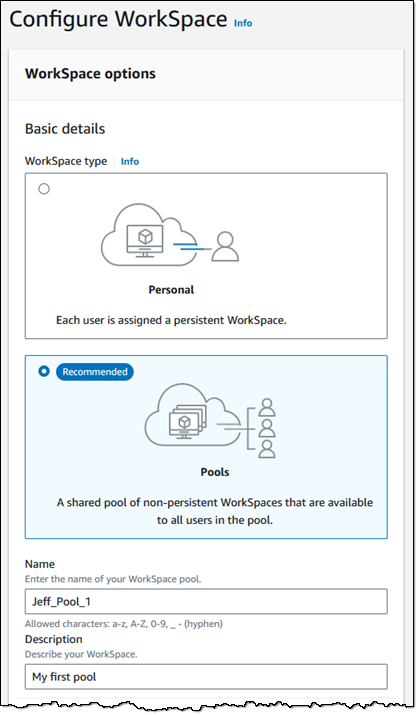
Next, I scroll down and choose a bundle. I can pick a public bundle or a custom one of my own. Bundles must use the WSP 2.0 protocol. I can create a custom bundle to provide my users with access to applications or to alter any desired system settings.
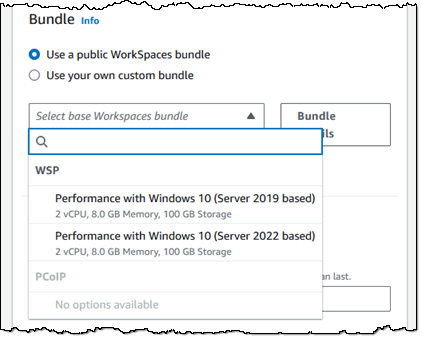
Moving right along, I can customize the settings for each user session. I can also enable application settings persistence to save application customizations and Windows settings on a per-user basis between sessions:
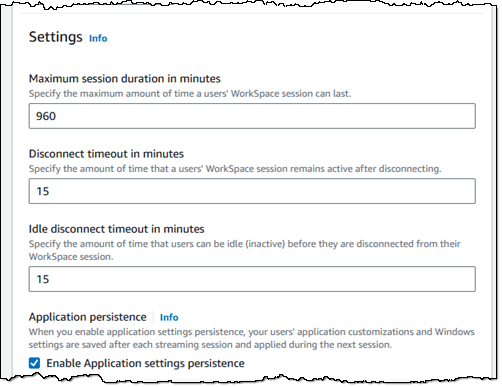
Next, I set the capacity of my pool, and optionally establish one or more schedules based on date or time. The schedules give me the power to match the size of my pool (and hence my costs) to the rhythms and needs of my users:
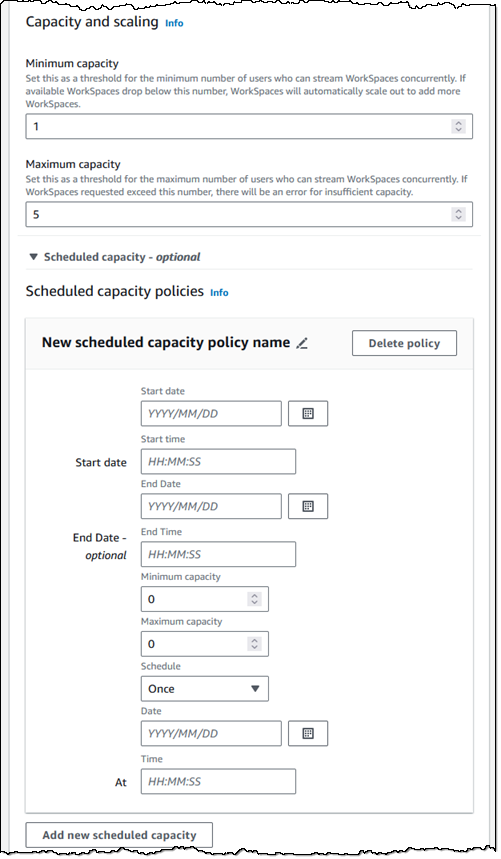
If the amount of concurrent usage is more dynamic and not aligned to a schedule, then I can use manual scale out and scale in policies to control the size of my pool:
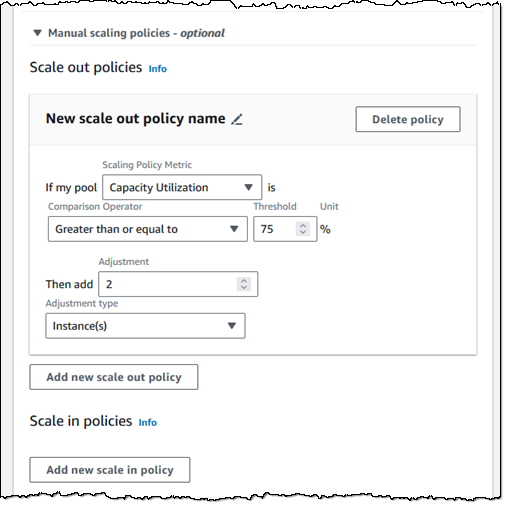
I tag my pool, and then choose Next to proceed:
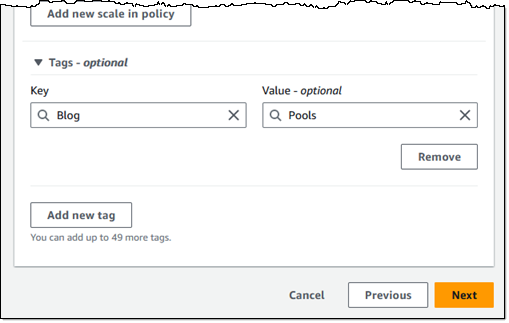
The final step is to select a WorkSpaces pool directory or create a new one following these steps. Then, I choose Create WorkSpace pool.

After the pool has been created and started, I can send registration codes to users, and they can log in to a WorkSpace:

I can monitor the status of the pool from the console:

Things to know
Here are a couple of things that you should know about WorkSpaces Pools:
Programmatic access – You can automate the setup process that I showed above by using functions like CreateWorkSpacePool, DescribeWorkSpacePool, UpdateWorkSpacePool, or the equivalent AWS command line interface (CLI) commands.
Regions – WorkSpaces Pools is available in all commercial AWS Regions where WorkSpaces Personal is available, except Israel (Tel Aviv), Africa (Cape Town), and China (Ningxia). Check the full Region list for future updates.
Pricing – Refer to the Amazon WorkSpaces Pricing page for complete pricing information.
Visit Amazon WorkSpaces Pools to learn more.
— Jeff;
from AWS News Blog https://ift.tt/SwvmBqT
via IFTTT
Introducing end-to-end data lineage (preview) visualization in Amazon DataZone
Amazon DataZone is a data management service to catalog, discover, analyze, share, and govern data between data producers and consumers in your organization. Engineers, data scientists, product managers, analysts, and business users can easily access data throughout your organization using a unified data portal so that they can discover, use, and collaborate to derive data-driven insights.
Now, I am excited to announce in preview a new API-driven and OpenLineage compatible data lineage capability in Amazon DataZone, which provides an end-to-end view of data movement over time. Data lineage is a new feature within Amazon DataZone that helps users visualize and understand data provenance, trace change management, conduct root cause analysis when a data error is reported, and be prepared for questions on data movement from source to target. This feature provides a comprehensive view of lineage events, captured automatically from Amazon DataZone’s catalog along with other events captured programmatically outside of Amazon DataZone by stitching them together for an asset.
When you need to validate how the data of interest originated in the organization, you may rely on manual documentation or human connections. This manual process is time-consuming and can result in inconsistency, which directly reduces your trust in the data. Data lineage in Amazon DataZone can raise trust by helping you understand where the data originated, how it has changed, and its consumption in time. For example, data lineage can be programmatically setup to show the data from the time it was captured as raw files in Amazon Simple Storage Service (Amazon S3), through its ETL transformations using AWS Glue, to the time it was consumed in tools such as Amazon QuickSight.
With Amazon DataZone’s data lineage, you can reduce the time spent mapping a data asset and its relationships, troubleshooting and developing pipelines, and asserting data governance practices. Data lineage helps you gather all lineage information in one place using API, and then provide a graphical view with which data users can be more productive, make better data-driven decisions, and also identify the root cause of data issues.
Let me tell you how to get started with data lineage in Amazon DataZone. Then, I will show you how data lineage enhances the Amazon DataZone data catalog experience by visually displaying connections about how a data asset came to be so you can make informed decisions when searching or using the data asset.
Getting started with data lineage in Amazon DataZone
In preview, I can get started by hydrating lineage information into Amazon DataZone programmatically by either directly creating lineage nodes using Amazon DataZone APIs or by sending OpenLineage compatible events from existing pipeline components to capture data movement or transformations that happens outside of Amazon DataZone. For information about assets in the catalog, Amazon DataZone automatically captures lineage of its states (i.e., inventory or published states), and its subscriptions for producers, such as data engineers, to trace who is consuming the data they produced or for data consumers, such as data analyst or data engineers, to understand if they are using the right data for their analysis.
With the information being sent, Amazon DataZone will start populating the lineage model and will be able to map the identifier sent through the APIs with the assets already cataloged. As new lineage information is being sent, the model starts creating versions to start the visualization of the asset at a given time, but it also allows me to navigate to previous versions.
I use a preconfigured Amazon DataZone domain for this use case. I use Amazon DataZone domains to organize my data assets, users, and projects. I go to the Amazon DataZone console and choose View domains. I choose my domain Sales_Domain and choose Open data portal.

I have five projects under my domain: one for a data producer (SalesProject) and four for data consumers (MarketingTestProject, AdCampaignProject, SocialCampaignProject, and WebCampaignProject). You can visit Amazon DataZone Now Generally Available – Collaborate on Data Projects across Organizational Boundaries to create your own domain and all the core components.

I enter “Market Sales Table” in the Search Assets bar and then go to the detail page for the Market Sales Table asset. I choose the LINEAGE tab to visualize lineage with upstream and downstream nodes.

I can now dive into asset details, processes, or jobs that lead to or from those assets and drill into column-level lineage.
Interactive visualization with data lineage
I will show you the graphical interface using various personas who regularly interact with Amazon DataZone and will benefit from the data lineage feature.
First, let’s say I am a marketing analyst, who needs to confirm the origin of a data asset to confidently use in my analysis. I go to the MarketingTestProject page and choose the LINEAGE tab. I notice the lineage includes information about the asset as it occurs inside and out of Amazon DataZone. The labels Cataloged, Published, and Access requested represent actions inside the catalog. I expand the market_sales dataset item to see where the data came from.

I now feel assured of the origin of the data asset and trust that it aligns with my business purpose ahead of starting my analysis.
Second, let’s say I am a data engineer. I need to understand the impact of my work on dependent objects to avoid unintended changes. As a data engineer, any changes made to the system should not break any downstream processes. By browsing lineage, I can clearly see who has subscribed and has access to the asset. With this information, I can inform the project teams about an impending change that can affect their pipeline. When a data issue is reported, I can investigate each node and traverse between its versions to dive into what has changed over time to identify the root cause of the issue and fix it in a timely manner.

Finally, as an administrator or steward, I am responsible for securing data, standardizing business taxonomies, enacting data management processes, and for general catalog management. I need to collect details about the source of data and understand the transformations that have happened along the way.
For example, as an administrator looking to respond to questions from an auditor, I traverse the graph upstream to see where the data is coming from and notice that the data is from two different sources: online sale and in-store sale. These sources have their own pipelines until the flow reaches a point where the pipelines merge.

While navigating through the lineage graph, I can expand the columns to ensure sensitive columns are dropped during the transformation processes and respond to the auditors with details in a timely manner.

Join the preview
Data lineage capability is available in preview in all Regions where Amazon DataZone is generally available. For a list of Regions where Amazon DataZone domains can be provisioned, visit AWS Services by Region.
Data lineage costs are dependent on storage usage and API requests, which are already included in Amazon DataZone’s pricing model. For more details, visit Amazon DataZone pricing.
To learn more about data lineage in Amazon DataZone, visit the Amazon DataZone User Guide.
— Esrafrom AWS News Blog https://ift.tt/GrqsxK7
via IFTTT
Amazon CodeCatalyst now supports GitLab and Bitbucket repositories, with blueprints and Amazon Q feature development
I’m happy to announce that we’re further integrating Amazon CodeCatalyst with two popular code repositories: GitLab and BitBucket, in addition to the existing integration with GitHub. We bring the same set of capabilities that you use today on CodeCatalyst with GitHub to GitLab.com and Bitbucket Cloud.
Amazon CodeCatalyst is a unified software development and delivery service. It enables software development teams to quickly and easily plan, develop, collaborate on, build, and deliver applications on Amazon Web Services (AWS), reducing friction throughout the development lifecycle.
The GitHub, GitLab.com, and Bitbucket Cloud repositories extension for CodeCatalyst simplifies managing your development workflow. The extension allows you to view and manage external repositories directly within CodeCatalyst. Additionally, you can store and manage workflow definition files alongside your code in external repositories while also creating, reading, updating, and deleting files in linked repositories from CodeCatalyst dev environments. The extension also triggers CodeCatalyst workflow runs automatically upon code pushes and when pull requests are opened, merged, or closed. Furthermore, it allows you to directly utilize source files from linked repositories and execute actions within CodeCatalyst workflows, eliminating the need to switch platforms and maximizing efficiency.
But there’s more: starting today, you can create a CodeCatalyst project in a GitHub, GitLab.com, or Bitbucket Cloud repository from a blueprint, you can add a blueprint to an existing code base in a repository on any of those three systems, and you can also create custom blueprints stored in your external repositories hosted on GitHub, GitLab.com, or Bitbucket Cloud.
CodeCatalyst blueprints help to speed up your developments. These pre-built templates provide a source repository, sample code, continuous integration and delivery (CI/CD) workflows, and integrated issue tracking to get you started quickly. Blueprints automatically update with best practices, keeping your code modern. IT leaders can create custom blueprints to standardize development for your team, specifying technology, access controls, deployment, and testing methods. And now, you can use blueprints even if your code resides in GitHub, GitLab.com, or Bitbucket Cloud.
Link your CodeCatalyst space with a git repository hosting service
Getting started using any of these three source code repository providers is easy. As a CodeCatalyst space administrator, I select the space where I want to configure the extensions. Then, I select Settings, and in the Installed extensions section, I select Configure to link my CodeCatalyst space with my GitHub, GitLab.com, or Bitbucket Cloud account.

This is a one-time operation for each CodeCatalyst space, but you might want to connect your space to multiple source providers’ accounts.
When using GitHub, I also have to link my personal CodeCatalyst user to my GitHub user. Under my personal menu on the top right side of the screen, I select My settings. Then, I navigate down to the Personal connections section. I select Create and follow the instructions to authenticate on GitHub and link my two identities.

This is a one-time operation for each user in the CodeCatalyst space. This is only required when you’re using GitHub with blueprints.
Create a project from a blueprint and host it on GitHub, GitLab.com, and Bitbucket Cloud
Let’s show you how to create a project in an external repository from a blueprint and later add other blueprints to this project. You can use any of the three git hosting providers supported by CodeCatalyst. In this demo, I chose to use GitHub.
Let’s imagine I want to create a new project to implement an API. I start from a blueprint that implements an API with Python and the AWS Serverless Application Model (AWS SAM). The blueprint also creates a CI workflow and an issue management system. I want my project code to be hosted on GitHub. It allows me to directly use source files from my repository in GitHub and execute actions within CodeCatalyst workflows, eliminating the need to switch platforms.
I start by selecting Create project on my CodeCatalyst space page. I select Start with a blueprint and select the CodeCatalyst blueprint or Space blueprint I want to use. Then, I select Next.

I enter a name for my project. I open the Advanced section, and I select GitHub as Repository provider and my GitHub account. You can configure additional connections to GitHub by selecting Connect a GitHub account.

The rest of the configuration depends on the selected blueprint. In this case, I chose the language version, the AWS account to deploy the project to, the name of the AWS Lambda function, and the name of the AWS CloudFormation stack.
After the project is created, I navigate to my GitHub account, and I can see that a new repository has been created. It contains the code and resources from the blueprint.

Add a blueprint to an existing GitHub, GitLab.com, or Bitbucket Cloud project
You can apply multiple blueprints in a project to incorporate functional components, resources, and governance to existing CodeCatalyst projects. Your projects can support various elements that are managed independently in separate blueprints. The service documentation helps you learn more about lifecycle management with blueprints on existing projects.
I can now add a blueprint to an existing project in an external source code repository. Now that my backend API project has been created, I want to add a web application to my project.
I navigate to the Blueprints section in the left-side menu, and I select the orange Add blueprint button on the top-right part of the screen.

I select the Single-page application blueprint and select Next.

On the next screen, I make sure to select my GitHub connection, as I did when I created the project. I also fill in the required information for this specific template. On the right side of the screen, I review the proposed changes.

Similarly, when using CodeCatalyst Enterprise Tier, I can create my own custom blueprints to share with my teammates or other groups within my organization. For brevity, I don’t share step-by-step instructions to do so in this post. For more information, see Standardizing projects with custom blueprints in the documentation.
When CodeCatalyst finishes installing the new blueprint, I can see a second repository on GitHub.

Single or multiple repository strategies
When organizing code, you can choose between a single large repository, like a toolbox overflowing with everything, or splitting it into smaller, specialized ones for better organization. Single repositories simplify dependency management for tightly linked projects but can become messy at scale. Multiple repositories offer cleaner organization and improved security but require planning to manage dependencies between separate projects.
CodeCatalyst lets you use the best strategy for your project. For more information, see the section Store and collaborate on code with source repositories in CodeCatalyst in the documentation.
In the example I showed before, the blueprint I selected proposed to apply the second blueprint as a separate repository in GitHub. Depending on the blueprint you selected, the blueprint may propose that you create a separate repository or merge the new code in an existing repository. In the latter case, the blueprint will submit a pull request for you to merge into your repository.
Region and availability
This new GitHub integration is available at no additional cost in the two AWS Regions where Amazon CodeCatalyst is available, US West (Oregon) and Europe (Ireland) at the time of publication.
from AWS News Blog https://ift.tt/QJKsq4c
via IFTTT
Wednesday, June 26, 2024
Optimizing Amazon Simple Queue Service (SQS) for speed and scale
 After several public betas, we launched Amazon Simple Queue Service (Amazon SQS) in 2006. Nearly two decades later, this fully managed service is still a fundamental building block for microservices, distributed systems, and serverless applications, processing over 100 million messages per second at peak times.
After several public betas, we launched Amazon Simple Queue Service (Amazon SQS) in 2006. Nearly two decades later, this fully managed service is still a fundamental building block for microservices, distributed systems, and serverless applications, processing over 100 million messages per second at peak times.
Because there’s always a better way, we continue to look for ways to improve performance, security, internal efficiency, and so forth. When we do find a potential way to do something better, we are careful to preserve existing behavior, and often run new and old systems in parallel to allow us to compare results.
Today I would like to tell you how we recently made improvements to Amazon SQS to reduce latency, increase fleet capacity, mitigate an approaching scalability cliff, and reduce power consumption.
Improving SQS
Like many AWS services, Amazon SQS is implemented using a collection of internal microservices. Let’s focus on two of them today:
Customer Front-End – The customer-facing front-end accepts, authenticates, and authorizes API calls such as CreateQueue and SendMessage. It then routes each request to the storage back-end.
Storage Back-End -This internal microservice is responsible for persisting messages sent to standard (non-FIFO) queues. Using a cell-based model, each cluster in the cell contains multiple hosts, each customer queue is assigned to one or more clusters, and each cluster is responsible for a multitude of queues:

Connections – Old and New
The original implementation used a connection per request between these two services. Each front-end had to connect to many hosts, which mandated the use of a connection pool, and also risked reaching an ultimate, hard-wired limit on the number of open connections. While it is often possible to simply throw hardware at problems like this and scale out, that’s not always the best way. It simply moves the moment of truth (the “scalability cliff”) into the future and does not make efficient use of resources.
After carefully considering several long-term solutions, the Amazon SQS team invented a new, proprietary binary framing protocol between the customer front-end and storage back-end. The protocol multiplexes multiple requests and responses across a single connection, using 128-bit IDs and checksumming to prevent crosstalk. Server-side encryption provides an additional layer of protection against unauthorized access to queue data.
It Works!
The new protocol was put into production earlier this year and has processed 744.9 trillion requests as I write this. The scalability cliff has been eliminated and we are already looking for ways to put this new protocol to work in other ways.
Performance-wise, the new protocol has reduced dataplane latency by 11% on average, and by 17.4% at the P90 mark. In addition to making SQS itself more performant, this change benefits services that build on SQS as well. For example, messages sent through Amazon Simple Notification Service (Amazon SNS) now spend 10% less time “inside” before being delivered. Finally, due to the protocol change, the existing fleet of SQS hosts (a mix of X86 and Graviton-powered instances) can now handle 17.8% more requests than before.
More to Come
I hope that you have enjoyed this little peek inside the implementation of Amazon SQS. Let me know in the comments, and I will see if I can find some more stories to share.
— Jeff;
from AWS News Blog https://ift.tt/CwkbPBd
via IFTTT
Monday, June 24, 2024
AWS Weekly Roundup: Claude 3.5 Sonnet in Amazon Bedrock, CodeCatalyst updates, SageMaker with MLflow, and more (June 24, 2024)
This week, I had the opportunity to try the new Anthropic Claude 3.5 Sonnet model in Amazon Bedrock just before it launched, and I was really impressed by its speed and accuracy! It was also the week of AWS Summit Japan; here’s a nice picture of the busy AWS Community stage.

Last week’s launches
With many new capabilities, from recommendations on the size of your Amazon Relational Database Services (Amazon RDS) databases to new built-in transformations in AWS Glue, here’s what got my attention:
Amazon Bedrock – Now supports Anthropic’s Claude 3.5 Sonnet and compressed embeddings from Cohere Embed.
AWS CodeArtifact – With support for Rust packages with Cargo, developers can now store and access their Rust libraries (known as crates).
Amazon CodeCatalyst – Many updates from this unified software development service. You can now assign issues in CodeCatalyst to Amazon Q and direct it to work with source code hosted in GitHub Cloud and Bitbucket Cloud and ask Amazon Q to analyze issues and recommend granular tasks. These tasks can then be individually assigned to users or to Amazon Q itself. You can now also use Amazon Q to help pick the best blueprint for your needs. You can now securely store, publish, and share Maven, Python, and NuGet packages. You can also link an issue to other issues. This allows customers to link issues in CodeCatalyst as blocked by, duplicate of, related to, or blocks another issue. You can now configure a single CodeBuild webhook at organization or enterprise level to receive events from all repositories in your organizations, instead of creating webhooks for each individual repository. Finally, you can now add a default IAM role to an environment.
Amazon EC2 – C7g and R7g instances (powered by AWS Graviton3 processors) are now available in Europe (Milan), Asia Pacific (Hong Kong), and South America (São Paulo) Regions. C7i-flex instances are now available in US East (Ohio) Region.
AWS Compute Optimizer – Now provides rightsizing recommendations for Amazon RDS MySQL, and RDS PostgreSQL. More info in this Cloud Financial Management blog post.
Amazon OpenSearch Service – With JSON Web Token (JWT) authentication and authorization, it’s now easier to integrate identity providers and isolate tenants in a multi-tenant application.
Amazon SageMaker – Now helps you manage machine learning (ML) experiments and the entire ML lifecycle with a fully managed MLflow capability.
AWS Glue – The serverless data integration service now offers 13 new built-in transforms: flag duplicates in column, format Phone Number, format case, fill with mode, flag duplicate rows, remove duplicates, month name, iIs even, cryptographic hash, decrypt, encrypt, int to IP, and IP to int.
Amazon MWAA – Amazon Managed Workflows for Apache Airflow (MWAA) now supports custom domain names for the Airflow web server, allowing to use private web servers with load balancers, custom DNS entries, or proxies to point users to a user-friendly web address.
For a full list of AWS announcements, be sure to keep an eye on the What's New at AWS page.Other AWS news
Here are some additional projects, blog posts, and news items that you might find interesting:
AWS re:Inforce 2024 re:Cap – A summary of our annual, immersive, cloud-security learning event by my colleague Wojtek.
Three ways Amazon Q Developer agent for code transformation accelerates Java upgrades – This post offers interesting details on how Amazon Q Developer handles major version upgrades of popular frameworks, replacing deprecated API calls on your behalf, and explainability on code changes.
Five ways Amazon Q simplifies AWS CloudFormation development – For template code generation, querying CloudFormation resource requirements, explaining existing template code, understanding deployment options and issues, and querying CloudFormation documentation.
Improving air quality with generative AI – A nice solution that uses artificial intelligence (AI) to standardize air quality data, addressing the air quality data integration problem of low-cost sensors.
Deploy a Slack gateway for Amazon Bedrock – A solution bringing the power of generative AI directly into your Slack workspace.
An agent-based simulation of Amazon’s inbound supply chain – Simulating the entire US inbound supply chain, including the “first-mile” of distribution and tracking the movement of hundreds of millions of individual products through the network.
AWS CloudFormation Linter (cfn-lint) v1 – This upgrade is particularly significant because it converts from using the CloudFormation spec to using CloudFormation registry resource provider schemas.
A practical approach to using generative AI in the SDLC – Learn how an AI assistant like Amazon Q Developer helps my colleague Jenna figure out what to build and how to build it.
AWS open source news and updates – My colleague Ricardo writes about open source projects, tools, and events from the AWS Community. Check out Ricardo’s page for the latest updates.
Upcoming AWS events
Check your calendars and sign up for upcoming AWS events:
AWS Summits – Join free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. This week, you can join the AWS Summit in Washington, DC, June 26–27. Learn here about future AWS Summit events happening in your area.
AWS Community Days – Join community-led conferences that feature technical discussions, workshops, and hands-on labs led by expert AWS users and industry leaders from around the world. This week there are AWS Community Days in Switzerland (June 27), Sri Lanka (June 27), and the Gen AI Edition in Ahmedabad, India (June 29).
Browse all upcoming AWS led in-person and virtual events and developer-focused events.
That’s all for this week. Check back next Monday for another Weekly Roundup!
— Danilo
This post is part of our Weekly Roundup series. Check back each week for a quick roundup of interesting news and announcements from AWS!
from AWS News Blog https://ift.tt/Zszx3Cf
via IFTTT
Thursday, June 20, 2024
AWS CodeArtifact adds support for Rust packages with Cargo
Starting today, Rust developers can store and access their libraries (known as crates in Rust’s world) on AWS CodeArtifact.
Modern software development relies heavily on pre-written code packages to accelerate development. These packages, which can number in the hundreds for a single application, tackle common programming tasks and can be created internally or obtained from external sources. While these packages significantly help to speed up development, their use introduces two main challenges for organizations: legal and security concerns.
On the legal side, organizations need to ensure they have compatible licenses for these third-party packages and that they don’t infringe on intellectual property rights. Security is another risk, as vulnerabilities in these packages could be exploited to compromise an application. A known tactic, the supply chain attack, involves injecting vulnerabilities into popular open source projects.
To address these challenges, organizations can set up private package repositories. These repositories store pre-approved packages vetted by security and legal teams, limiting the risk of legal or security exposure. This is where CodeArtifact enters.
AWS CodeArtifact is a fully managed artifact repository service designed to securely store, publish, and share software packages used in application development. It supports popular package managers and formats such as npm, PyPI, Maven, NuGet, SwiftPM, and Rubygem, enabling easy integration into existing development workflows. It helps enhance security through controlled access and facilitates collaboration across teams. CodeArtifact helps maintain a consistent, secure, and efficient software development lifecycle by integrating with AWS Identity and Access Management (IAM) and continuous integration and continuous deployment (CI/CD) tools.
For the eighth year in a row, Rust has topped the chart as “the most desired programming language” in Stack Overflow’s annual developer survey, with more than 80 percent of developers reporting that they’d like to use the language again next year. Rust’s growing popularity stems from its ability to combine the performance and memory safety of systems languages such as C++ with features that makes writing reliable, concurrent code easier. This, along with a rich ecosystem and a strong focus on community collaboration, makes Rust an attractive option for developers working on high-performance systems and applications.
Rust developers rely on Cargo, the official package manager, to manage package dependencies. Cargo simplifies the process of finding, downloading, and integrating pre-written crates (libraries) into their projects. This not only saves time by eliminating manual dependency management, but also ensures compatibility and security. Cargo’s robust dependency resolution system tackles potential conflicts between different crate versions, and because many crates come from a curated registry, developers can be more confident about the code’s quality and safety. This focus on efficiency and reliability makes Cargo an essential tool for building Rust applications.
Let’s create a CodeArtifact repository for my crates
In this demo, I use the AWS Command Line Interface (AWS CLI) and AWS Management Console to create two repositories. I configure the first repository to download public packages from the official crates.io repository. I configure the second repository to download packages from the first one only. This dual repository configuration is the recommended way to manage repositories and external connections, see the CodeArtifact documentation for managing external connections. To quote the documentation:
“It is recommended to have one repository per domain with an external connection to a given public repository. To connect other repositories to the public repository, add the repository with the external connection as an upstream to them.”
I sketched this diagram to illustrate the setup.

Domains and repositories can be created either from the command line or the console. I choose the command line. In shell terminal, I type:
CODEARTIFACT_DOMAIN=stormacq-test
# Create an internal-facing repository: crates-io-store
aws codeartifact create-repository \
--domain $CODEARTIFACT_DOMAIN \
--repository crates-io-store
# Associate the internal-facing repository crates-io-store to the public crates-io
aws codeartifact associate-external-connection \
--domain $CODEARTIFACT_DOMAIN \
--repository crates-io-store \
--external-connection public:crates-io
# Create a second internal-facing repository: cargo-repo
# and connect it to upstream crates-io-store just created
aws codeartifact create-repository \
--domain $CODEARTIFACT_DOMAIN \
--repository cargo-repo \
--upstreams '{"repositoryName":"crates-io-store"}' Next, as a developer, I want my local machine to fetch crates from the internal repository (cargo-repo) I just created.
I configure cargo to fetch libraries from the internal repository instead of the public crates.io. To do so, I create a config.toml file to point to CodeArtifact internal repository.
# First, I retrieve the URI of the repo
REPO_ENDPOINT=$(aws codeartifact get-repository-endpoint \
--domain $CODEARTIFACT_DOMAIN \
--repository cargo-repo \
--format cargo \
--output text)
# at this stage, REPO_ENDPOINT is https://stormacq-test-012345678912.d.codeartifact.us-west-2.amazonaws.com/cargo/cargo-repo/
# Next, I create the cargo config file
cat << EOF > ~/.cargo/config.toml
[registries.cargo-repo]
index = "sparse+$REPO_ENDPOINT"
credential-provider = "cargo:token-from-stdout aws codeartifact get-authorization-token --domain $CODEARTIFACT_DOMAIN --query authorizationToken --output text"
[registry]
default = "cargo-repo"
[source.crates-io]
replace-with = "cargo-repo"
EOF
Note that the two environment variables are replaced when I create the config file. cargo doesn’t support environment variables in its configuration.
From now on, on this machine, every time I invoke cargo to add a crate, cargo will obtain an authorization token from CodeArtifact to communicate with the internal cargo-repo repository. I must have IAM privileges to call the get-authorization-token CodeArtifact API in addition to permissions for read/publish package according to the command I use. If you’re running this setup from a build machine for your continuous integration (CI) pipeline, your build machine must have proper permissions to do so.
I can now test this setup and add a crate to my local project.
$ cargo add regex
Updating `codeartifact` index
Adding regex v1.10.4 to dependencies
Features:
+ perf
+ perf-backtrack
+ perf-cache
+ perf-dfa
+ perf-inline
+ perf-literal
+ perf-onepass
+ std
+ unicode
+ unicode-age
+ unicode-bool
+ unicode-case
+ unicode-gencat
+ unicode-perl
+ unicode-script
+ unicode-segment
- logging
- pattern
- perf-dfa-full
- unstable
- use_std
Updating `cargo-repo` index
# Build the project to trigger the download of the crate
$ cargo build
Downloaded memchr v2.7.2 (registry `cargo-repo`)
Downloaded regex-syntax v0.8.3 (registry `cargo-repo`)
Downloaded regex v1.10.4 (registry `cargo-repo`)
Downloaded aho-corasick v1.1.3 (registry `cargo-repo`)
Downloaded regex-automata v0.4.6 (registry `cargo-repo`)
Downloaded 5 crates (1.5 MB) in 1.99s
Compiling memchr v2.7.2 (registry `cargo-repo`)
Compiling regex-syntax v0.8.3 (registry `cargo-repo`)
Compiling aho-corasick v1.1.3 (registry `cargo-repo`)
Compiling regex-automata v0.4.6 (registry `cargo-repo`)
Compiling regex v1.10.4 (registry `cargo-repo`)
Compiling hello_world v0.1.0 (/home/ec2-user/hello_world)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 16.60sI can verify CodeArtifact downloaded the crate and its dependencies from the upstream public repository. I connect to the CodeArtifact console and check the list of packages available in either repository I created. At this stage, the package list should be identical in the two repositories.

Publish a private package to the repository
Now that I know the upstream link works as intended, let’s publish a private package to my cargo-repo repository to make it available to other teams in my organization.
To do so, I use the standard Rust tool cargo, just like usual. Before doing so, I add and commit the project files to the gitrepository.
$ git add . && git commit -m "initial commit"
5 files changed, 1855 insertions(+)
create mode 100644 .gitignore
create mode 100644 Cargo.lock
create mode 100644 Cargo.toml
create mode 100644 commands.sh
create mode 100644 src/main.rs
$ cargo publish
Updating `codeartifact` index
Packaging hello_world v0.1.0 (/home/ec2-user/hello_world)
Updating crates.io index
Updating `codeartifact` index
Verifying hello_world v0.1.0 (/home/ec2-user/hello_world)
Compiling libc v0.2.155
... (redacted for brevity) ....
Compiling hello_world v0.1.0 (/home/ec2-user/hello_world/target/package/hello_world-0.1.0)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1m 03s
Packaged 5 files, 44.1KiB (11.5KiB compressed)
Uploading hello_world v0.1.0 (/home/ec2-user/hello_world)
Uploaded hello_world v0.1.0 to registry `cargo-repo`
note: waiting for `hello_world v0.1.0` to be available at registry `cargo-repo`.
You may press ctrl-c to skip waiting; the crate should be available shortly.
Published hello_world v0.1.0 at registry `cargo-repo`Lastly, I use the console to verify the hello_world crate is now available in the cargo-repo.

Pricing and availability
You can now store your Rust libraries in the 13 AWS Regions where CodeArtifact is available. There is no additional cost for Rust packages. The three billing dimensions are the storage (measured in GB per month), the number of requests, and the data transfer out to the internet or to other AWS Regions. Data transfer to AWS services in the same Region is not charged, meaning you can run your continuous integration and delivery (CI/CD) jobs on Amazon Elastic Compute Cloud (Amazon EC2) or AWS CodeBuild, for example, without incurring a charge for the CodeArtifact data transfer. As usual, the pricing page has the details.
Now go build your Rust applications and upload your private crates to CodeArtifact!
-- sebfrom AWS News Blog https://ift.tt/aRq73Ff
via IFTTT
Anthropic’s Claude 3.5 Sonnet model now available in Amazon Bedrock: Even more intelligence than Claude 3 Opus at one-fifth the cost
It’s been just 3 months since Anthropic launched Claude 3, a family of state-of-the-art artificial intelligence (AI) models that allows you to choose the right combination of intelligence, speed, and cost that suits your needs.
Today, Anthropic introduced Claude 3.5 Sonnet, its first release in the forthcoming Claude 3.5 model family. We are happy to announce that Claude 3.5 Sonnet is now available in Amazon Bedrock.
Claude 3.5 Sonnet raises the industry bar for intelligence, outperforming other generative AI models on a wide range of evaluations, including Anthropic’s previously most intelligent model, Claude 3 Opus. Claude 3.5 Sonnet is available with the speed and cost of the original Claude 3 Sonnet model. In fact, you can now get intelligence and speed better than Claude 3 Opus at one-fifth of the price because Claude 3.5 Sonnet is 80 percent cheaper than Opus.

The frontier intelligence displayed by Claude 3.5 Sonnet combined with cost-effective pricing, makes the model ideal for complex tasks such as context-sensitive customer support, orchestrating multi-step workflows, and streamlining code translations.
Claude 3.5 Sonnet sets new industry benchmarks for undergraduate-level expert knowledge (MMLU), graduate-level expert reasoning (GPQA), code (HumanEval), and more. As you can see in the following table, according to Anthropic, Claude 3.5 Sonnet outperforms OpenAI’s GPT-4o and Google’s Gemini 1.5 Pro in nearly every benchmark.

Claude 3.5 Sonnet is also Anthropic’s strongest vision model yet, performing an average of 10 percent better than Claude 3 Opus across the majority of vision benchmarks. According to Anthropic, Claude 3.5 Sonnet also outperforms other generative AI models in nearly every category.

Anthropic’s Claude 3.5 Sonnet key improvements
The release of Claude 3.5 Sonnet brings significant improvements across multiple domains, empowering software developers and businesses with new generative AI-powered capabilities. Here are some of the key strengths of this new model:
Visual processing and understanding – Claude 3.5 Sonnet demonstrates remarkable capabilities in processing images, particularly in interpreting charts and graphs. It accurately transcribes text from imperfect images, a core capability for industries such as retail, logistics, and financial services, to gather more insights from graphics or illustrations than from text alone. Use Claude 3.5 Sonnet to automate visual data processing tasks, extract valuable information, and enhance data analysis pipelines.
Writing and content generation – Claude 3.5 Sonnet represents a significant leap in its ability to understand nuance and humor. The model produces high-quality written content with a more natural, human tone that feels more authentic and relatable. Use the model to generate engaging and compelling content, streamline your writing workflows, and enhance your storytelling capabilities.
Customer support and natural language processing – With its improved understanding of context and multistep workflow orchestration, Claude 3.5 Sonnet excels at handling intricate customer inquiries. This capability enables round-the-clock support, faster response times, and more natural-sounding interactions, ultimately leading to improved customer satisfaction. Use this model to automate and enhance customer support processes and provide a seamless experience for end users. For an example of a similar implementation, see how DoorDash built a generative AI self-service contact center solution using Anthropic’s Claude 3 models in Amazon Bedrock.
Analytics and insights – Claude 3.5 Sonnet augments human expertise in data science by effortlessly navigating unstructured data and using multiple tools to generate insights. It produces high-quality statistical visualizations and actionable predictions, ranging from business strategies to real-time product trends. Use Claude 3.5 Sonnet to simplify data analysis workflows, uncover valuable insights, and drive data-driven decision-making.
Coding and software development – Claude 3.5 Sonnet can independently write, edit, and execute code with sophisticated reasoning and troubleshooting capabilities when provided with the relevant tools. Use Claude 3.5 Sonnet to streamline developer workflows, accelerate coding tasks, reduce manual effort, and enhance overall productivity.
Using Anthropic’s Claude 3.5 Sonnet in the Amazon Bedrock console
Because this is a new model, I go to the Amazon Bedrock console and choose Model access from the navigation pane to enable access to Claude 3.5 Sonnet.

Now that I have access to the model, I’d like to use it to extract information from the following image from the Our World in Data website:

I choose Chat in the Playgrounds section of the navigation pane and select Anthropic and Claude 3.5 Sonnet as the model. I then choose the Image upload button to upload the previous image, type the following prompt, and choose Run:
Which countries consume more than 1000 TWh from hydropower? Think step by step and look at all regions. Output in JSON.
Here’s the result and an animated image recapping what I did.

The model’s ability to reliably extract information from unstructured data, like images, opens up a world of new possibilities.
I choose the three small dots in the corner of the playground window and then View API request to see code examples using the model in the AWS Command Line Interface (AWS CLI) and AWS SDKs. Let’s have a better look at the code syntax.
Using Claude 3.5 Sonnet with AWS SDKs
You can use Claude 3.5 Sonnet with any AWS SDK using the new Amazon Bedrock Converse API or Anthropic Claude Messages API.
To update code already using a Claude 3 model, I just need to replace the model ID with:
anthropic.claude-3-5-sonnet-20240620-v1:0
Here’s a sample implementation with the AWS SDK for Python (Boto3) using the same image as before to show how to use images and text with the Converse API.
import boto3
from botocore.exceptions import ClientError
MODEL_ID = "anthropic.claude-3-5-sonnet-20240620-v1:0"
IMAGE_NAME = "primary-energy-hydro.png"
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
with open(IMAGE_NAME, "rb") as f:
image = f.read()
user_message = "Which countries consume more than 1000 TWh from hydropower? Think step by step and look at all regions. Output in JSON."
messages = [
{
"role": "user",
"content": [
{"image": {"format": "png", "source": {"bytes": image}}},
{"text": user_message},
],
}
]
response = bedrock_runtime.converse(
modelId=MODEL_ID,
messages=messages,
)
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)When I run it, I get a similar output as in the console:
Because I didn’t specify a JSON syntax, the two answers use a different format. In your applications, you can describe in the prompt the JSON properties you want or provide a sample to get a standard format in output.
For more examples, see the code samples in the Amazon Bedrock User Guide. For a more advanced use case, here’s a fully functional tool use demo illustrating how to connect a generative AI model with a custom tool or API.
Using Claude 3.5 Sonnet with the AWS CLI
There are times when nothing beats the speed of the command line. This is how you can use the AWS CLI with the new model:
In the output, I use the query option to only get the content of the output message:
[
{
"text": "Let's approach this step-by-step:\n\n1. First, we need to understand the relationships:\n - Alice has N brothers\n - Alice has M sisters\n\n2. Now, let's consider Alice's brother:\n - He is one of Alice's N brothers\n - He has the same parents as Alice\n\n3. This means that Alice's brother has:\n - The same sisters as Alice\n - One sister more than Alice (because Alice herself is his sister)\n\n4. Therefore, the number of sisters Alice's brother has is:\n M + 1\n\n Where M is the number of sisters Alice has.\n\nSo, the answer is: Alice's brother has M + 1 sisters."
}
]I copy the text into a small Python program to see it printed on multiple lines:
print("Let's approach this step-by-step:\n\n1. First, we need to understand the relationships:\n - Alice has N brothers\n - Alice has M sisters\n\n2. Now, let's consider Alice's brother:\n - He is one of Alice's N brothers\n - He has the same parents as Alice\n\n3. This means that Alice's brother has:\n - The same sisters as Alice\n - One sister more than Alice (because Alice herself is his sister)\n\n4. Therefore, the number of sisters Alice's brother has is:\n M + 1\n\n Where M is the number of sisters Alice has.\n\nSo, the answer is: Alice's brother has M + 1 sisters.")Even if this was a quite nuanced question, Claude 3.5 Sonnet got it right and described its reasoning step by step.
Things to know
Anthropic’s Claude 3.5 Sonnet is available in Amazon Bedrock today in the US East (N. Virginia) AWS Region. More information on Amazon Bedrock model support by Region is available in the documentation. View the Amazon Bedrock pricing page to determine the costs for your specific use case.
By providing access to a faster and more powerful model at a lower cost, Claude 3.5 Sonnet makes generative AI easier and more effective to use for many industries, such as:
Healthcare and life sciences – In the medical field, Claude 3.5 Sonnet shows promise in enhancing imaging analysis, acting as a diagnostic assistant for patient triage, and summarizing the latest research findings in an easy-to-digest format.
Financial services – The model can provide valuable assistance in identifying financial trends and creating personalized debt repayment plans tailored to clients’ unique situations.
Legal – Law firms can use the model to accelerate legal research by quickly surfacing relevant precedents and statutes. Additionally, the model can increase paralegal efficiency through contract analysis and assist with drafting standard legal documents.
Media and entertainment – The model can expedite research for journalists, support the creative process of scriptwriting and character development, and provide valuable audience sentiment analysis.
Technology – For software developers, Claude 3.5 Sonnet offers opportunities in rapid application prototyping, legacy code migration, innovative feature ideation, user experience optimization, and identification of friction points.
Education – Educators can use the model to streamline grant proposal writing, develop comprehensive curricula incorporating emerging trends, and receive research assistance through database queries and insight generation.
It’s an exciting time for for generative AI. To start using this new model, see the Anthropic Claude models section of the Amazon Bedrock User Guide. You can also visit our community.aws site to find deep-dive technical content and to discover how our Builder communities are using Amazon Bedrock in their solutions. Let me know what you do with these enhanced capabilities!
— Danilo
from AWS News Blog https://ift.tt/hCpdjus
via IFTTT
Wednesday, June 19, 2024
Update: Product Pricing API v2022-05-01 now supports the getFeaturedOfferExpectedPriceBatch operation in all marketplaces except Japan
Announcing the general availability of fully managed MLflow on Amazon SageMaker
Today, we are thrilled to announce the general availability of a fully managed MLflow capability on Amazon SageMaker. MLflow, a widely-used open-source tool, plays a crucial role in helping machine learning (ML) teams manage the entire ML lifecycle. With this new launch, customers can now effortlessly set up and manage MLflow Tracking Servers with just a few steps, streamlining the process and boosting productivity.
Data Scientists and ML developers can leverage MLflow to track multiple attempts at training models as runs within experiments, compare these runs with visualizations, evaluate models, and register the best models to a Model Registry. Amazon SageMaker eliminates the undifferentiated heavy lifting required to set up and manage MLflow, providing ML administrators with a quick and efficient way to establish secure and scalable MLflow environments on AWS.
Core components of managed MLflow on SageMaker
The fully managed MLflow capability on SageMaker is built around three core components:
- MLflow Tracking Server – With just a few steps, you can create an MLflow Tracking Server through the SageMaker Studio UI. This stand-alone HTTP server serves multiple REST API endpoints for tracking runs and experiments, enabling you to begin monitoring your ML experiments efficiently. For more granular security customization, you can also use the AWS Command Line Interface (AWS CLI).
- MLflow backend metadata store – The metadata store is a critical part of the MLflow Tracking Server, where all metadata related to experiments, runs, and artifacts is persisted. This includes experiment names, run IDs, parameter values, metrics, tags, and artifact locations, ensuring comprehensive tracking and management of your ML experiments.
- MLflow artifact store – This component provides a storage location for all artifacts generated during ML experiments, such as trained models, datasets, logs, and plots. Utilizing an Amazon Simple Storage Service (Amazon S3) bucket, it offers a customer-managed AWS account for storing these artifacts securely and efficiently.

Benefits of Amazon SageMaker with MLflow
Using Amazon SageMaker with MLflow can streamline and enhance your machine learning workflows:
- Comprehensive Experiment Tracking: Track experiments in MLflow across local integrated development environments (IDEs), managed IDEs in SageMaker Studio, SageMaker training jobs, SageMaker processing jobs, and SageMaker Pipelines.
- Full MLflow Capabilities: Use all MLflow experimentation capabilities such as MLflow Tracking, MLflow Evaluations, and MLflow Model Registry, are available to easily compare and evaluate the results of training iterations.
- Unified Model Governance: Models registered in MLflow automatically appear in the SageMaker Model Registry, offering a unified model governance experience that helps you deploy MLflow models to SageMaker inference without building custom containers.
- Efficient Server Management: Provision, remove, and upgrade MLflow Tracking Servers as desired using SageMaker APIs or the SageMaker Studio UI. SageMaker manages the scaling, patching, and ongoing maintenance of your tracking servers, without customers needing to manage the underlying infrastructure.
- Enhanced Security: Secure access to MLflow Tracking Servers using AWS Identity and Access Management (IAM). Write IAM policies to grant or deny access to specific MLflow APIs, ensuring robust security for your ML environments.
- Effective Monitoring and Governance: Monitor the activity on an MLflow Tracking Server using Amazon EventBridge and AWS CloudTrail to support effective governance of their Tracking Servers.
MLflow Tracking Server prerequisites (environment setup)
- Create a SageMaker Studio domain
You can create a SageMaker Studio domain using the new SageMaker Studio experience.
- Configure the IAM execution role
The MLflow Tracking Server needs an IAM execution role to read and write artifacts to Amazon S3 and register models in SageMaker. You can use the Studio domain execution role as the Tracking Server execution role or you can create a separate role for the Tracking Server execution role. If you choose to create a new role for this, refer to the SageMaker Developer Guide for more details on the IAM role. If you choose to update the Studio domain execution role, refer to the SageMaker Developer Guide for details on what IAM policy the role needs.
Create the MLflow Tracking Server
In the walkthrough, I use the default settings for creating an MLflow Tracking Server, which include the Tracking Server version (2.13.2), the Tracking Server size (Small), and the Tracking Server execution role (Studio domain execution role). The Tracking Server size determines how much usage a Tracking Server will support, and we recommend using a Small Tracking Server for teams of up to 25 users. For more details on Tracking Server configurations, read the SageMaker Developer Guide.
To get started, in your SageMaker Studio domain created during your environment set up detailed earlier, select MLflow under Applications and choose Create.

Next, provide a Name and Artifact storage location (S3 URI) for the Tracking Server.
Creating an MLflow Tracking Server can take up to 25 minutes.

Track and compare training runs
To get started with logging metrics, parameters, and artifacts to MLflow, you need a Jupyter Notebook and your Tracking Server ARN that was assigned during the creation step. You can use the MLflow SDK to keep track of training runs and compare them using the MLflow UI.

To register models from MLflow Model Registry to SageMaker Model Registry, you need the sagemaker-mlflow plugin to authenticate all MLflow API requests made by the MLflow SDK using AWS Signature V4.
- Install the MLflow SDK and
sagemaker-mlflowplugin
In your notebook, first install the MLflow SDK and sagemaker-mlflow Python plugin.
pip install mlflow==2.13.2 sagemaker-mlflow==0.1.0 - Track a run in an experiment
To track a run in an experiment, copy the following code into your Jupyter notebook.import mlflow import mlflow.sklearn from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # Replace this with the ARN of the Tracking Server you just created arn = 'YOUR-TRACKING-SERVER-ARN' mlflow.set_tracking_uri(arn) # Load the Iris dataset iris = load_iris() X, y = iris.data, iris.target # Split the data into training and testing sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Train a Random Forest classifier rf_model = RandomForestClassifier(n_estimators=100, random_state=42) rf_model.fit(X_train, y_train) # Make predictions on the test set y_pred = rf_model.predict(X_test) # Calculate evaluation metrics accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred, average='weighted') recall = recall_score(y_test, y_pred, average='weighted') f1 = f1_score(y_test, y_pred, average='weighted') # Start an MLflow run with mlflow.start_run(): # Log the model mlflow.sklearn.log_model(rf_model, "random_forest_model") # Log the evaluation metrics mlflow.log_metric("accuracy", accuracy) mlflow.log_metric("precision", precision) mlflow.log_metric("recall", recall) mlflow.log_metric("f1_score", f1) - View your run in the MLflow UI
Once you run the notebook shown in Step 2, you will see a new run in the MLflow UI.

- Compare runs
You can run this notebook multiple times by changing therandom_stateto generate different metric values for each training run.

Register candidate models
Once you’ve compared the multiple runs as detailed in Step 4, you can register the model whose metrics best meet your requirements in the MLflow Model Registry. Registering a model indicates potential suitability for production deployment and there will be further testing to validate this suitability. Once a model is registered in MLflow it automatically appears in the SageMaker Model Registry for a unified model governance experience so you can deploy MLflow models to SageMaker inference. This enables data scientists who primarily use MLflow for experimentation to hand off their models to ML engineers who govern and manage production deployments of models using the SageMaker Model Registry.
Here is the model registered in the MLflow Model Registry.

Here is the model registered in the SageMaker Model Registry.

Clean up
Once created, an MLflow Tracking Server will incur costs until you delete or stop it. Billing for Tracking Servers is based on the duration the servers have been running, the size selected, and the amount of data logged to the Tracking Servers. You can stop Tracking Servers when they are not in use to save costs or delete them using API or the SageMaker Studio UI. For more details on pricing, see the Amazon SageMaker pricing.

Now available
SageMaker with MLflow is generally available in all AWS Regions where SageMaker Studio is available, except China and US GovCloud Regions. We invite you to explore this new capability and experience the enhanced efficiency and control it brings to your machine learning projects. To learn more, visit the SageMaker with MLflow product detail page.
For more information, visit the SageMaker Developer Guide and send feedback to AWS re:Post for SageMaker or through your usual AWS support contacts.
— Veliswa
from AWS News Blog https://ift.tt/QNn81Tl
via IFTTT
Subscribe to:
Comments (Atom)