Monday, December 30, 2024

Monday, December 23, 2024
Thursday, December 19, 2024
Stable Diffusion 3.5 Large is now available in Amazon Bedrock
As we preannounced at AWS re:Invent 2024, you can now use Stable Diffusion 3.5 Large in Amazon Bedrock to generate high-quality images from text descriptions in a wide range of styles to accelerate the creation of concept art, visual effects, and detailed product imagery for customers in media, gaming, advertising, and retail.
In October 2024, Stability AI introduced Stable Diffusion 3.5 Large, the most powerful model in the Stable Diffusion family at 8.1 billion parameters trained on Amazon SageMaker HyperPod, with superior quality and prompt adherence. Stable Diffusion 3.5 Large can accelerate storyboarding, concept art creation, and rapid prototyping of visual effects. You can quickly generate high-quality 1-megapixel images for campaigns, social media posts, and advertisements, saving time and resources while maintaining creative control.
Stable Diffusion 3.5 Large offers users nearly endless creative possibilities, including:
- Versatile Styles – You can generate images in a wide range of styles and aesthetics, including 3-dimentional, photography, painting, line art, and virtually any visual style you can imagine.
- Prompt Adherence – You can use Stable Diffusion 3.5 Large’s advanced prompt adherence to closely follow your text prompts, making it a top choice for efficient, high-quality performance.
- Diverse Outputs – You can create images representative of the diverse world around you, featuring people with different skin tones and features, without the need for extensive prompting.
Today, Stable Image Ultra in Amazon Bedrock has been updated to include Stable Diffusion 3.5 Large in the model’s underlying architecture. Stable Image Ultra, powered by Stability AI’s most advanced models, including Stable Diffusion 3.5, sets a new standard in image generation. It excels in typography, intricate compositions, dynamic lighting, vibrant colors, and artistic cohesion.
With the latest update of Stable Diffusion models in Amazon Bedrock, you have a broader set of solutions to boost your creativity and accelerate image generation workflows.
Get started with Stable Diffusion 3.5 Large in Amazon Bedrock
Before getting started, if you are new to using Stability AI models, go to the Amazon Bedrock console and choose Model access on the bottom left pane. To access the latest Stability AI models, request access for Stable Diffusion 3.5 Large in Stability AI.

To test the Stability AI models in Amazon Bedrock, choose Image/Video under Playgrounds in the left menu pane. Then choose Select model and select Stability AI as the category and Stable Diffusion 3.5 Large as the model.

You can generate an image with your prompt. Here is a sample prompt to generate the image:
High-energy street scene in a neon-lit Tokyo alley at night, where steam rises from food carts, and colorful neon signs illuminate the rain-slicked pavement.

By choosing View API request, you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDKs. You can use stability.sd3-5-large-v1:0 as the model ID.
To get the image with a single command, I write the output JSON file to standard output and use the jq tool to extract the encoded image so that it can be decoded on the fly. The output is written in the img.png file.
Here is a sample of the AWS CLI command:
$ aws bedrock-runtime invoke-model \
--model-id stability.sd3-5-large-v1:0 \
--body "{\"text_prompts\":[{\"text\":\"High-energy street scene in a neon-lit Tokyo alley at night, where steam rises from food carts, and colorful neon signs illuminate the rain-slicked pavement.\",\"weight\":1}],\"cfg_scale\":0,\"steps\":10,\"seed\":0,\"width\":1024,\"height\":1024,\"samples\":1}" \
--cli-binary-format raw-in-base64-out \
--region us-west-2 \
/dev/stdout | jq -r '.images[0]' | base64 --decode > img.jpgHere’s how you can use Stable Image Ultra 1.1 to include Stable Diffusion 3.5 Large in the model’s underlying architecture with the AWS SDK for Python (Boto3). This simple application interactively asks for a text-to-image prompt and then calls Amazon Bedrock to generate the image with stability.stable-image-ultra-v1:1 as the model ID.
import base64
import boto3
import json
import os
MODEL_ID = "stability.stable-image-ultra-v1:1"
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-west-2")
print("Enter a prompt for the text-to-image model:")
prompt = input()
body = {
"prompt": prompt,
"mode": "text-to-image"
}
response = bedrock_runtime.invoke_model(modelId=MODEL_ID, body=json.dumps(body))
model_response = json.loads(response["body"].read())
base64_image_data = model_response["images"][0]
i, output_dir = 1, "output"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
while os.path.exists(os.path.join(output_dir, f"img_{i}.png")):
i += 1
image_data = base64.b64decode(base64_image_data)
image_path = os.path.join(output_dir, f"img_{i}.png")
with open(image_path, "wb") as file:
file.write(image_data)
print(f"The generated image has been saved to {image_path}")The application writes the resulting image in an output directory that is created if not present. To not overwrite existing files, the code checks for existing files to find the first file name available with the img_<number>.png format.
To learn more, visit the Invoke API examples using AWS SDKs to build your applications to generate an image using various programming languages.
Interesting examples
Here are a few images created with Stable Diffusion 3.5 Large.
 |
 |
Prompt: Full-body university students working on a tech project with the words Stable Diffusion 3.5 in Amazon Bedrock, cheerful cursive typography font in the foreground. |
Prompt: Photo of three potions: the first potion is blue with the label "MANA", the second potion is red with the label "HEALTH", the third potion is green with the label "POISON". Old apothecary. |
 |
 |
Prompt: Photography, pink rose flowers in the twilight, glowing, tile houses in the background. |
Prompt: 3D animation scene of an adventurer traveling the world with his pet dog. |
Now available
Stable Diffusion 3.5 Large model is generally available today in Amazon Bedrock in the US West (Oregon) AWS Region. Check the full Region list for future updates. To learn more, check out the Stability AI in Amazon Bedrock product page and the Amazon Bedrock Pricing page.
Give Stable Diffusion 3.5 Large a try in the Amazon Bedrock console today and send feedback to AWS re:Post for Amazon Bedrock or through your usual AWS Support contacts.
— Channy
from AWS News Blog https://ift.tt/SaVNFXi
via IFTTT

Powerful Amazon Advertising Sponsored Brands Search Term Report

If you are an Amazon Selling Partner, Agency, Consultant, or a brand on Vendor Central, running an Amazon Advertising Sponsored Brands campaign means targeting shopper intent and competing for shoppers' attention.
But how do you know if your keywords are doing their job?
Enter the Amazon Advertising Sponsored Brands Search Term Report. This report helps you see which keywords increase clicks, sales, and new customers.
In this article, we’ll walk through the basics of the Search Terms Report and how you can use it to guide your strategy, save time, and boost your results. (see Amazon Advertising Help Center — Sponsored Brands Search Term Report)
Why the Search Terms Report is Essential for Sponsored Brands
Choosing the right keywords can be tricky. You want to reach shoppers most likely to buy, not waste your budget on terms that don’t convert. The Keyword Report shows you exactly which keywords are working and which aren’t, helping you:
- Understand which search terms lead to sales and which don’t
- Make smarter decisions about bidding and budget
- Find new keyword ideas to grow your brand reach
By seeing actual data on impressions, clicks, and conversions, you’ll spend your money more wisely and gain an edge in the marketplace.
Key Metrics Featured in the Sponsored Brands Search TermsReport
The report includes a few essential metrics. Understanding them will help you spot trends and opportunities:
- Impressions: How often does your ad show up?
- Clicks & Click-Through Rate (CTR): Are people who see your ad clicking it?
- Cost-Per-Click (CPC): How much you pay each time someone clicks.
- Conversions & Conversion Rate: How many clicks lead to sales.
- New-to-Brand Sales: How many first-time customers your brand is winning.
These are not the only metrics, using the Openbridge AI Data Copilot, you can see the complete Sponsored Brands Search Term Report schema:
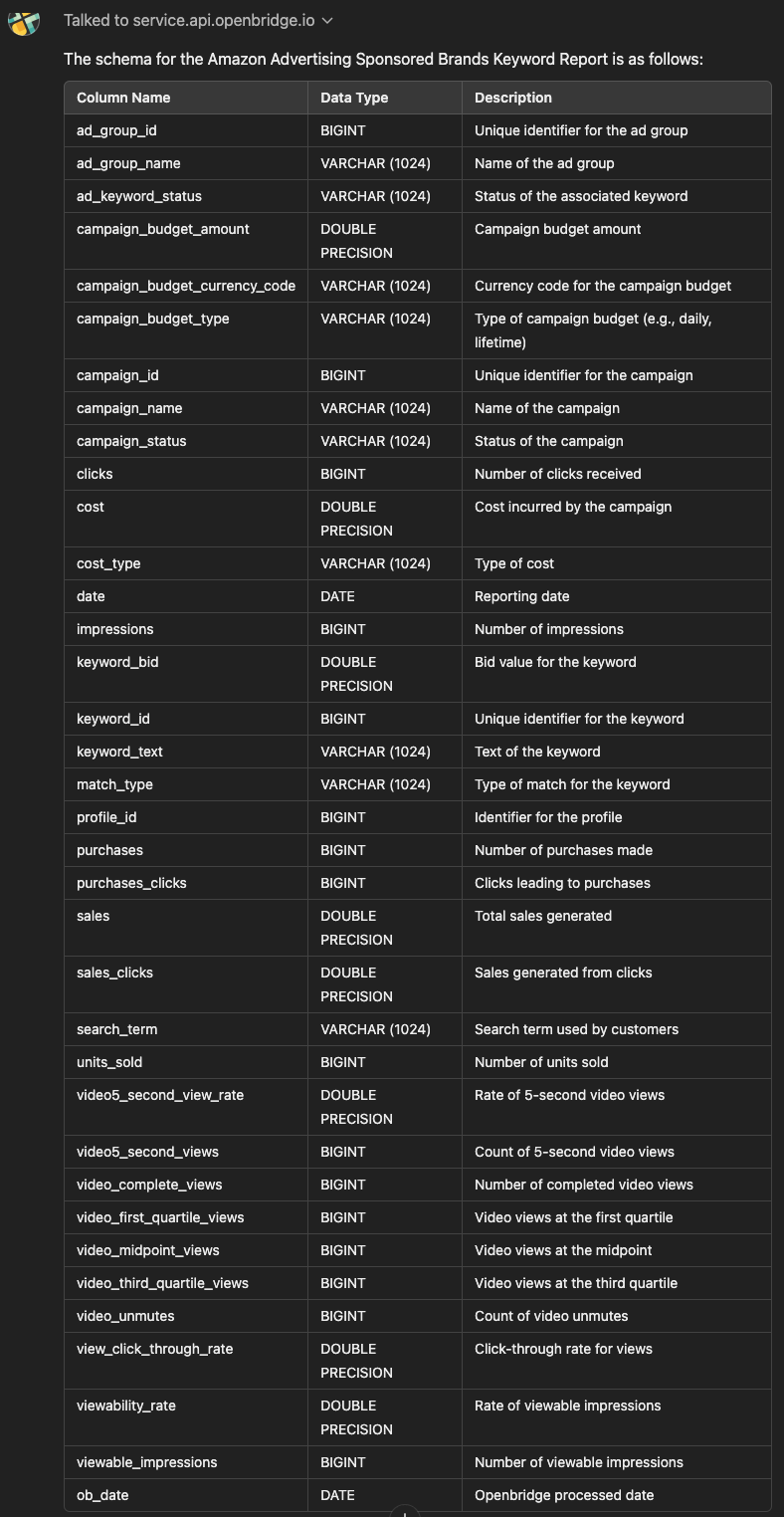
With the various report metrics, you can see what’s working and what’s not. For example, a high CTR but a low conversion rate might mean shoppers are curious but unconvinced. A strong New-to-Brand number suggests you’re drawing fresh eyes to your brand.
Identifying High-Performing and Low-Performing Keywords
Once you have the report, it’s time to dig in. Sort or filter the spreadsheet by your key metrics. Looking for winners? Check for:
- High CTR and conversions
- Low CPC
- Strong New-to-Brand sales
These are the keywords you may want to invest more in. Conversely, consider lowering bids or pausing keywords with low CTR, high costs, or weak sales. For example, if “organic dog treats” drive strong conversions while “healthy dog snacks” barely get clicks, focus on “organic dog treats (see Amazon Ads Learning Console — Optimization Tips).
Leveraging Match Types for Better Targeting
Match types control how closely a shopper’s search must match your keyword. If the Keyword Report shows:
- Exact match terms are converting well, you might raise bids on those terms.
- Broad match terms are getting clicks but not sales; it might be time to refine them.
- Phrase match terms doing well might be worth testing as exact matches to fine-tune targeting.
Using the report’s data, you can adjust which match types you emphasize. For instance, switching a high-performing broad match keyword to an exact match can focus your reach and reduce wasted ad spend.
Integrating Insights from the Search Term Report into Campaign Management
The Keyword Report isn’t just a bunch of numbers — it’s a roadmap. Use it to:
- Adjust bids: Spend more on keywords that drive profits and spend less on ones that don’t.
- Revise budgets: Shift more of the budget to performing the best campaigns.
- Add or remove keywords: Add fresh keywords or remove those that don’t measure up.
Make it a habit to review your Keyword Report regularly. Checking it every month or quarter can help you stay on top of trends and respond to changes quickly. Pairing these insights with other Amazon ads reports — like the Search Term Report — gives you a complete picture of your campaign performance.
Expanding Keyword Lists with Search Term Insights
Your Search Term Report can also help you grow. You can add those as new keywords by reviewing the search terms that deliver strong results. On the flip side, you can also add low-performing search terms as negative keywords to block them, saving money. This constant refining helps you reach the right shoppers and improve your campaign health.
How to Be a Data-Driven Advertiser: Manual or Automation?
Here’s how to manually get your Search Term Report:
- Log in: Access your Amazon Advertising console.
- Find Reports: Click on the “Reports” tab in your dashboard.
- Choose Sponsored Brands: Select “Sponsored Brands” and then pick “Keyword” as the type.
- Select Timeframe: Pick “daily” or “summary” data.
- Download: Hit “Run Report” and then download the file (usually in CSV format).
Looking to automate the flow of these reports?
Getting Started with Keyword Report Automation
Ditch the messy, manual reporting for Sponsored Brands Keyword Reports. Automated data feeds guide data-driven decision-making to improve off-Amazon digital marketing campaigns. Leverage attribution insights to refine strategies, allocate resources efficiently, and enhance customer engagement across all touchpoints.
Openbridge will unify and deliver performance data to data lakes or warehouses like Redshift, Google BigQuery, Snowflake, Azure Data Lake, and Amazon Athena, giving you a single source of truth. This unified data can turbocharge reporting and analytics tools like Google Data Studio, Tableau, Microsoft Power BI, Looker, Amazon QuickSight, SAP, Alteryx, dbt, Azure Data Factory, and Qlik Sense.
>> Get a 30-day free trial to try Amazon Ads Sponsored Brands Search Term Report automation. <<
Powerful Amazon Advertising Sponsored Brands Search Term Report was originally published in Openbridge on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Openbridge - Medium https://ift.tt/9xhbQIu
via Openbridge
Wednesday, December 18, 2024
Monday, December 16, 2024
And that’s a wrap!
After 20 years, and 3283 posts adding up to 1,577,106 words I am wrapping up my time as the lead blogger on the AWS News Blog.
It has been a privilege to be able to “live in the future” and to get to learn and write about so many of our innovations over the last two decades: message queuing, storage, on-demand computing, serverless, and quantum computing to name just a few and to leave many others out. It has also been a privilege to be able to meet and to hear from so many of you that have faithfully read and (hopefully) learned from my content over the years. I treasure those interactions and your kind words, and I keep both in mind when I write.
Next for Jeff
I began my career as a builder. Over the years I have written tens of thousands of lines of assembly code (6502, Z80, and 68000), Visual Basic, and PHP, along with hundreds of thousands of lines of C. However, over the years I’ve progressively spent less time building and more time talking about building. As each new service and feature whizzed past my eyes I would reminiscence about days and decades past, when I could actually use these goodies to create something cool. I went from being a developer who could market, to a marketer who used to be able to develop. There’s absolutely nothing wrong with that, but I like to build. The medium could be code, 3D printing, LEGO bricks, electronics components, or even cardboard –creating and innovating is what motivates and sustains me.
With that as my driving force, my goal for the next step of my career is to invest more time focused on learning and using fewer things, building cool stuff, and creating fresh, developer-focused content as I do so. I’m still working to figure out the form that this will take, so stay tuned. I am also going to continue to make my weekly appearances at AWS OnAir (our Friday Twitch show), and I will continue to speak at AWS community events around the globe.
Next for the Blog
As for the AWS News Blog, it has long been backed by an awesome team, both visible and invisible. Here we are at the recent AWS re:Invent celebration of the blog’s 20th anniversary (photo courtesy of Liz Fuentes with edits by Channy Yun to add those who were otherwise occupied):

During the celebration I told the team that I look forward to celebrating the 30 year anniversary with them at re:Invent 2034.
Going forward, the team will continue to grow and the goal remains the same: to provide our customers with carefully chosen, high-quality information about the latest and most meaningful AWS launches. The blog is in great hands and this team will continue to keep you informed even as the AWS pace of innovation continues to accelerate.
Thanks Again
Once again I need to thank all of you for the very kind words and gestures over the years. Once in your life, if you work hard and get really lucky, you get a unique opportunity to do something that really and truly matters to people. And I have been lucky.
— Jeff;
from AWS News Blog https://ift.tt/YQic13B
via IFTTT

Amazon Advertising Sponsored Products Campaign Report

If you’re selling products on Amazon and running ads, you’re probably familiar with the importance of tracking and optimizing your ad performance. But how can you know if your efforts are paying off? That’s where the Amazon Advertising Sponsored Product Campaign Report comes in.
Whether new to Amazon advertising or looking to sharpen your strategy, understanding these reports can make a huge difference in maximizing your ad spending and growing your business.
Understanding the Campaign Report for Sponsored Products
The Campaign Report for Sponsored Products is a comprehensive tool designed to show how well your ads perform over a specified period. You can use it to evaluate everything from daily performance to monthly trends, allowing you to make informed decisions on improving your campaigns.
This report summarizes the performance of your Sponsored Products ads across different campaigns. It tracks crucial metrics and helps you analyze the effectiveness of your ad strategies. You can use it to:
- Track your ad spend
- See how many impressions (views) your ads are getting
- Measure how often people are clicking on your ads
- Evaluate how much revenue your ads are generating
In short, the Campaign Report is your one-stop shop for tracking how well your ads are doing and what changes need to be made.
Types of Data Available in the Report
The Sponsored Product campaign report offers a variety of data types that can be helpful depending on how deep you want to dive into your ad performance. When you drill down into your report, you’ll see a variety of metrics that give a complete view of your campaign’s performance. Key metrics include:
- Impressions: Understanding impressions can help you gauge the reach of your ads. If your impressions are low, it might indicate that your ads aren’t being shown to enough people.
- Clicks: Clicks are a critical metric. A high click-through rate (CTR) generally means your ad appeals to customers. If clicks are low, your ad needs better call-to-action or more engaging visuals.
- Spend: This metric shows how much money you’ve invested in the campaign. Tracking spend is essential for understanding whether you’re getting a good return on your investment.
- Sales: Sales data is crucial in determining the effectiveness of your ads. If you get lots of clicks but low sales, your landing pages or product listings may need improvement.
- ACoS and RoAS: These two metrics go hand-in-hand. A low ACoS means you’re spending less on ads than the sales generated, while a high ROAS shows that your advertising dollars are being used effectively.
Here is the list of the base metrics:
- Impressions
- addToList
- qualifiedBorrows
- royaltyQualifiedBorrows
- Clicks
- Cost
- Purchases (1 day)
- Purchases (7 days)
- Purchases (14 days)
- Purchases (30 days)
- Purchases (Same SKU, 1 day)
- Purchases (Same SKU, 7 days)
- Purchases (Same SKU, 14 days)
- Purchases (Same SKU, 30 days)
- Units Sold (Clicks, 1 day)
- Units Sold (Clicks, 7 days)
- Units Sold (Clicks, 14 days)
- Units Sold (Clicks, 30 days)
- Sales (1 day)
- Sales (7 days)
- Sales (14 days)
- Sales (30 days)
- Attributed Sales (Same SKU, 1 day)
- Attributed Sales (Same SKU, 7 days)
- Attributed Sales (Same SKU, 14 days)
- Attributed Sales (Same SKU, 30 days)
- Units Sold (Same SKU, 1 day)
- Units Sold (Same SKU, 7 days)
- Units Sold (Same SKU, 14 days)
- Units Sold (Same SKU, 30 days)
- Kindle Edition Normalized Pages Read (14 days)
- Kindle Edition Normalized Pages Royalties (14 days)
- Date
- Start Date
- End Date
- Campaign Bidding Strategy
- Cost Per Click
- Click Through Rate
- Spend
If you want a real-time AI-driven Amazon Advertising data copilot, the Openbridge AI Data Copilot can get you there fast:
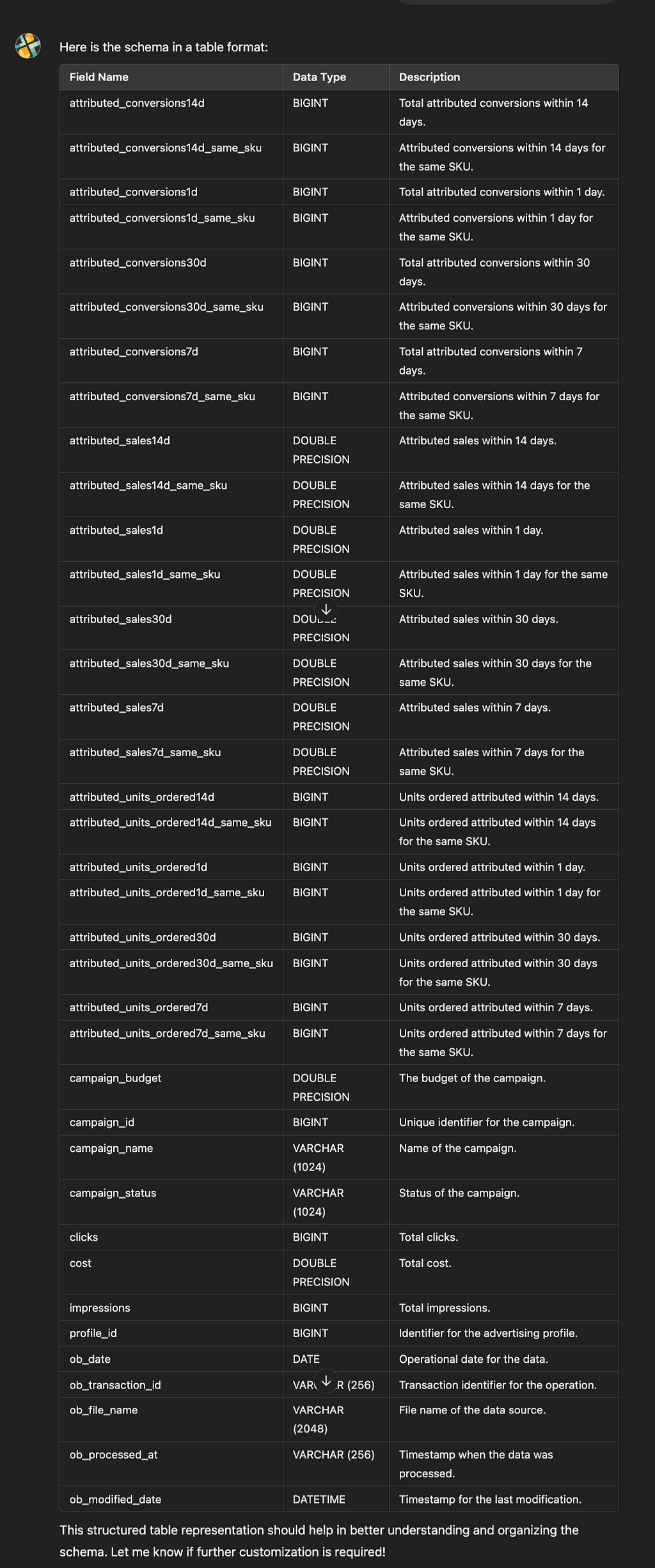
How to Use Campaign Reports to Optimize Ad Performance
As you continue using these reports, remember that consistent analysis and optimization are the keys to success. Regularly review your campaigns, make necessary changes, and continue testing new strategies. The more you engage with your campaign data, the better your results will be.
Identify High-Performing Campaigns
The first step is to identify which campaigns are doing well. Look for campaigns with high sales and a low ACoS. These campaigns are performing effectively, and consider increasing your budget for them or scaling your efforts.
Spotting Underperforming Campaigns
If some campaigns have high ACoS or low sales, it might be time to re-evaluate. Here’s what you can do to improve underperforming campaigns:
- Adjust your bids: If your ads aren’t getting enough impressions, you might need to increase your bid.
- Change your targeting: Try targeting different keywords or your product targeting to reach a more relevant audience.
- Update your ad copy: Sometimes, the wording or images in your ads might not resonate with customers. Test different versions to see what works best.
Adjusting Campaign Settings
Once you’ve reviewed your data, it’s time to make adjustments. Consider:
- Reallocating your budget: If a particular campaign performs well, consider increasing its budget while cutting back on less effective ones.
- Modifying your targeting: Targeting the right audience is key. Use your report data to see which keywords or products generate the best results and focus more on those.
- Optimizing your bidding strategy: If certain keywords are performing better than others, increase your bid for those keywords to ensure your ads get shown more often.
Getting Started with Amazon Ads Sponsored Products Data Automation
Ditch the messy, manual reporting for the Amazon Ads Sponsored Product Campaign Report. Automated data feeds guide data-driven decision-making to improve off-Amazon digital marketing campaigns. Leverage insights to refine strategies, allocate resources efficiently, and enhance customer engagement across all touchpoints.
Openbridge will unify and deliver performance data to leading data lakes or cloud warehouses like Redshift, Google BigQuery, Snowflake, Azure Data Lake, and Amazon Athena for an analytics-ready single source of truth to fuel informed decisions on brand building strategy, media, and customer demand for Amazon.
With your data unified, start to turbocharge reporting, analytics, and business intelligence tools like Google Data Studio, Tableau, Microsoft Power BI, Looker, Amazon QuickSight, SAP, Alteryx, dbt, Azure Data Factory, Qlik Sense, and many others.
— ->>> Get a 30-day free trial to begin your Sponsored Product Campaign Report automation journey.
Amazon Advertising Sponsored Products Campaign Report was originally published in Openbridge on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Openbridge - Medium https://ift.tt/x2n7hdf
via Openbridge
Friday, December 13, 2024

Amazon Advertising Campaign Reports for Sponsored Brands

For Amazon Sellers and Vendors, the Amazon Advertising Campaign Report for Sponsored Brands is a vital tool that offers deep insights into campaign performance. By understanding and utilizing the wealth of information it provides, you can optimize your campaigns, improve ROI, and strategically grow your business.
Understanding the Amazon Advertising Sponsored Brand Campaign Report
The Amazon Advertising Sponsored Brand Campaign Report summarizes your campaign performance over a selected date range. It’s available for Amazon Sellers and Vendor Central retailers running Sponsored brand campaigns.
Key Features of the Campaign Report
By leveraging this report, you can gain valuable insights into your campaigns’ performance and make informed decisions to enhance your advertising efforts. The report offers an aggregated overview of your campaign performance.
Using the Openbridge AI Data Copilot, the schema for this report follows:
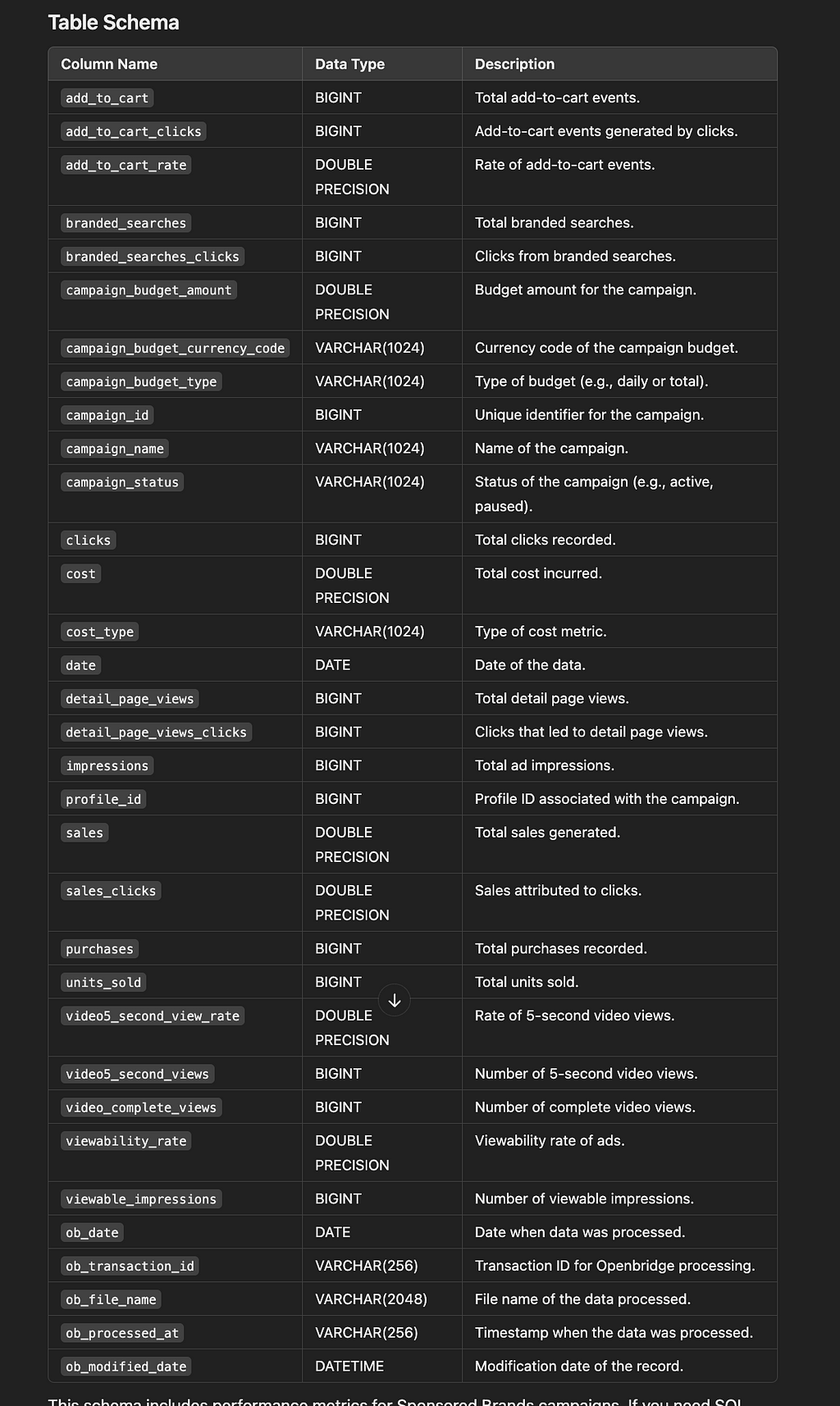
Understanding the report’s insights helps you:
- Assess Campaign Effectiveness: Identify which campaigns are meeting objectives.
- Optimize Budget Allocation: Redirect funds to high-performing campaigns.
- Strategize Growth Opportunities: Spot areas for expansion and increased ROI.
- Branded Searches: Measures brand awareness by tracking how often customers search for your brand.
- New-to-Brand Metrics: Indicates the number of first-time purchasers, highlighting customer acquisition success.
- Sales: Total revenue generated from campaigns.
- Return on Ad Spend (ROAS): Evaluate the efficiency of your advertising spend.
Analyzing these metrics allows you to tailor strategies to different customer journey stages, from awareness to conversion.
Optimizing Campaigns Based on Report Insights
Here are suggestions for optimizing your Sponsored Brand campaigns based on the insights provided in the amzn_ads_sb_campaigns report:
Enhance Budget Allocation
- Action: Monitor campaign_budget_amount and campaign_budget_type to ensure campaigns with high conversion rates (sales/clicks) or click-through rates (view_click_through_rate) have a sufficient budget.
- Why: High-performing campaigns may require increased budgets to avoid missed opportunities due to budget constraints.
Improve Targeting Strategy
- Action: Use data on branded_searches and branded_searches_clicks to identify the effectiveness of brand-related keywords. Invest in high-converting branded terms. Exclude underperforming or irrelevant keywords (negative targeting).
- Why: Focus on targeting terms with the highest relevance and performance to maximize return on ad spend (ROAS).
Analyze Audience Behavior
- Action: Leverage new_to_brand_detail_page_views and new_to_brand_units_sold to evaluate the acquisition of new customers. Develop campaigns targeting segments that show high engagement or conversion potential.
- Why: Prioritizing new-to-brand customers can grow your customer base and ensure long-term profitability.
Optimize Ad Creative
- Action: Review video5_second_view_rate, video_complete_views, and viewability_rate for video campaigns. Test new creatives with higher engagement. Improve video length, content relevance, and call-to-action clarity to increase completion rates.
- Why: High-performing visuals and engaging videos enhance brand recall and drive action.
Refine Bidding Strategy
- Action: Analyze top_of_search_impression_share to evaluate visibility. Increase bids for high-performing campaigns or keywords with strong conversion rates. Lower bids for underperforming campaigns to improve cost efficiency.
- Why: Competitive bids improve placement in high-visibility areas like the top of search results, maximizing clicks and conversions.
Adjust for Seasonality
- Action: Use the date column to identify seasonality trends in performance metrics like impressions, clicks, and sales. Increase spend during peak periods for your category. Decrease spend during slower periods while maintaining brand visibility.
- Why: Aligning budgets and strategies with demand cycles ensures efficient use of advertising resources.
Monitor Campaign Status
- Action: Regularly review campaign_status for campaigns that may be paused or not delivering impressions. Address issues causing campaigns to pause (e.g., budget exhaustion, eligibility issues).
- Why: Active management ensures consistent campaign performance and avoids downtime.
Focus on Conversion Optimization
- Action: Track metrics like purchases, units_sold, and sales for campaigns and refine: Ad copy or offers to boost conversions. Landing pages to reduce friction and improve purchase likelihood.
- Why: Conversion-centric strategies improve overall campaign profitability and ROAS.
Manage Invalid Traffic
- Action: Use metrics like gross_impressions and invalid_impressions (from other related datasets) to identify and reduce invalid traffic.
- Why: Reducing invalid impressions and clicks protects ad spend and ensures a higher share of genuine customer engagement.
A/B Testing
- Action: Test variations in creatives, budgets, or targeting strategies and compare performance metrics (add_to_cart_rate, detail_page_views_clicks, new_to_brand_purchases_rate).
- Why: Continuous testing uncovers strategies that drive better performance over time.
Enhancing Data Analytics with Openbridge
Ditch the messy, manual reporting for the Amazon Advertising Sponsored Brand Campaign Report. Automated data feeds guide data-driven decision-making to improve off-Amazon digital marketing campaigns. Leverage attribution insights to refine strategies, allocate resources efficiently, and enhance customer engagement across all touchpoints.
Openbridge unifies and delivers performance data to leading data lakes and cloud warehouses, including:
- Amazon Redshift
- Google BigQuery
- Snowflake
- Azure Data Lake
- Amazon Athena
- Databricks
This creates an analytics-ready single source of truth, fueling informed decisions on brand strategy, media planning, and understanding customer demand on Amazon. Unified data from Openbridge can turbocharge reporting and analytics tools like:
- Looker Data Studio
- Tableau
- Microsoft Power BI
- Looker
- Amazon QuickSight
- SAP
- Alteryx
- dbt
- Azure Data Factory
- Qlik Sense
Integrating with these platforms can enhance customer engagement across all touchpoints.
Getting Started with Amazon Advertising Campaign Report Automation
Openbridge specializes in delivering unified, analytics-ready data solutions. By providing code-free, fully managed data pipelines, Openbridge helps businesses harness the full potential of their data without the complexities of manual processes.
Get a 30-day free trial to try Amazon Advertising Sponsored Brand Campaign Report automation!
Amazon Advertising Campaign Reports for Sponsored Brands was originally published in Openbridge on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Openbridge - Medium https://ift.tt/Qb0iDTq
via Openbridge
Wednesday, December 11, 2024
Now Available – Second-Generation FPGA-Powered Amazon EC2 instances (F2)
Equipped with up to eight AMD Field-Programmable Gate Arrays (FPGAs), AMD EPYC (Milan) processors with up to 192 cores, High Bandwidth Memory (HBM), up to 8 TiB of SSD-based instance storage, and up to 2 TiB of memory, the new F2 instances are available in two sizes, and are ready to accelerate your genomics, multimedia processing, big data, satellite communication, networking, silicon simulation, and live video workloads.
A Quick FPGA Recap
Here’s how I explained the FPGA model when we previewed the first generation of FPGA-powered Amazon Elastic Compute Cloud (Amazon EC2) instances
One of the more interesting routes to a custom, hardware-based solution is known as a Field Programmable Gate Array, or FPGA. In contrast to a purpose-built chip which is designed with a single function in mind and then hard-wired to implement it, an FPGA is more flexible. It can be programmed in the field, after it has been plugged in to a socket on a PC board. Each FPGA includes a fixed, finite number of simple logic gates. Programming an FPGA is “simply” a matter of connecting them up to create the desired logical functions (AND, OR, XOR, and so forth) or storage elements (flip-flops and shift registers). Unlike a CPU which is essentially serial (with a few parallel elements) and has fixed-size instructions and data paths (typically 32 or 64 bit), the FPGA can be programmed to perform many operations in parallel, and the operations themselves can be of almost any width, large or small.
Since that launch, AWS customers have used F1 instances to host many different types of applications and services. With a newer FPGA, more processing power, and more memory bandwidth, the new F2 instances are an even better host for highly parallelizable, compute-intensive workloads.
Each of the AMD Virtex UltraScale+ HBM VU47P FPGAs has 2.85 million system logic cells and 9,024 DSP slices (up to 28 TOPS of DSP compute performance when processing INT8 values). The FPGA Accelerator Card associated with each F2 instance provides 16 GiB of High Bandwidth Memory and 64 GiB of DDR4 memory per FPGA.
Inside the F2
F2 instances are powered by 3rd generation AMD EPYC (Milan) processors. In comparison to F1 instances, they offer up to 3x as many processor cores, up to twice as much system memory and NVMe storage, and up to 4x the network bandwidth. Each FPGA comes with 16 GiB High Bandwidth Memory (HBM) with up to 460 GiB/s bandwidth. Here are the instance sizes and specs:
| Instance Name | vCPUs |
FPGAs |
FPGA Memory HBM / DDR4 |
Instance Memory |
NVMe Storage |
EBS Bandwidth |
Network Bandwidth |
| f2.12xlarge | 48 | 2 | 32 GiB / 128 GiB |
512 GiB | 1900 GiB (2x 950 GiB) |
15 Gbps | 25 Gbps |
| f2.48xlarge | 192 | 8 | 128 GiB / 512 GiB |
2,048 GiB | 7600 GiB (8x 950 GiB) |
60 Gbps | 100 Gbps |
The high-end f2.48xlarge instance supports the AWS Cloud Digital Interface (CDI) to reliably transport uncompressed live video between applications, with instance-to-instance latency as low as 8 milliseconds.
Building FPGA Applications
The AWS EC2 FPGA Development Kit contains the tools that you will use to develop, simulate, debug, compile, and run your hardware-accelerated FPGA applications. You can launch the kit’s FPGA Developer AMI on a memory-optimized or compute-optimized instance for development and simulation, then use an F2 instance for final debugging and testing.
The tools included in the developer kit support a variety of development paradigms, tools, accelerator languages, and debugging options. Regardless of your choice, you will ultimately create an Amazon FPGA Image (AFI) which contains your custom acceleration logic and the AWS Shell which implements access to the FPGA memory, PCIe bus, interrupts, and external peripherals. You can deploy AFIs to as many F2 instances as desired, share with other AWS accounts or publish on AWS Marketplace.
If you have already created an application that runs on F1 instances, you will need to update your development environment to use the latest AMD tools, then rebuild and validate before upgrading to F2 instances.
FPGA Instances in Action
Here are some cool examples of how F1 and F2 instances can support unique and highly demanding workloads:
Genomics – Multinational pharmaceutical and biotechnology company AstraZeneca used thousands of F1 instances to build the world’s fastest genomics pipeline, able to process over 400K whole genome samples in under two months. They will adopt Illumina DRAGEN for F2 to realize better performance at a lower cost, while accelerating disease discovery, diagnosis, and treatment.
Satellite Communication – Satellite operators are moving from inflexible and expensive physical infrastructure (modulators, demodulators, combiners, splitters, and so forth) toward agile, software-defined, FPGA-powered solutions. Using the digital signal processor (DSP) elements on the FPGA, these solutions can be reconfigured in the field to support new waveforms and to meet changing requirements. Key F2 features such as support for up to 8 FPGAs per instance, generous amounts of network bandwidth, and support for the Data Plan Development Kit (DPDK) using Virtual Ethernet can be used to support processing of multiple, complex waveforms in parallel.
Analytics – NeuroBlade‘s SQL Processing Unit (SPU) integrates with Presto, Apache Spark, and other open source query engines, delivering faster query processing and market-leading query throughput efficiency when run on F2 instances.
Things to Know
Here are a couple of final things that you should know about the F2 instances:
Regions – F2 instances are available today in the US East (N. Virginia) and Europe (London) AWS Regions, with plans to extend availability to additional regions over time.
Operating Systems – F2 instances are Linux-only.
Purchasing Options – F2 instances are available in On-Demand, Spot, Savings Plan, Dedicated Instance, and Dedicated Host form.
— Jeff;
from AWS News Blog https://ift.tt/kZVMqnE
via IFTTT
Wednesday, December 4, 2024
Maximize accelerator utilization for model development with new Amazon SageMaker HyperPod task governance
Today, we’re announcing the general availability of Amazon SageMaker HyperPod task governance, a new innovation to easily and centrally manage and maximize GPU and Trainium utilization across generative AI model development tasks, such as training, fine-tuning, and inference.
Customers tell us that they’re rapidly increasing investment in generative AI projects, but they face challenges in efficiently allocating limited compute resources. The lack of dynamic, centralized governance for resource allocation leads to inefficiencies, with some projects underutilizing resources while others stall. This situation burdens administrators with constant replanning, causes delays for data scientists and developers, and results in untimely delivery of AI innovations and cost overruns due to inefficient use of resources.
With SageMaker HyperPod task governance, you can accelerate time to market for AI innovations while avoiding cost overruns due to underutilized compute resources. With a few steps, administrators can set up quotas governing compute resource allocation based on project budgets and task priorities. Data scientists or developers can create tasks such as model training, fine-tuning, or evaluation, which SageMaker HyperPod automatically schedules and executes within allocated quotas.
SageMaker HyperPod task governance manages resources, automatically freeing up compute from lower-priority tasks when high-priority tasks need immediate attention. It does this by pausing low-priority training tasks, saving checkpoints, and resuming them later when resources become available. Additionally, idle compute within a team’s quota can be automatically used to accelerate another team’s waiting tasks.
Data scientists and developers can continuously monitor their task queues, view pending tasks, and adjust priorities as needed. Administrators can also monitor and audit scheduled tasks and compute resource usage across teams and projects and, as a result, they can adjust allocations to optimize costs and improve resource availability across the organization. This approach promotes timely completion of critical projects while maximizing resource efficiency.
Getting started with SageMaker HyperPod task governance
Task governance is available for Amazon EKS clusters in HyperPod. Find Cluster Management under HyperPod Clusters in the Amazon SageMaker AI console for provisioning and managing clusters. As an administrator, you can streamline the operation and scaling of HyperPod clusters through this console.

When you choose a HyperPod cluster, you can see a new Dashboard, Tasks, and Policies tab in the cluster detail page.
1. New dashboard
In the new dashboard, you can see an overview of cluster utilization, team-based, and task-based metrics.
First, you can view both point-in-time and trend-based metrics for critical compute resources, including GPU, vCPU, and memory utilization, across all instance groups.

Next, you can gain comprehensive insights into team-specific resource management, focusing on GPU utilization versus compute allocation across teams. You can use customizable filters for teams and cluster instance groups to analyze metrics such as allocated GPUs/CPUs for tasks, borrowed GPUs/CPUs, and GPU/CPU utilization.

You can also assess task performance and resource allocation efficiency using metrics such as counts of running, pending, and preempted tasks, as well as average task runtime and wait time. To gain comprehensive observability into your SageMaker HyperPod cluster resources and software components, you can integrate with Amazon CloudWatch Container Insights or Amazon Managed Grafana.

2. Create and manage a cluster policy
To enable task prioritization and fair-share resource allocation, you can configure a cluster policy that prioritizes critical workloads and distributes idle compute across teams defined in compute allocations.

To configure priority classes and fair sharing of borrowed compute in cluster settings, choose Edit in the Cluster policy section.
You can define how tasks waiting in queue are admitted for task prioritization: First-come-first-serve by default or Task ranking. When you choose task ranking, tasks waiting in queue will be admitted in the priority order defined in this cluster policy. Tasks of same priority class will be executed on a first-come-first-serve basis.
You can also configure how idle compute is allocated across teams: First-come-first-serve or Fair-share by default. The fair-share setting enables teams to borrow idle compute based on their assigned weights, which are configured in relative compute allocations. This enables every team to get a fair share of idle compute to accelerate their waiting tasks.

In the Compute allocation section of the Policies page, you can create and edit compute allocations to distribute compute resources among teams, enable settings that allow teams to lend and borrow idle compute, configure preemption of their own low-priority tasks, and assign fair-share weights to teams.
In the Team section, set a team name and a corresponding Kubernetes namespace will be created for your data science and machine learning (ML) teams to use. You can set a fair-share weight for a more equitable distribution of unused capacity across your teams and enable the preemption option based on task priority, allowing higher-priority tasks to preempt lower-priority ones.
In the Compute section, you can add and allocate instance type quotas to teams. Additionally, you can allocate quotas for instance types not yet available in the cluster, allowing for future expansion.

You can enable teams to share idle compute resources by allowing them to lend their unused capacity to other teams. This borrowing model is reciprocal: teams can only borrow idle compute if they are also willing to share their own unused resources with others. You can also specify the borrow limit that enables teams to borrow compute resources over their allocated quota.
3. Run your training task in SageMaker HyperPod cluster
As a data scientist, you can submit a training job and use the quota allocated for your team, using the HyperPod Command Line Interface (CLI) command. With the HyperPod CLI, you can start a job and specify the corresponding namespace that has the allocation.
$ hyperpod start-job --name smpv2-llama2 --namespace hyperpod-ns-ml-engineers
Successfully created job smpv2-llama2
$ hyperpod list-jobs --all-namespaces
{
"jobs": [
{
"Name": "smpv2-llama2",
"Namespace": "hyperpod-ns-ml-engineers",
"CreationTime": "2024-09-26T07:13:06Z",
"State": "Running",
"Priority": "fine-tuning-priority"
},
...
]
}In the Tasks tab, you can see all tasks in your cluster. Each task has different priority and capacity need according to its policy. If you run another task with higher priority, the existing task will be suspended and that task can run first.

OK, now let’s check out a demo video showing what happens when a high-priority training task is added while running a low-priority task.
To learn more, visit SageMaker HyperPod task governance in the Amazon SageMaker AI Developer Guide.
Now available
Amazon SageMaker HyperPod task governance is now available in US East (N. Virginia), US East (Ohio), US West (Oregon) AWS Regions. You can use HyperPod task governance without additional cost. To learn more, visit the SageMaker HyperPod product page.
Give HyperPod task governance a try in the Amazon SageMaker AI console and send feedback to AWS re:Post for SageMaker or through your usual AWS Support contacts.
— Channy
P.S. Special thanks to Nisha Nadkarni, a senior generative AI specialist solutions architect at AWS for her contribution in creating a HyperPod testing environment.
from AWS News Blog https://ift.tt/HO7C1cu
via IFTTT
Tuesday, December 3, 2024
Introducing queryable object metadata for Amazon S3 buckets (preview)
 AWS customers make use of Amazon Simple Storage Service (Amazon S3) at an incredible scale, regularly creating individual buckets that contain billions or trillions of objects! At that scale, finding the objects which meet particular criteria — objects with keys that match a pattern, objects of a particular size, or objects with a specific tag — becomes challenging. Our customers have had to build systems that capture, store, and query for this information. These systems can become complex and hard to scale, and can fall out of sync with the actual state of the bucket and the objects within.
AWS customers make use of Amazon Simple Storage Service (Amazon S3) at an incredible scale, regularly creating individual buckets that contain billions or trillions of objects! At that scale, finding the objects which meet particular criteria — objects with keys that match a pattern, objects of a particular size, or objects with a specific tag — becomes challenging. Our customers have had to build systems that capture, store, and query for this information. These systems can become complex and hard to scale, and can fall out of sync with the actual state of the bucket and the objects within.
Rich Metadata
Today we are enabling in preview automatic generation of metadata that is captured when S3 objects are added or modified, and stored in fully managed Apache Iceberg tables. This allows you to use Iceberg-compatible tools such as Amazon Athena, Amazon Redshift, Amazon QuickSight, and Apache Spark to easily and efficiently query the metadata (and find the objects of interest) at any scale. As a result, you can quickly find the data that you need for your analytics, data processing, and AI training workloads.
For video inference responses stored in S3, Amazon Bedrock will annotate the content it generates with metadata that will allow you to identify the content as AI-generated, and to know which model was used to generate it.
The metadata schema contains over 20 elements including the bucket name, object key, creation/modification time, storage class, encryption status, tags, and user metadata. You can also store additional, application-specific descriptive information in a separate table and then join it with the metadata table as part of your query.
How it Works
You can enable capture of rich metadata for any of your S3 buckets by specifying the location (an S3 table bucket and a table name) where you want the metadata to be stored. Capture of updates (object creations, object deletions, and changes to object metadata) begins right away and will be stored in the table within minutes. Each update generates a new row in the table, with a record type (CREATE, UPDATE_METADATA, or DELETE) and a sequence number. You can retrieve the historical record for a given object by running a query that orders the results by sequence number.
Enabling and Querying Metadata
I start by creating a table bucket for my metadata using the create-table-bucket command (this can also be done from the AWS Management Console or with an API call):
Then I specify the table bucket (by ARN) and the desired table name by putting this JSON into a file (I’ll call it config.json):
And then I attach this configuration to my data bucket (the one that I want to capture metadata for):
For testing purposes I installed Apache Spark on an EC2 instance and after a little bit of setup I was able to run queries by referencing the Amazon S3 Tables Catalog for Apache Iceberg package and adding the metadata table (as mytablebucket) to the command line:
Here is the current schema for the Iceberg table:
Here’s a simple query that shows some of the metadata for the ten most recent updates:
In a real-world situation I would query the table using one of the AWS or open source analytics tools that I mentioned earlier.
Console Access
I can also set up and manage the metadata configuration for my buckets using the Amazon S3 Console by clicking the Metadata tab:

Available Now
Amazon S3 Metadata is available in preview now and you can start using it today in the US East (Ohio, N. Virginia) and US West (Oregon) AWS Regions.
Integration with AWS Glue Data Catalog is in preview, allowing you to query and visualize data—including S3 Metadata tables—using AWS Analytics services such as Amazon Athena, Amazon Redshift, Amazon EMR, and Amazon QuickSight.
Pricing is based on the number updates (object creations, object deletions, and changes to object metadata) with an additional charge for storage of the metadata table. For more pricing information, visit the S3 Pricing page.
I’m confident that you will be able to make use of this metadata in many powerful ways, and am looking forward to hearing about your use cases. Let me know what you think!
— Jeff;
from AWS News Blog https://ift.tt/tOzC2Qx
via IFTTT
Amazon EC2 Trn2 Instances and Trn2 UltraServers for AI/ML training and inference are now available
The new Amazon Elastic Compute Cloud (Amazon EC2) Trn2 instances and Trn2 UltraServers are the most powerful EC2 compute options for ML training and inference. Powered by the second generation of AWS Trainium chips (AWS Trainium2), the Trn2 instances are 4x faster, offer 4x more memory bandwidth, and 3x more memory capacity than the first-generation Trn1 instances. Trn2 instances offer 30-40% better price performance than the current generation of GPU-based EC2 P5e and P5en instances.
In addition to the 16 Trainium2 chips, each Trn2 instance features 192 vCPUs, 2 TiB of memory, and 3.2 Tbps of Elastic Fabric Adapter (EFA) v3 network bandwidth, which offers up to 50% lower latency than the previous generation.
The Trn2 UltraServers, which are a completely new compute offering, feature 64x Trainium2 chips connected with a high-bandwidth, low-latency NeuronLink interconnect, for peak inference and training performance on frontier foundation models.
Tens of thousands of Trainium chips are already powering Amazon and AWS services. For example, over 80,000 AWS Inferentia and Trainium1 chips supported the Rufus shopping assistant on the most recent Prime Day. Trainium2 chips are already powering the latency-optimized versions of Llama 3.1 405B and Claude 3.5 Haiku models on Amazon Bedrock.
Up and Out and Up
Sustained growth in the size and complexity of the frontier models is enabled by innovative forms of compute power, assembled into equally innovative architectural forms. In simpler times we could talk about architecting for scalability in two ways: scaling up (using a bigger computer) and scaling out (using more computers). Today, when I look at the Trainium2 chip, the Trn2 instance, and the even larger compute offerings that I will talk about in a minute, it seems like both models apply, but at different levels of the overall hierarchy. Let’s review the Trn2 building blocks, starting at the NeuronCore and scaling to an UltraCluster:
 NeuronCores are at the heart of the Trainium2 chip. Each third-generation NeuronCore includes a scalar engine (1 input to 1 output), a vector engine (multiple inputs to multiple outputs), a tensor engine (systolic array multiplication, convolution, and transposition), and a GPSIMD (general purpose single instruction multiple data) core.
NeuronCores are at the heart of the Trainium2 chip. Each third-generation NeuronCore includes a scalar engine (1 input to 1 output), a vector engine (multiple inputs to multiple outputs), a tensor engine (systolic array multiplication, convolution, and transposition), and a GPSIMD (general purpose single instruction multiple data) core.
Each Trainium2 chip is home to eight NeuronCores and 96 GiB of High Bandwidth Memory (HBM), and supports 2.9 TB/second of HBM bandwidth. The cores can be addressed and used individually, or pairs of physical cores can be grouped into a single logical core. A single Trainium2 chip delivers up to 1.3 petaflops of dense FP8 compute and up to 5.2 petaflops of sparse FP8 compute, and can drive 95% utilization of memory bandwidth thanks to automated reordering of the HBM queue.
Each Trn2 instance is, in turn, home to 16 Trainum2 chips. That’s a total of 128 NeuronCores, 1.5 TiB of HBM, and 46 TB/second of HBM bandwidth. Altogether this multiplies out to up to 20.8 petaflops of dense FP8 compute and up to 83.2 petaflops of sparse FP8 compute. The Trainium2 chips are connected across NeuronLink in a 2D torus for high bandwidth, low latency chip-to-chip communication at 1 GB/second.
An UltraServer is home to four Trn2 instances connected with low-latency, high-bandwidth NeuronLink. That’s 512 NeuronCores, 64 Trainium2 chips, 6 TiB of HBM, and 185 TB/second of HBM bandwidth. Doing the math, this results in up to 83 petaflops of dense FP compute and up to 332 petaflops of sparse FP8 compute. In addition to the 2D torus that connects NeuronCores within an instance, Cores at corresponding XY positions in each of the four instances are connected in a ring. For inference, UltraServers help deliver industry-leading response time to create the best real-time experiences. For training, UltraServers boost model training speed and efficiency with faster collective communication for model parallelism when compared to standalone instances. UltraServers are designed to support training and inference at the trillion parameter level and beyond; they are available in preview form and you can contact us to join the preview.
Trn2 instances and UltraServers are being deployed in EC2 UltraClusters to enable scale-out distributed training across tens of thousands of Trainium chips on a single petabit scale, non-blocking network, with access to Amazon FSx for Lustre high performance storage.
Using Trn2 Instances
Trn2 instances are available today for production use in the US East (Ohio) AWS Region and can be reserved by using Amazon EC2 Capacity Blocks for ML. You can reserve up to 64 instances for up to six months, with reservations accepted up to eight weeks in advance, with instant start times and the ability to extend your reservations if needed. To learn more, read Announcing Amazon EC2 Capacity Blocks for ML to reserve GPU capacity for your machine learning workloads.
On the software side, you can start with the AWS Deep Learning AMIs. These images are preconfigured with the frameworks and tools that you probably already know and use: PyTorch, JAX, and a lot more.
If you used the AWS Neuron SDK to build your apps, you can bring them over and recompile them for use on Trn2 instances. This SDK integrates natively with JAX, PyTorch, and essential libraries like Hugging Face, PyTorch Lightning, and NeMo. Neuron includes out-of-the-box optimizations for distributed training and inference with the open source PyTorch libraries NxD Training and NxD Inference, while providing deep insights for profiling and debugging. Neuron also supports OpenXLA, including stable HLO and GSPMD, enabling PyTorch/XLA and JAX developers to utilize Neuron’s compiler optimizations for Trainium2.
— Jeff;
from AWS News Blog https://ift.tt/fne17qJ
via IFTTT
Monday, December 2, 2024
New Amazon EC2 P5en instances with NVIDIA H200 Tensor Core GPUs and EFAv3 networking
Today, we’re announcing the general availability of Amazon Elastic Compute Cloud (Amazon EC2) P5en instances, powered by NVIDIA H200 Tensor Core GPUs and custom 4th generation Intel Xeon Scalable processors with an all-core turbo frequency of 3.2 GHz (max core turbo frequency of 3.8 GHz) available only on AWS. These processors offer 50 percent higher memory bandwidth and up to four times throughput between CPU and GPU with PCIe Gen5, which help boost performance for machine learning (ML) training and inference workloads.
P5en, with up to 3200 Gbps of third generation of Elastic Fabric Adapter (EFAv3) using Nitro v5, shows up to 35% improvement in latency compared to P5 that uses the previous generation of EFA and Nitro. This helps improve collective communications performance for distributed training workloads such as deep learning, generative AI, real-time data processing, and high-performance computing (HPC) applications.
Here are the specs for P5en instances:
| Instance size | vCPUs | Memory (GiB) | GPUs (H200) | Network bandwidth (Gbps) | GPU Peer to peer (GB/s) | Instance storage (TB) | EBS bandwidth (Gbps) |
| p5en.48xlarge | 192 | 2048 | 8 | 3200 | 900 | 8 x 3.84 | 100 |
On September 9, we introduced Amazon EC2 P5e instances, powered by 8 NVIDIA H200 GPUs with 1128 GB of high bandwidth GPU memory, 3rd Gen AMD EPYC processors, 2 TiB of system memory, and 30 TB of local NVMe storage. These instances provide up to 3,200 Gbps of aggregate network bandwidth with EFAv2 and support GPUDirect RDMA, enabling lower latency and efficient scale-out performance by bypassing the CPU for internode communication.
With P5en instances, you can increase the overall efficiency in a wide range of GPU-accelerated applications by further reducing the inference and network latency. P5en instances increases local storage performance by up to two times and Amazon Elastic Block Store (Amazon EBS) bandwidth by up to 25 percent compared with P5 instances, which will further improve inference latency performance for those of you who are using local storage for caching model weights.
The transfer of data between CPUs and GPUs can be time-consuming, especially for large datasets or workloads that require frequent data exchanges. With PCIe Gen 5 providing up to four times bandwidth between CPU and GPU compared with P5eand P5e instances, you can further improve latency for model training, fine-tuning, and running inference for complex large language models (LLMs) and multimodal foundation models (FMs), and memory-intensive HPC applications such as simulations, pharmaceutical discovery, weather forecasting, and financial modeling.
Getting started with Amazon EC2 P5en instances
You can use EC2 P5en instances available in the US East (Ohio), US West (Oregon), and Asia Pacific (Tokyo) AWS Regions through EC2 Capacity Blocks for ML, On Demand, and Savings Plan purchase options.
I want to introduce how to use P5en instances with Capacity Reservation as an option. To reserve your EC2 Capacity Blocks, choose Capacity Reservations on the Amazon EC2 console in the US East (Ohio) AWS Region.
Select Purchase Capacity Blocks for ML and then choose your total capacity and specify how long you need the EC2 Capacity Block for p5en.48xlarge instances. The total number of days that you can reserve EC2 Capacity Blocks is 1–14, 21, or 28 days. EC2 Capacity Blocks can be purchased up to 8 weeks in advance.

When you select Find Capacity Blocks, AWS returns the lowest-priced offering available that meets your specifications in the date range you have specified. After reviewing EC2 Capacity Blocks details, tags, and total price information, choose Purchase.
Now, your EC2 Capacity Block will be scheduled successfully. The total price of an EC2 Capacity Block is charged up front, and the price does not change after purchase. The payment will be billed to your account within 12 hours after you purchase the EC2 Capacity Blocks. To learn more, visit Capacity Blocks for ML in the Amazon EC2 User Guide.
To run instances within your purchased Capacity Block, you can use AWS Management Console, AWS Command Line Interface (AWS CLI) or AWS SDKs.
Here is a sample AWS CLI command to run 16 P5en instances to maximize EFAv3 benefits. This configuration provides up to 3200 Gbps of EFA networking bandwidth and up to 800 Gbps of IP networking bandwidth with eight private IP address:
$ aws ec2 run-instances --image-id ami-abc12345 \
--instance-type p5en.48xlarge \
--count 16 \
--key-name MyKeyPair \
--instance-market-options MarketType='capacity-block' \
--capacity-reservation-specification CapacityReservationTarget={CapacityReservationId=cr-a1234567}
--network-interfaces "NetworkCardIndex=0,DeviceIndex=0,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa" \
"NetworkCardIndex=1,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=2,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=3,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=4,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa" \
"NetworkCardIndex=5,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=6,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=7,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=8,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa" \
"NetworkCardIndex=9,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=10,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=11,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=12,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa" \
"NetworkCardIndex=13,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=14,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=15,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=16,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa" \
"NetworkCardIndex=17,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=18,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=19,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=20,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa" \
"NetworkCardIndex=21,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=22,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=23,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=24,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa" \
"NetworkCardIndex=25,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=26,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=27,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=28,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa" \
"NetworkCardIndex=29,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=30,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only" \
"NetworkCardIndex=31,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
...
When launching P5en instances, you can use AWS Deep Learning AMIs (DLAMI) to support EC2 P5en instances. DLAMI provides ML practitioners and researchers with the infrastructure and tools to quickly build scalable, secure, distributed ML applications in preconfigured environments.
You can run containerized ML applications on P5en instances with AWS Deep Learning Containers using libraries for Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS).
For fast access to large datasets, you can use up to 30 TB of local NVMe SSD storage or virtually unlimited cost-effective storage with Amazon Simple Storage Service (Amazon S3). You can also use Amazon FSx for Lustre file systems in P5en instances so you can access data at the hundreds of GB/s of throughput and millions of input/output operations per second (IOPS) required for large-scale deep learning and HPC workloads.
Now available
Amazon EC2 P5en instances are available today in the US East (Ohio), US West (Oregon), and Asia Pacific (Tokyo) AWS Regions and US East (Atlanta) Local Zone us-east-1-atl-2a through EC2 Capacity Blocks for ML, On Demand, and Savings Plan purchase options. For more information, visit the Amazon EC2 pricing page.
Give Amazon EC2 P5en instances a try in the Amazon EC2 console. To learn more, see Amazon EC2 P5 instance page and send feedback to AWS re:Post for EC2 or through your usual AWS Support contacts.
— Channy
from AWS News Blog https://ift.tt/YceWbGi
via IFTTT
Sunday, December 1, 2024
Top announcements of AWS re:Invent 2024
AWS re:Invent 2024, our flagship an nual conference, is taking place Dec. 2-6, 2024, in Las Vegas. This premier cloud computing event brings together the global cloud computing community for a week of keynotes, technical sessions, product launches, and networking opportunities. As AWS continues to unveil its latest innovations and services throughout the conference, we’ll keep you updated here with all the major product announcements.
nual conference, is taking place Dec. 2-6, 2024, in Las Vegas. This premier cloud computing event brings together the global cloud computing community for a week of keynotes, technical sessions, product launches, and networking opportunities. As AWS continues to unveil its latest innovations and services throughout the conference, we’ll keep you updated here with all the major product announcements.
Additional re:Invent resources:
- AWS News Blog: Chief Evangelist Jeff Barr and colleagues keep you posted on the biggest and best new AWS offerings.
- What’s New with AWS: A comprehensive list of all AWS launches.
- The Official AWS Podcast: A podcast for developers and IT professionals looking for the latest news and trends from AWS.
- AWS On Air: Live-streamed announcements and hands-on demos.
- AWS re:Post: Join the community in conversation through Q&A.
(This post was last updated: 9:08 p.m. PST, Dec. 1, 2024.)
Quick category links:
Analytics | Application Integration | Business Applications | Compute | Containers | Database | Generative AI / Machine Learning | Management & Governance | Migration & Transfer Services | Security, Identity, & Compliance | Storage
Analytics
AWS Clean Rooms now supports multiple clouds and data sources
With expanded data sources, AWS Clean Rooms helps customers securely collaborate with their partners’ data across clouds, eliminating data movement, safeguarding sensitive information, promoting data freshness, and streamlining cross-company insights.
Application Integration
Securely share AWS resources across VPC and account boundaries with PrivateLink, VPC Lattice, EventBridge, and Step Functions
Orchestrate hybrid workflows accessing private HTTPS endpoints – no more Lambda/SQS workarounds. EventBridge and Step Functions natively support private resources, simplifying cloud modernization.
Orchestrate hybrid workflows accessing private HTTPS endpoints – no more Lambda/SQS workarounds. EventBridge and Step Functions natively support private resources, simplifying cloud modernization.
Business Applications
Newly enhanced Amazon Connect adds generative AI, WhatsApp Business, and secure data collection
Use innovative tools like generative AI for segmentation and campaigns, WhatsApp Business, data privacy controls for chat, AI guardrails, conversational AI bot management, and enhanced analytics to elevate customer experiences securely and efficiently.
Compute
Introducing storage optimized Amazon EC2 I8g instances powered by AWS Graviton4 processors and 3rd gen AWS Nitro SSDs
Elevate storage performance with AWS’s newest I8g instances, which deliver unparalleled speed and efficiency for I/O-intensive workloads.
Now available: Storage optimized Amazon EC2 I7ie instances
New AWS I7ie instances deliver unbeatable storage performance: up to 120TB NVMe, 40% better compute performance and up to 65% better real-time storage performance.
Containers
Use your on-premises infrastructure in Amazon EKS clusters with Amazon EKS Hybrid Nodes
Unify Kubernetes management across your cloud and on-premises environments with Amazon EKS Hybrid Nodes – use existing hardware while offloading control plane responsibilities to EKS for consistent operations.
Streamline Kubernetes cluster management with new Amazon EKS Auto Mode
With EKS Auto Mode, AWS simplifies Kubernetes cluster management, automating compute, storage, and networking, enabling higher agility and performance while reducing operational overhead.
Database
Amazon MemoryDB Multi-Region is now generally available
Build highly available, globally distributed apps with microsecond latencies across Regions, automatic conflict resolution, and up to 99.999% availability.
Generative AI / Machine Learning
New RAG evaluation and LLM-as-a-judge capabilities in Amazon Bedrock
Evaluate AI models and applications efficiently with Amazon Bedrock’s new LLM-as-a-judge capability for model evaluation and RAG evaluation for Knowledge Bases, offering a variety of quality and responsible AI metrics at scale.
Enhance your productivity with new extensions and integrations in Amazon Q Business
Seamlessly access AI assistance within work applications with Amazon Q Business’s new browser extensions and integrations.
New APIs in Amazon Bedrock to enhance RAG applications, now available
With custom connectors and reranking models, you can enhance RAG applications by enabling direct ingestion to knowledge bases without requiring a full sync, and improving response relevance through advanced reranking models.
Introducing new PartyRock capabilities and free daily usage
Unleash your creativity with PartyRock’s new AI capabilities: generate images, analyze visuals, search hundreds of thousands of apps, and process multiple docs simultaneously – no coding required.
Users can now query information embedded in various types of visuals, including diagrams, infographics, charts, and other image-based content.
Management & Governance
Container Insights with enhanced observability now available in Amazon ECS
With granular visibility into container workloads, CloudWatch Container Insights with enhanced observability for Amazon ECS enables proactive monitoring and faster troubleshooting, enhancing observability and improving application performance.
New Amazon CloudWatch Database Insights: Comprehensive database observability from fleets to instances
Monitor Amazon Aurora databases and gain comprehensive visibility into MySQL and PostgreSQL fleets and instances, analyze performance bottlenecks, track slow queries, set SLOs, and explore rich telemetry.
New Amazon CloudWatch and Amazon OpenSearch Service launch an integrated analytics experience
Unlock out-of-the-box OpenSearch dashboards and two additional query languages, OpenSearch SQL and PPL, for analyzing CloudWatch logs. OpenSearch customers can now analyze CloudWatch Logs without having to duplicate data.
Migration & Transfer Services
AWS Database Migration Service now automates time-intensive schema conversion tasks using generative AI
AWS DMS Schema Conversion converts up to 90% of your schema to accelerate your database migrations and reduce manual effort with the power of generative AI.
Announcing AWS Transfer Family web apps for fully managed Amazon S3 file transfers
AWS Transfer Family web apps are a new resource that you can use to create a simple interface for authorized line-of-business users to access data in Amazon S3 through a customizable web browser.
Introducing default data integrity protections for new objects in Amazon S3
Amazon S3 updates the default behavior of object upload requests with new data integrity protections that build upon S3’s existing durability posture.
Security, Identity, & Compliance
New AWS Security Incident Response helps organizations respond to and recover from security events
AWS introduces a new service to streamline security event response, providing automated triage, coordinated communication, and expert guidance to recover from cybersecurity threats.
Introducing Amazon GuardDuty Extended Threat Detection: AI/ML attack sequence identification for enhanced cloud security
AWS extends GuardDuty with AI/ML capabilities to detect complex attack sequences across workloads, applications, and data, correlating multiple security signals over time for proactive cloud security.
Simplify governance with declarative policies
With only a few steps, create declarative policies and enforce desired configuration for AWS services across your organization, reducing ongoing governance overhead and providing transparency for administrators and end users.
AWS Verified Access now supports secure access to resources over non-HTTP(S) protocols (preview)
With only a few steps, create declarative policies and enforce desired configuration for AWS services across your organization, reducing ongoing governance overhead and providing transparency for administrators and end users.
Introducing Amazon OpenSearch Service and Amazon Security Lake integration to simplify security analytics
Analyze security logs without data duplication; Amazon OpenSearch Service now offers zero-ETL integration with Amazon Security Lake for efficient threat hunting and investigations.
Storage
Announcing Amazon FSx Intelligent-Tiering, a new storage class for FSx for OpenZFS
Delivering NAS capabilities with automatic data tiering among frequently accessed, infrequent, and archival storage tiers, Amazon FSx Intelligent-Tiering offers high performance up to 400K IOPS, 20 GB/s throughput, seamless integration with AWS services.
New physical AWS Data Transfer Terminals let you upload to the cloud faster
Rapidly upload large datasets to AWS at blazing speeds with the new AWS Data Transfer Terminal, secure physical locations offering high throughput connection.
Connect users to data through your apps with Storage Browser for Amazon S3
Storage Browser for Amazon S3 is an open source interface component that you can add to your web applications to provide your authorized end users, such as customers, partners, and employees, with access to easily browse, upload, download, copy, and delete data in S3.
from AWS News Blog https://ift.tt/VDip0Fw
via IFTTT
Subscribe to:
Comments (Atom)